




「我確信一件事:Beam 非常強大,而抽象化是它最重要的特色。有了適當的抽象化,我們可以彈性地在需要的地方執行工作負載。感謝 Beam,我們不受限於任何供應商,而且如果轉換供應商也不需要變更任何其他東西。」

Palo Alto Networks 的大規模即時事件串流處理
背景
Palo Alto Networks, Inc. 是一家全球網路安全領導者,擁有全面的企業產品組合。Palo Alto Networks 為 超過 8.5 萬名客戶提供跨雲端、網路和裝置的保護、可見性、可信情報、自動化和彈性。
Palo Alto Networks 的整合式安全營運平台 - Cortex™ - 應用 AI 和機器學習,為 Palo Alto Networks 的客戶實現安全自動化、進階威脅情報和有效的快速安全回應。Cortex™ Data Lake 基礎設施收集、整合並標準化企業的安全資料,並結合數兆個多來源人工產物。
Cortex™ 資料基礎設施目前每秒處理約 1 千萬個安全日誌事件,每天約 3 PB,這在業界屬於即時串流處理規模的高端。Palo Alto Networks 的資深首席軟體工程師 Talat Uyarer 分享了 Apache Beam 如何提供高效能、可靠且具彈性的資料處理框架來支援這種規模的見解。
大規模串流基礎設施
在從頭建構資料基礎設施時,Palo Alto Networks 的 Cortex Data Lake 團隊面臨一項具挑戰性的任務。我們需要確保 Cortex 平台能夠串流和處理來自客戶的防火牆、網路和各種裝置的 PB 級資料,以低延遲和完美品質提供給客戶和內部應用程式。
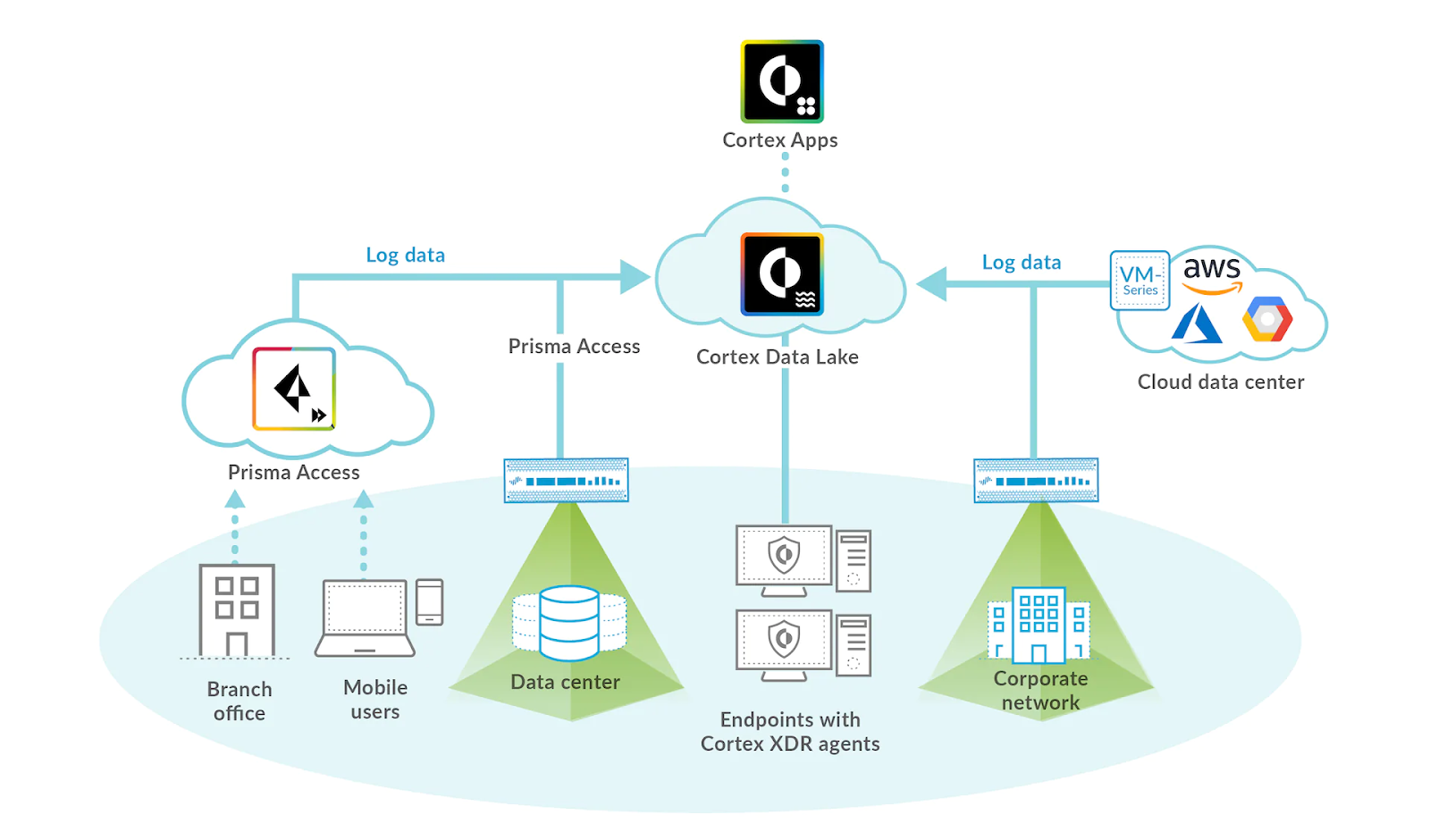
為了符合 SLA,Cortex Data Lake 團隊必須設計一個用於即時處理的大規模資料基礎設施,並縮短價值實現時間。他們最初的架構決策之一是利用 Apache Beam,這是業界用於統一分散式處理的標準,因為它具有可攜性和抽象化。
Beam 非常彈性,它對分散式資料處理實作細節的抽象化非常適合快速交付概念驗證。
Apache Beam 提供各種執行器,可在不同的資料處理引擎之間提供選擇自由。Palo Alto Networks 的資料基礎設施完全託管在 Google Cloud Platform 上,而且使用 Apache Beam Dataflow 執行器,我們可以輕鬆地從 Google Cloud Dataflow 的託管服務和 自動調整功能中獲益。Apache Kafka 被選為後端的訊息代理程式,而且所有事件都以二進位資料形式儲存在多個 Kafka 叢集上,並使用通用 schema。
Cortex Data Lake 團隊考慮為每位客戶採用獨立的資料處理基礎設施,多個上游應用程式建立自己的串流作業,直接從 Kafka 取用和處理事件。因此,我們正在建構一個多租戶系統。然而,該團隊預期會有與 Kafka 移轉和分割區建立相關的潛在問題,以及在有多個基礎設施時,可能無法清楚了解租戶使用案例。
因此,Cortex Data Lake 團隊採用了通用串流基礎設施方法。在通用資料基礎設施的核心,Apache Beam 作為統一程式設計模型,只需為所有內部和客戶租戶應用程式實作一次業務邏輯。
Cortex Data Lake 團隊實作的第一批資料工作流程很簡單:從 Kafka 讀取、建立批次作業,然後將結果寫入接收器。 支援 SQL 的 Apache Beam 版本的發布開啟了新的可能性。Beam Calcite SQL 完全支援 複雜的 Apache Calcite 資料類型,包括 SQL 語句中的巢狀列,因此開發人員可以在 Apache Beam 管線中使用 SQL 查詢來進行複合轉換。Cortex Data Lake 團隊決定利用 Beam SQL,使用標準 SQL 語句撰寫 Beam 管線。
通用基礎設施的主要挑戰是支援各種業務邏輯自訂和使用者定義函式,並將其轉換為各種接收器格式。租戶應用程式需要從動態變更的 Kafka 叢集中取用資料,而且如果作業的來源已更新,則必須重新產生串流管線 DAG。
Cortex Data Lake 團隊開發了自己的「訂閱」模型,允許租戶應用程式在向 REST API 服務傳送作業部署請求時「訂閱」串流作業。訂閱服務透過將基礎設施特定資訊儲存在中繼資料服務中,使租戶應用程式與 DAG 的變更隔離。這樣,串流作業即可與動態 Kafka 基礎設施保持同步。
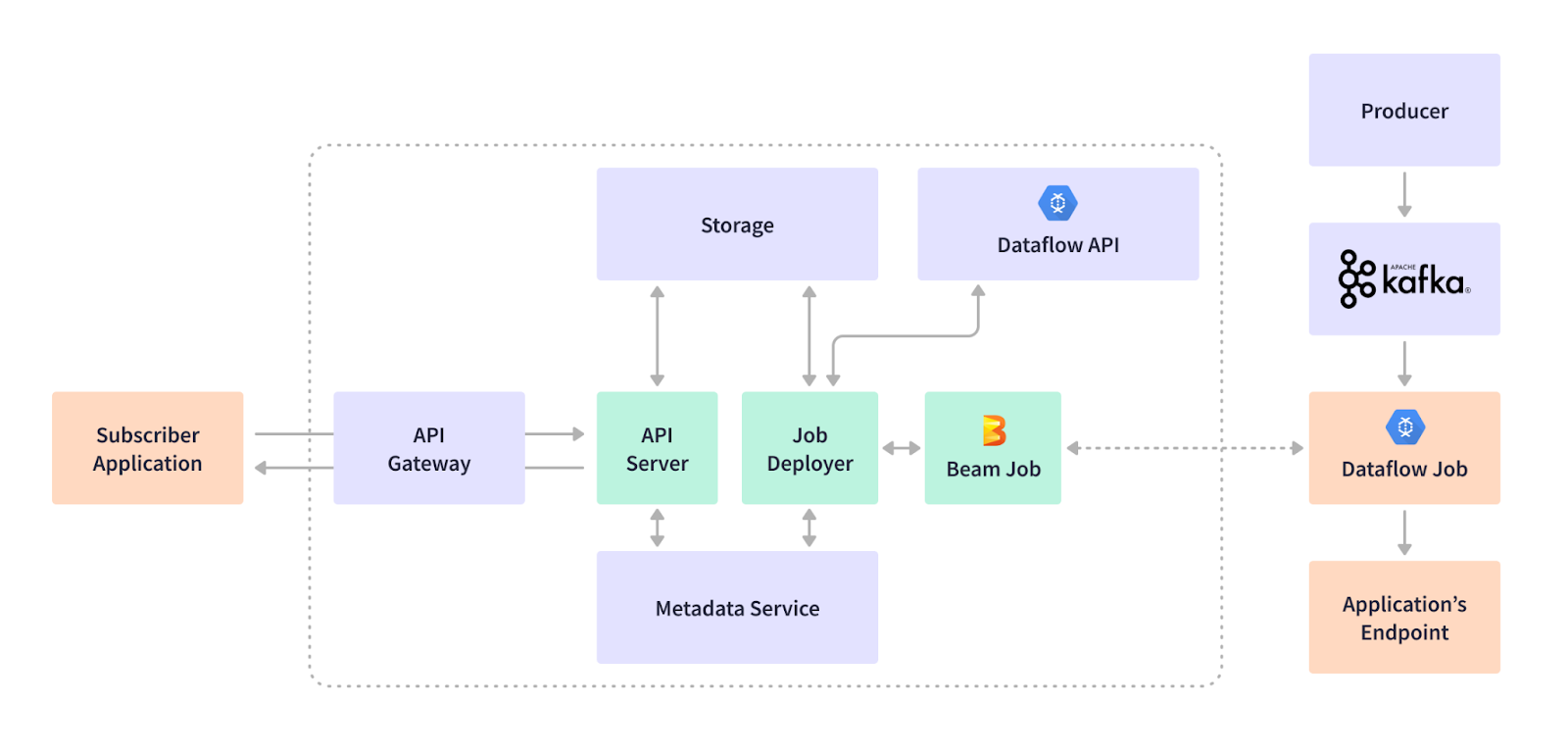
Apache Beam 非常彈性,允許動態地即時建立串流作業。Apache Beam 建構允許泛型管線編碼,即使未事先完全定義 schema,也能讓管線處理資料。Cortex 的訂閱服務會根據租戶應用程式的 REST 酬載產生 Apache Beam 管線 DAG,並將作業提交至執行器。當作業執行時,Apache Beam SDK 的 Kafka I/O 會將 Kafka 記錄的不受限制集合傳回為 PCollection。Apache Avro 會將二進位 Kafka 表示轉換為泛型記錄,然後再轉換為 Apache Beam Row 格式。Row 結構支援基本類型、位元組陣列和容器,並允許以與 schema 定義相同的順序組織值。
Apache Beam 的跨語言轉換允許 Cortex Data Lake 團隊使用 Java 執行 SQL。在 Apache Beam 管線內執行的SQL 轉換輸出,會循序從 Beam Row 格式轉換為泛型記錄,然後轉換為訂閱者應用程式所需的輸出格式,例如 Avro、JSON、CSV 等。
一旦實作了基本使用案例,Cortex Data Lake 團隊就轉向更複雜的轉換,例如直接在 Apache Beam 管線內篩選事件子集,並持續研究自訂和最佳化。
我們有超過 10 個使用案例在各客戶和應用程式中執行。還有更多使用案例即將推出,例如機器學習使用案例......對於這些使用案例,Beam 提供了非常好的程式設計模型。
Apache Beam 提供可插入的資料處理模型,可與各種工具和技術無縫整合,這讓 Cortex Data Lake 團隊可以根據效能需求和特定使用案例來自訂其資料處理。
針對使用案例自訂序列化
Palo Alto Networks 的串流資料基礎設施每天處理數千億個即時安全事件,即使處理時間差異僅為次秒也是至關重要。
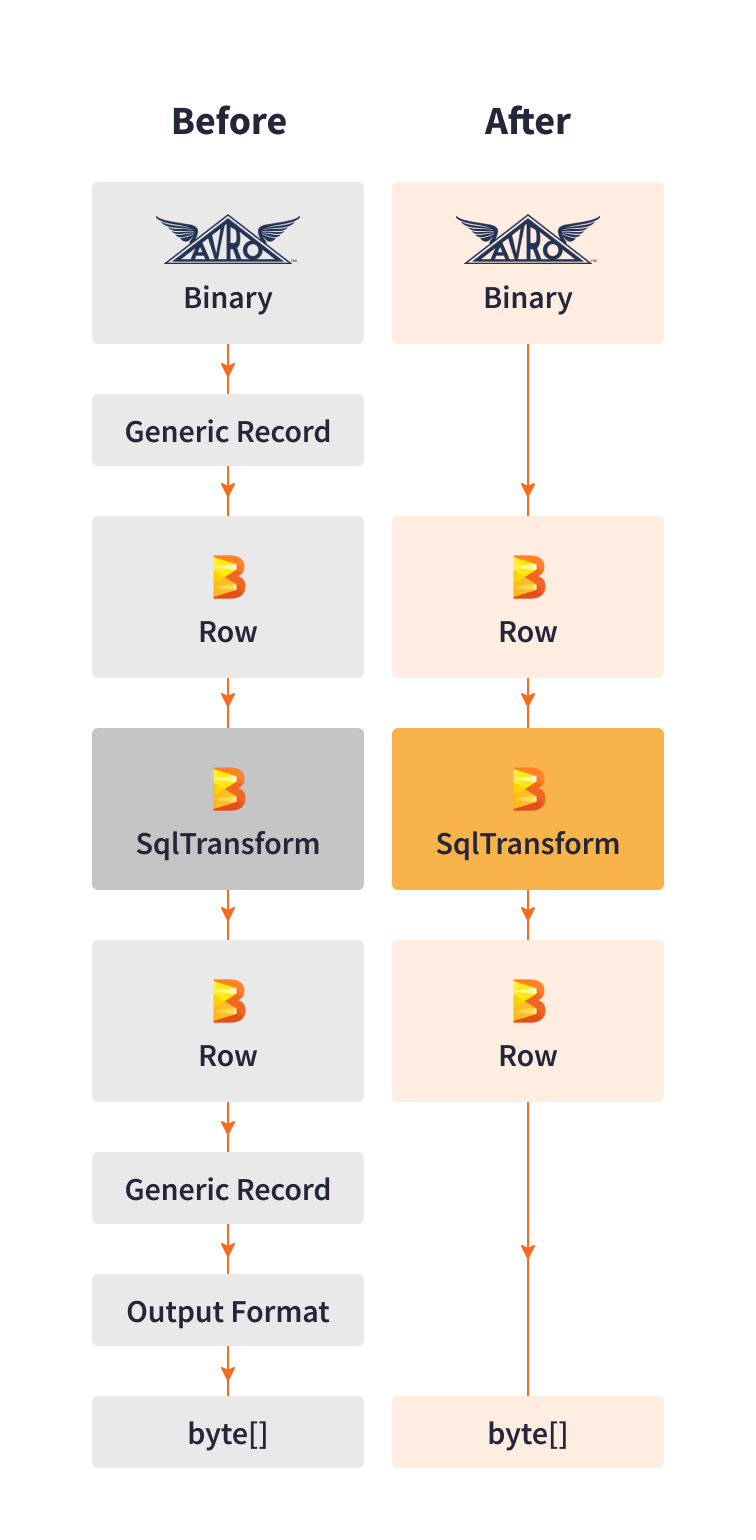
為了提高效能,Cortex Data Lake 團隊開發了自己的直接序列化和還原序列化程式庫。該程式庫從 Kafka 讀取 Avro 二進位記錄,並將其轉換為 Beam Row 格式,然後將 Beam Row 格式管線輸出轉換為所需的接收器格式。
此自訂程式庫取代了將資料序列化為泛型記錄,並採用針對 Palo Alto Networks 特定使用案例最佳化的步驟。直接序列化消除了混洗和從處理步驟建立額外的記憶體複本。
此自訂將序列化效能提高了 10 倍,使得每個 vCPU 每秒可處理高達 3K 個事件,同時降低了延遲和基礎設施成本。
執行中的串流作業更新
在數千個作業同時執行的規模下,Cortex Data Lake 團隊面臨需要改進管線程式碼或修復正在進行的作業錯誤的情況。Google Cloud Dataflow 提供一種方法,可以使用執行更新版 Apache Beam 管線程式碼的新作業取代「執行中的」串流作業。然而,Palo Alto Networks 需要擴展支援的案例。
為了處理動態變更的 Kafka 基礎設施中的作業更新,Cortex Data Lake 團隊在其部署服務中建立了一個額外的工作流程,如果 Dataflow 更新不允許變更,則清空作業,並以完全相同的命名啟動新作業。此內部作業取代工作流程允許 Cortex Data Lake 自動更新所有使用案例的作業和酬載。
處理 Beam SQL 中的 Schema 變更
Palo Alto Networks 處理的另一個使用案例是處理正在進行的作業的資料 schema 變更。Apache Beam 允許 PCollection 具有帶有名稱欄位的schema,這些 schema 會在管線建構步驟中驗證。提交作業時,會根據最新的 schema 產生以 Beam 管線片段形式的執行計畫。Beam SQL 尚未內建支援針對執行中的作業放寬 schema 相容性。為了獲得最佳效能,Beam SQL 的 Schema RowCoder 具有固定的資料格式,而且不處理 schema 演變,因此必須重新啟動作業才能重新產生其執行計畫。在 1 萬多個串流作業的規模下,Cortex Data Lake 團隊希望盡可能避免重新提交作業。
我們建立了一個內部工作流程,以識別與 schema 變更相關的 SQL 查詢作業。Schema 更新工作流程會將每個作業的讀取器 schema (Avro schema) 和每個 Kafka 訊息的寫入器 schema (Kafka 標頭上的中繼資料) 儲存在內部 Schema 登錄中,將它們與執行中作業的 SQL 查詢進行比較,並只重新啟動受影響的作業。這種最佳化讓他們能夠更有效率地利用資源。
微調 Kafka 變更的效能
由於 Kafka 中有多個叢集和主題,以及超過 10 萬個分割區,Palo Alto Networks 需要確保正在執行中的作業不會受到頻繁的 Kafka 基礎設施變更 (例如叢集移轉或分割區計數變更) 的影響。
Cortex Data Lake 團隊開發了數個內部 Kafka 生命周期支援工具,包括一個「自我修復」服務。根據來自特定租戶的每個主題的流量大小,內部服務會增加分區數量,或建立分區較少的新主題。「自我修復」服務會比較資料儲存區中的 Kafka 狀態,然後自動尋找並更新 Cloud Dataflow 上所有相關的串流 Apache Beam 作業。
隨著 2021 年初 Apache Beam 2.28.0 的發布,預先建置的 Kafka I/O 動態讀取功能提供了一個開箱即用的解決方案,用於偵測 Kafka 分區變更,以實現成本節省和效能提升。Kafka I/O 使用 WatchKafkaTopicPartitionDoFn 發出新的 TopicPartitions,並允許在新增某些分區時動態地從 Kafka 主題讀取,或在刪除這些分區時停止讀取。此功能消除了建立內部 Kafka 監控工具的需求。
除了效能優化之外,Cortex Data Lake 團隊也一直在探索優化 Cloud Dataflow 成本的方法。我們研究了串流作業消耗極少數傳入事件時的資源使用優化。為了實現成本效益,Google Cloud Dataflow 提供了串流自動調整功能,該功能會根據負載和資源利用率的變化,自動調整工作人員數量。對於 Cortex Data Lake 團隊的某些使用案例,其中輸入資料串流可能會長時間靜止,我們實作了一個內部「冷啟動器」服務,該服務會分析 Kafka 主題流量,並使輸入停止的管線休眠,並在其輸入恢復時重新啟動它們。
Talat Uyarer 在 Beam Summit 2021 期間,介紹了 Cortex Data Lake 團隊建構和客製化大規模串流基礎架構的經驗。
我真的很享受使用 Beam 工作。如果您了解其內部結構,這種理解會使您能夠微調開源程式碼、客製化它,使其為您的特定使用案例提供最佳效能。
結果
Apache Beam 的抽象層級使 Cortex Data Lake 團隊能夠在其內部應用程式和數萬名客戶之間建立通用基礎架構。透過 Apache Beam,我們只需實作一次業務邏輯,即可動態產生 10,000 多個並行執行的串流管線,以支援 10 多個使用案例。
Cortex Data Lake 團隊利用了 Apache Beam 的可攜性和可插拔性,透過自訂函式庫和服務來微調和增強其資料處理基礎架構。Palo Alto Networks 最終實現了高效能和低延遲,每個 vCPU 每秒處理 3,000 多個串流事件。結合開源 Apache Beam 和 Cloud Dataflow 受管理服務的優勢,我們能夠實作特定使用案例的客製化,並將成本降低了 60% 以上。
Apache Beam 開源社群歡迎並鼓勵其眾多成員(例如 Palo Alto Networks)的貢獻,這些成員利用 Apache Beam 的強大功能、帶來新的最佳化,並透過分享其專業知識和積極參與社群來推動未來的創新。
此資訊是否有用?