



Apache Beam 概觀
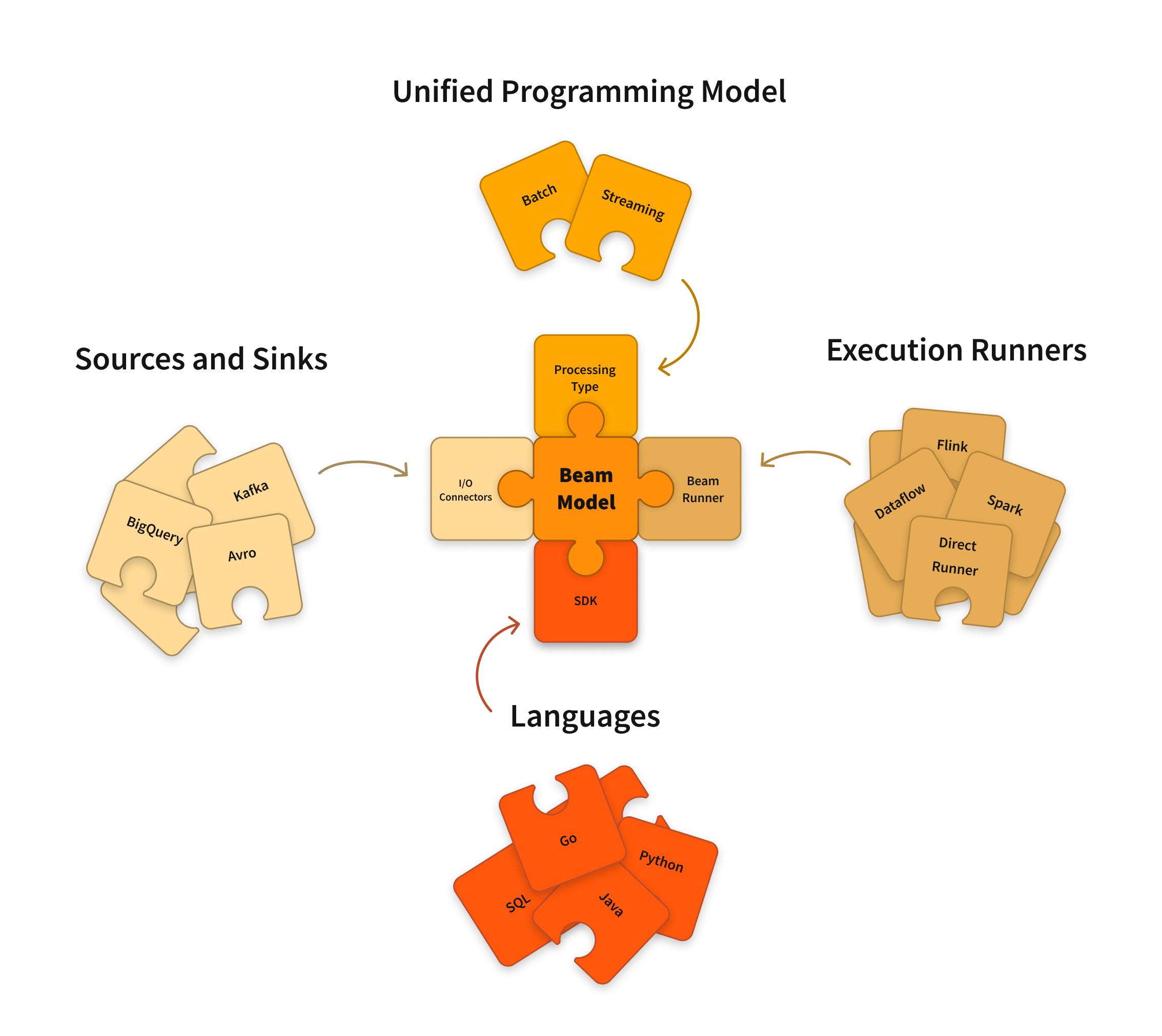
Apache Beam 是一個開放原始碼、統一的模型,用於定義批次和串流資料並行處理管道。您可以使用其中一個開放原始碼 Beam SDK 來建構定義管道的程式。然後,管道會由 Beam 支援的分散式處理後端之一執行,其中包括 Apache Flink、Apache Spark 和 Google Cloud Dataflow。
Beam 特別適用於非常適合並行處理的資料處理任務,其中問題可以分解為許多較小的資料包,這些資料包可以獨立且並行地處理。您也可以將 Beam 用於提取、轉換和載入 (ETL) 任務以及純粹的資料整合。這些任務對於在不同儲存媒體和資料來源之間移動資料、將資料轉換為更理想的格式,或將資料載入新系統非常有用。
Apache Beam SDK
Beam SDK 提供了一個統一的程式設計模型,可以表示和轉換任何大小的資料集,無論輸入是來自批次資料來源的有限資料集,還是來自串流資料來源的無限資料集。Beam SDK 使用相同的類別來表示有界和無界資料,並使用相同的轉換來處理這些資料。您可以使用您選擇的 Beam SDK 來建構一個程式,該程式會定義您的資料處理管道。
Beam 目前支援以下特定語言的 SDK



Scala  介面也以 Scio 的形式提供。
介面也以 Scio 的形式提供。
Apache Beam 管道執行器
Beam 管道執行器會將您使用 Beam 程式定義的資料處理管道轉換為與您選擇的分散式處理後端相容的 API。當您執行 Beam 程式時,您需要為您想要執行管道的後端指定一個適當的執行器。
Beam 目前支援以下執行器
- 直接執行器
- Apache Flink 執行器

- Apache Nemo 執行器
- Apache Samza 執行器

- Apache Spark 執行器

- Google Cloud Dataflow 執行器

- Hazelcast Jet 執行器

- Twister2 執行器

注意:您隨時可以在本機執行管道以進行測試和除錯。
開始使用
開始使用 Beam 來處理您的資料處理任務。
如果您已經熟悉 Apache Spark,請查看我們的從 Apache Spark 開始使用頁面。
以線上互動式學習體驗的方式參加 Beam 導覽。
依照 Java SDK、Python SDK 或 Go SDK 的快速入門指南進行操作。
請參閱 WordCount 範例演練,以取得介紹 SDK 各種功能的範例。
瀏覽我們的學習資源,以進行自學導覽。
深入探討文件章節,以取得有關 Beam 模型、SDK 和執行器的深入概念和參考資料。
深入探討食譜範例,以了解如何在 Dataflow 上執行 Beam。
貢獻
Beam 是一個 Apache 軟體基金會專案,並在 Apache v2 授權下提供。Beam 是一個開放原始碼社群,非常感謝您的貢獻!如果您想要貢獻,請參閱貢獻章節。
上次更新日期:2024/10/31
您是否找到您要找的所有內容?
這些內容是否都有用且清晰?您是否想變更任何內容?請告訴我們!