




「如果沒有 Beam,沒有這些數據和即時資訊,我們就無法提供目前正在提供的服務,也無法處理正在處理的數據量。」

Apache Beam 加速 Ricardo 電商平台的即時和機器學習數據處理。
背景
Ricardo 是瑞士領先的二手商品交易平台。該網站支援超過 400 萬註冊買家和賣家,每年透過該平台處理超過 650 萬筆商品交易。 Ricardo 需要處理大量的串流事件,並管理超過 5 TB 的商品、資產和分析數據。
隨著在市場上 20 年的規模增長,Ricardo 決定從其內部數據中心遷移到雲端,以便更容易地成長和進一步發展,並透過受管理的雲服務來降低營運成本。數據情報和工程團隊在此轉型和開發新的 AI/ML 驅動的客戶體驗方面處於領先地位。 Apache Beam 已成為加速 Ricardo 轉型的技術放大器。
挑戰
從內部數據中心遷移到雲端,為 Ricardo 提供了一個機會,將他們的市場從嚴重依賴交易 SQL 轉變為使用 BigQuery 進行分析,並利用基於事件的串流架構。
Ricardo 的數據情報團隊確定了兩個關鍵的成功因素:精心設計的數據模型和一個框架,該框架提供統一的串流和批次數據管道執行,無論是在內部還是雲端。
Ricardo 需要一個可以輕鬆擴展、從多個來源豐富事件串流的歷史數據、提供對數據新鮮度的精細控制,以及提供抽象的管道操作基礎架構的數據處理框架,從而幫助他們的團隊專注於為客戶和業務創造新價值。
Beam 之旅
Ricardo 的數據情報團隊於 2018 年開始對其堆疊進行現代化改造。他們選擇了在內部和雲端都提供可靠且可擴展的數據處理的框架。 Apache Beam 允許使用者使用他們喜歡的程式語言創建管道,並提供 Java、Python、Go、SQL、Scala (SCIO) 的 SDK。 Beam 執行器會在特定的(通常是分散式的)數據處理系統上執行 Beam 管道。 Ricardo 選擇了 Apache Beam Flink 執行器,用於在內部執行管道,並選擇 Dataflow 執行器作為受管理的雲服務,用於執行使用 Apache Beam Java SDK 開發的相同管道。 Apache Flink 以其可靠性和成本效益而聞名,並且在 Ricardo 的數據中心建立了一個內部叢集作為初始環境。
我們想要實施一個可以倍增我們可能性的解決方案,而這正是 Beam 發揮作用的地方。此決策的主要驅動因素之一是能夠在不增加太多操作負載的情況下發展。
用於將事件數據從 Apache Kafka 攝取到 BigQuery 的核心業務工作負載的 Beam 管道在短短一個月內穩定運行。隨著 Ricardo 的雲端遷移進展,數據情報團隊將 Flink 叢集從 Kubernetes 遷移到他們內部數據中心的 GKE。
我知道 Beam,我知道它有效。當你需要從 Kafka 遷移到 BigQuery,並且你知道 Beam 正是正確的工具時,你只需要為它選擇正確的執行器。
根據特定使用案例和需求,能夠每小時、每分鐘或即時串流數據的靈活性,幫助團隊提高了數據新鮮度,這是 Ricardo 電商平台分析和報告的一個重大進展。
Ricardo 的團隊在 GKE 上自管理的 Flink 叢集中的 Apache Beam Flink 執行器中發現了串流管道的好處。對 Flink 布建的完全控制使能夠設定從 Flink 叢集到外部對等 Kafka 受管理服務的必要連線。數據情報團隊透過叢集資源利用率顯著優化了營運成本。對於批次管道,團隊選擇 Dataflow 受管理服務,因為其按需自動縮放和降低成本的功能(如 FlexRS),特別適用於在 TB 級歷史數據上訓練機器學習模型。這種混合方法很好地滿足了 Ricardo 的需求,並被證明是一個可靠的生產解決方案。
使用案例的演變
將串流視為運動中的數據,將表格視為靜止狀態的數據,提供了一個千載難逢的機會來看看早在 20 年前就做出的一些數據模型決策。市場上的商品具有描述它們的資產,為了提高效能和成本最佳化,屬於一起的數據實體被拆分為單獨的資料庫實例。 Apache Beam 使 Ricardo 的數據情報團隊能夠加入資產和商品串流並最佳化 BigQuery 掃描以降低成本。在設計管道時,團隊為資產和商品建立了串流。由於資產串流是主要的串流,他們將該串流往回移動 5 分鐘,並使用 BigTable 在其中建立查詢綱要。這個優雅的解決方案確保始終首先處理資產串流,而 BigTable 允許將最新的資產與商品相匹配,而 Apache Beam 將它們兩者結合在一起。
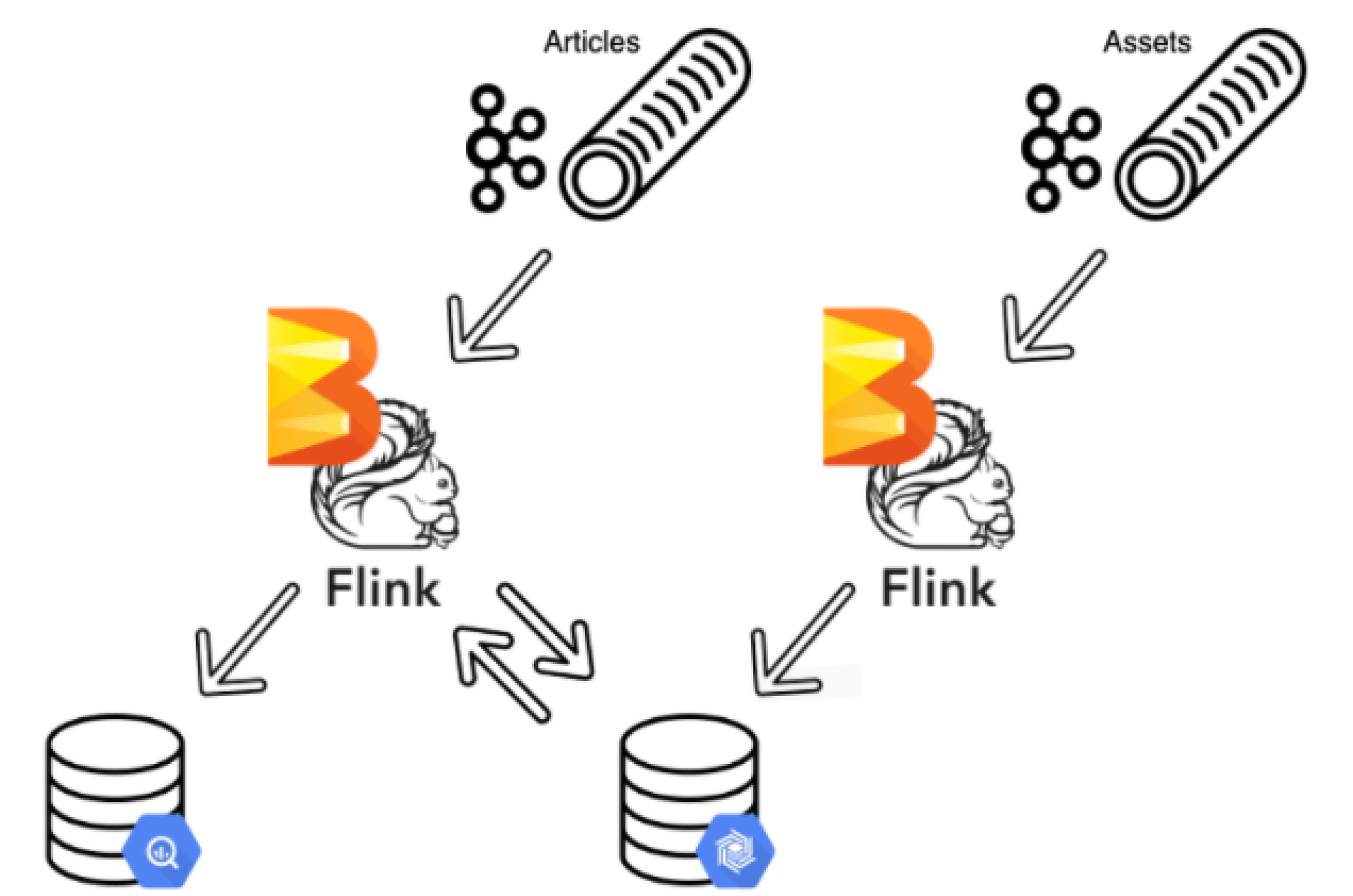
加入不同數據串流的成功案例促進了 Ricardo 在數據科學和機器學習等領域對 Apache Beam 的進一步採用。
一旦你開始規劃簡單的使用案例,你總是會找出邊緣案例情境。這個管道已經運行一年了,Beam 可以處理所有事情,從超簡單的使用案例到一些瘋狂的事情。
作為一家電子商務零售商,Ricardo 面臨著日益增長的欺詐交易規模和複雜性,並採取戰略性方法,使用 Beam 管道進行欺詐檢測和預防。 Beam 管道對外部智能 API 進行操作,以識別欺詐行為的跡象,例如裝置特性或使用者活動。 Apache Beam 的 狀態處理功能使 Ricardo 能夠將關聯操作應用於數據串流(例如,觸發禁止使用者)。 因此,Apache Beam 節省了 Ricardo 客戶服務團隊調查重複案例的時間和精力。它還運行批次管道以尋找連結的帳戶,透過封裝機器學習模型將產品與類別關聯,或計算某物銷售的可能性,達到以前不可能達到的規模或精度。
Apache Beam 最初由 Ricardo 的數據情報團隊實施,已被證明是一個強大的框架,支援高級情境,並充當 Kafka、BigQuery 以及平台和外部 API 之間的橋樑,這鼓勵了 Ricardo 的其他團隊採用它。
[Apache Beam] 是一個非常好的框架,我們測試過後,其他團隊也開始接受這個想法並開始使用它。
成果
Apache Beam 為 Ricardo 提供了一個可擴展且可靠的數據處理框架,該框架支援了 Ricardo 的基本業務情境,並實現了新的使用案例來即時回應事件。
在 Ricardo 的轉型過程中,Apache Beam 一直是一個統一的框架,可以運行批次和串流管道,提供內部和雲端受管理服務執行,以及 Java 和 Python 等程式語言選項,使數據科學和研究團隊能夠透過新的即時情境快速推進客戶體驗,縮短價值實現時間。
在這個第一個管道之後,我們正在研究其他使用案例,並計劃將它們遷移到 Beam。我一直試圖傳達這樣的觀點,這是一個可靠的框架,它實際上可以幫助你以一致的方式完成工作。
Apache Beam 一直是一項倍增可能性的技術,使 Ricardo 能夠在現代化和雲端旅程的所有階段最大化技術優勢。
了解更多
此資訊對您是否有用?