




「Apache Beam 是一個定義完善的資料處理模型,讓您可以專注於業務邏輯,而不是分散式處理的底層細節。」

搜尋引擎工作負載的可擴展性和成本優化
背景
Seznam.cz 是一個捷克搜尋引擎,佔據當地超過 25% 的自然搜尋流量。Seznam 聘用超過 1,500 名員工,經營超過 30 項網路服務和相關品牌,每天處理約 1500 萬個查詢。
Seznam 不斷優化其大數據基礎設施、網路爬蟲、演算法和機器學習模型,以期為使用者實現搜尋結果的準確性、品質和實用性。Seznam 一直是 Apache Beam 的早期貢獻者和採用者,他們將多個 PB 級的工作負載遷移到在 Seznam 內部資料中心的 Apache Spark 和 Apache Flink 叢集中運行的 Apache Beam 管線。
邁向 Apache Beam 之旅
早在 2010 年,Seznam 就開始在 Hadoop Yarn 叢集中使用 MapReduce,以促進其搜尋引擎網路爬蟲組件的並行批次處理作業。在幾年內,他們的資料基礎設施發展到 超過 400 億行和 400 TB 的 HBase、2 個內部資料中心,擁有超過 1,100 個裸機伺服器、13 PB 的儲存空間和 50 TB 的記憶體,這使得他們的業務邏輯更加複雜。MapReduce 不再提供足夠的彈性、成本效益和效能來支援這種成長,因此 Seznam 將作業重寫為原生 Spark。Spark shuffle 操作使 Seznam 能夠將大型資料鍵分割成多個分割區,一次一個地將它們載入記憶體中並迭代地處理它們。然而,指數級的資料傾斜和無法將單一鍵的所有值放入記憶體緩衝區,導致了 磁碟空間利用率和記憶體額外負荷的增加。某些任務需要異常長的時間才能完成,並且由於一般性的例外狀況,除錯 Spark 管線非常具有挑戰性。因此,Seznam 需要一個可以更有效率地擴展的資料處理框架。
為了管理這種規模,您需要抽象化。
在 2014 年,Seznam 開始開發 Euphoria API,這是一種專有的程式設計模型,可以表示批次和串流管線中的業務邏輯,並允許與執行器無關的實作。
Apache Beam 於 2016 年發布,並成為一個現成的且定義完善的統一程式設計模型。這個與引擎無關的模型發展非常快速,支援多個 shuffle 操作器,並且完美地融入 Seznam 現有的內部資料基礎設施。有一段時間,Seznam 繼續開發 Euphoria,但很快,維護該解決方案和在內部建立自己的執行器所需的高成本和工作量,超過了擁有專有框架的好處。

Seznam 開始將其主要工作負載遷移到 Apache Beam。他們決定將 Euphoria API 合併為 Apache Beam Java SDK 的高階 DSL。對 Apache Beam 的這項重大貢獻是 Seznam 積極參與社群的起點,後來在 2019 年的 Beam Summit Europe 和開發人員會議上展示了他們獨特的經驗和發現。
採用 Apache Beam
Apache Beam 使 Seznam 能夠更快地執行批次和串流作業,而無需增加記憶體和磁碟空間,從而最大化可擴展性、效能和效率。
Apache Beam 提供了多種方法來均勻地分配傾斜的資料。Windowing 用於處理無界限和 Partition 用於處理有界限資料集,將輸入轉換為可以重新 shuffle 的有限元素集合。Apache Beam 提供基於位元組的 shuffle,可以由 Spark 執行器或 Flink 執行器執行,而無需 Apache Spark 或 Apache Flink 來反序列化完整的鍵。Apache Beam SDK 提供有效的編碼器來序列化和反序列化元素並傳遞給分散式工作人員。使用 Apache Beam 序列化和基於位元組的 shuffle 為 Seznam 的許多用例帶來了顯著的效能提升,並減少了 Apache Spark 執行環境所需的記憶體。Seznam 與 磁碟 I/O 和記憶體分割相關的基礎設施成本顯著降低。
其中一個最有價值的用例是 Seznam 的 LinkRevert 作業,該作業會分析網路圖以提高搜尋相關性。這個資料管線形象地「將網際網路顛倒過來」,每天處理超過 150 TB 的資料,擴展重新導向鏈以識別特定 URL 的每個後繼者,並發現指向特定網頁的反向連結。Apache Beam 管線執行多個大規模的傾斜聯結,並根據重新導向和反向連結因素對搜尋結果的 URL 進行評分。
Apache Beam 允許統一且與引擎無關的執行,因此 Seznam 能夠根據用例在 Spark 或 Flink 執行器之間進行選擇。例如,由 Hadoop Yarn 叢集上的 Spark 執行器執行的 Apache Beam 批次管線會剖析新的網路文件,使用其他功能豐富資料,並根據網頁的相關性對其進行評分,以確保及時的資料庫更新和準確的搜尋結果。Apache Beam 串流處理在 Kubernetes 叢集上的 Apache Flink 執行環境中執行,用於顯示在使用者搜尋結果中的縮圖請求。另一個串流事件處理的範例是 Apache Beam Flink 執行器管線,該管線會對搜尋記錄進行對應、聯結和處理,以計算 SLO 指標和其他功能。
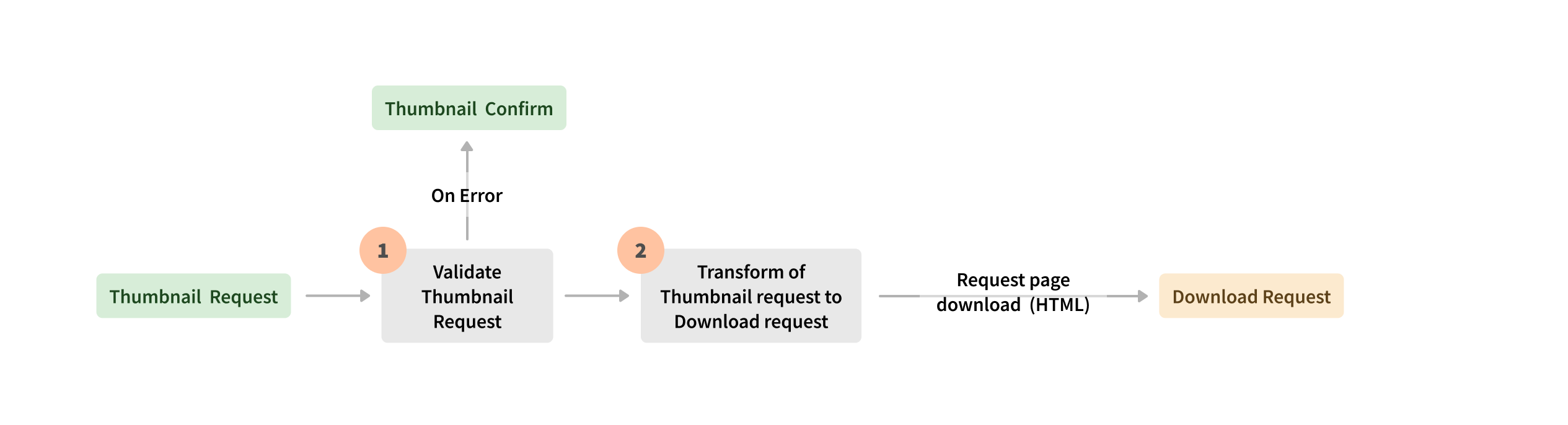
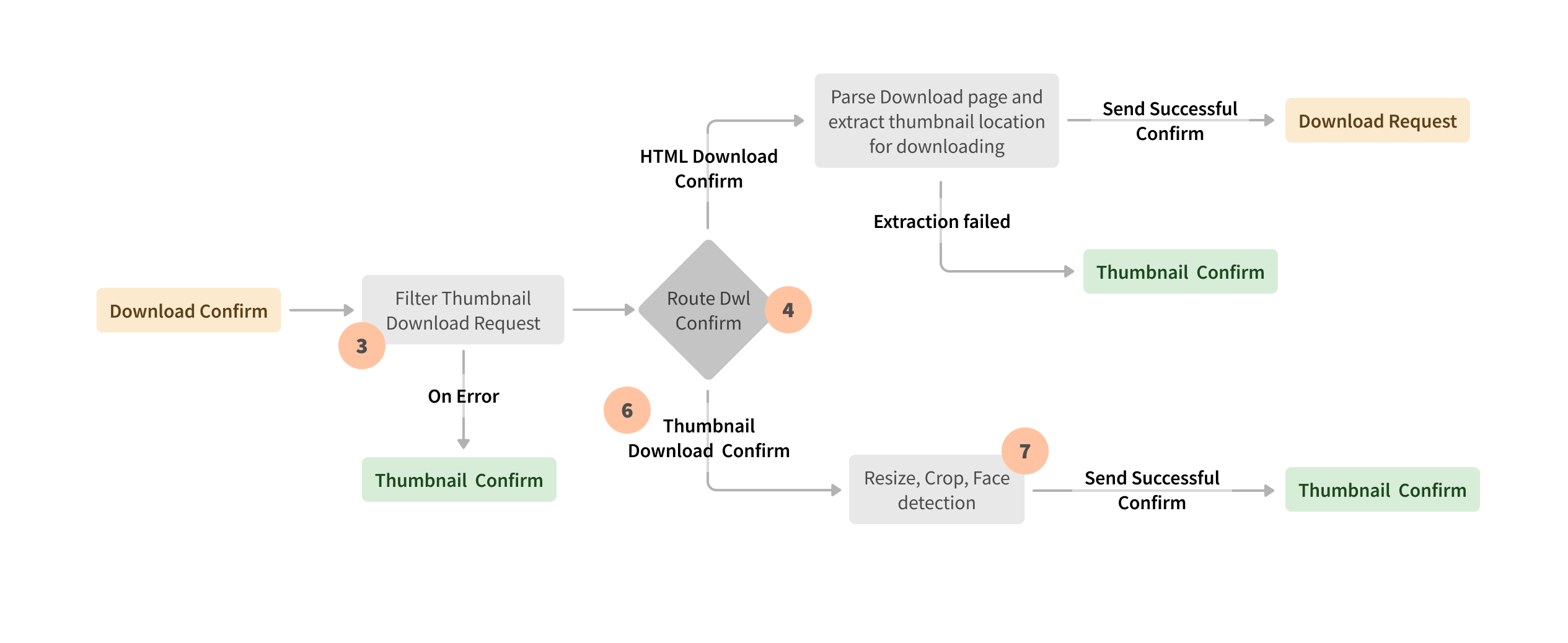
多年來,Seznam 的方法不斷發展。他們已經意識到 Apache Beam 在平衡 PB 級工作負載和優化內部資料中心的記憶體和運算資源方面的好處。Apache Beam 是 Seznam 處理需要多個 shuffle 操作、處理傾斜資料和實作複雜業務邏輯的批次和串流管線的首選平台。Apache Beam 統一模型,其來源和接收器公開為轉換,透過單元測試提高了業務邏輯的可維護性和可追蹤性。
最大的好處之一是 Apache Beam 接收器和來源。透過將來源或接收器公開為轉換,您的實作會被隱藏起來,稍後您可以新增其他功能,而不會破壞使用者的現有實作。
監控和除錯
Apache Beam 管線監控和除錯對於具有複雜業務邏輯和多個資料轉換的情況至關重要。Seznam 工程師根據執行引擎確定了最佳工具。Seznam 利用 Criteo 的 Babar 來分析 Spark 執行器上的 Apache Beam 管線,並找出其效能停機的根本原因。Babar 透過分析叢集資源利用率、已配置的記憶體、已使用的 CPU 等,可以更輕鬆地進行監控、除錯和效能優化。對於在 Kubernetes 叢集上由 Flink 執行器執行的 Apache Beam 管線,Seznam 使用 Elasticsearch 來儲存、搜尋和分析指標。
結果
Apache Beam 為 Seznam 的串流和批次處理提供了統一的模型,從而在大規模情況下提供了效能。Apache Beam 支援多個執行器、語言 SDK 以及內建和自訂的可插拔 I/O 轉換,因此無需投資開發和支援專有的執行器和解決方案。經過評估後,Seznam 將其工作負載轉換為 Apache Beam 並整合 Euphoria API(由 Seznam 開發的快速原型設計框架),為 Apache Beam 開源社群做出貢獻。
Apache Beam 抽象化和執行模型使 Seznam 能夠可靠地擴展其資料處理。它還提供了僅編寫一次業務邏輯的靈活性,並在執行器之間保留選擇的自由。該模型對於複雜用例中的管線可維護性特別有價值。Apache Beam 透過將分佈不均勻的資料重新 shuffle 到可管理的分割區中,幫助克服了記憶體和運算資源的限制。
此資訊是否有用?