




「我們的數據量非常龐大,而 Apache Beam 有助於使其易於管理。對於每天數百萬筆交易中的每一筆,我們都會產生其市場估值在未來時間增量中的演變模擬,然後透過掃描多種可能的市場情景,將這些龐大的數據匯總為有意義的統計數據。Apache Beam 有助於利用所有這些數據,並使數據分發比以往更加容易。」

「Apache Beam Python SDK 透過提供一種簡單的方式,讓滙豐銀行的模型開發團隊在以 Python 編寫的管道中模擬業務邏輯工作流程節點之間複雜的數學依賴關係,將數學帶到了協調層面。我們過去至少需要 6 個月才能將系統方程式的微小變更部署到生產環境中。在 Apache Beam 驅動的新團隊結構下,我們現在可以在 1 週內快速部署變更。」

滙豐銀行使用 Apache Beam 進行高效能量化風險分析
背景
滙豐控股有限公司是滙豐銀行的母公司,總部位於倫敦。滙豐銀行在全球 62 個國家和地區的辦事處為客戶提供服務。截至 2023 年 3 月 31 日,滙豐銀行的資產達 29,900 億美元,是全球最大的銀行和金融服務機構之一。滙豐銀行的全球銀行及市場業務為跨國企業、政府和金融機構提供廣泛的金融服務和產品。
滙豐銀行的 XVA 和 CCR 資本分析副總裁 Chup Cheng 和首席助理副總裁 Andrzej Golonka 分享了 Apache Beam 如何作為計算平台和風險引擎,幫助滙豐銀行管理客戶投資組合中的交易對手信用風險和 XVA,這些風險來自每天數十億美元的交易量。Apache Beam 使滙豐銀行能夠將現有的 C++ HPC 工作負載整合到批次 Apache Beam 管道中,以簡化資料分發並提高處理效能。Apache Beam 還實現了以前不可能的新管道,並提高了開發效率。
大規模的風險管理
為了了解滙豐銀行以 Apache Beam 為動力的資料處理的規模和價值,讓我們深入探討為什麼金融機構的交易對手信用風險計算需要特別極端的計算能力。
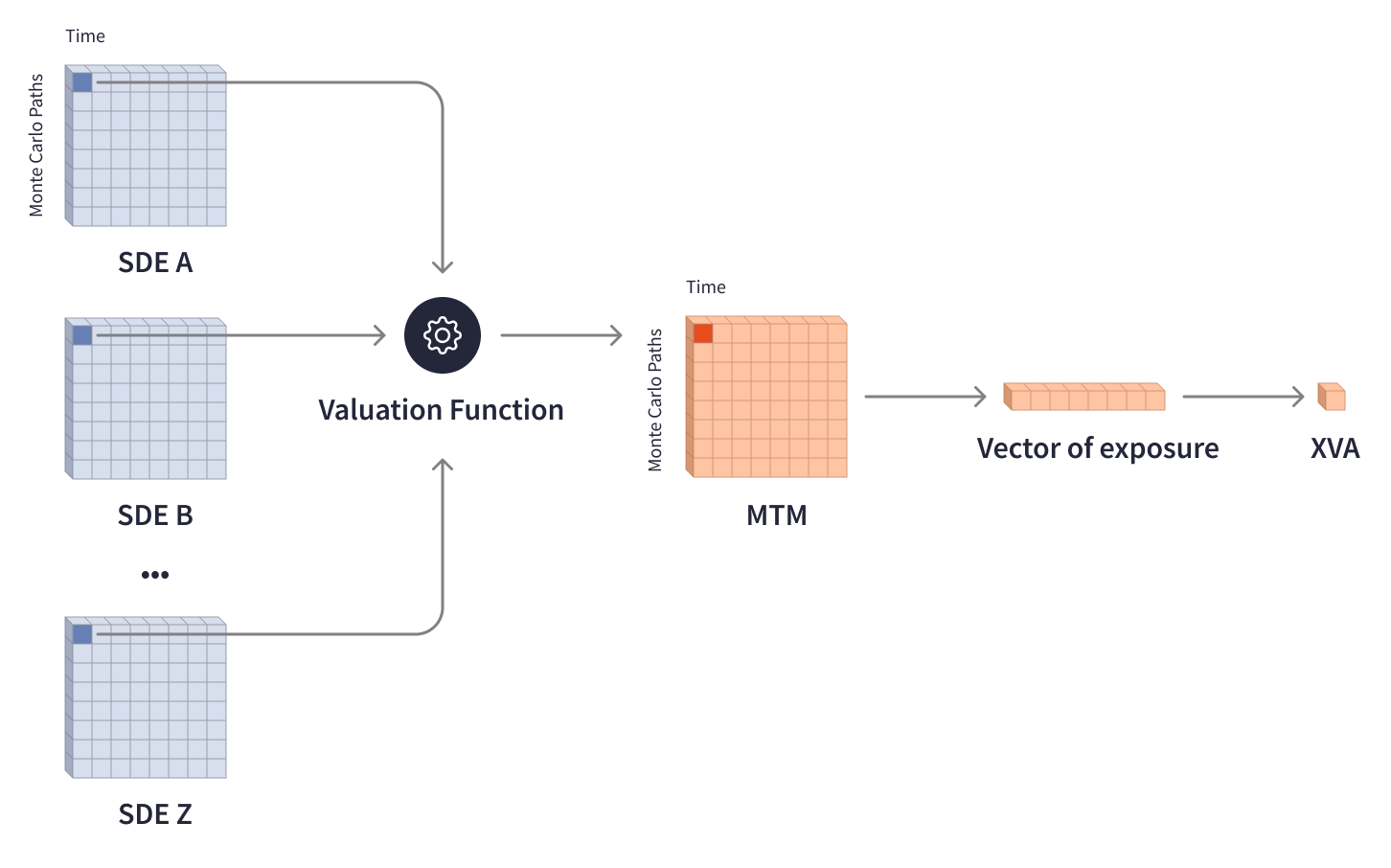
投資組合的價值隨著金融市場的波動而變化,並受到各種外部因素的影響。為了消除風險並確定法規要求的資本準備金,投資銀行需要評估風險敞口,並對個別交易和投資組合的價值進行相應的調整。XVA(X 值調整)模型在分析金融業的交易對手信用風險方面發揮著關鍵作用,涵蓋不同的估值調整,例如信用估值調整 (CVA)、資金估值調整 (FVA) 和 資本估值調整 (KVA)。計算 XVA 涉及複雜的模型、多層矩陣和蒙特卡洛模擬,以根據可能的未來情景計算風險。估值函數處理多個隨機微分方程 (SDE)矩陣,這些矩陣代表特定時間範圍內(最長可能為 70 年)可能的交易價值,然後輸出MTM(按市值計價)矩陣,這些矩陣表示金融資產的當前市場價值在未來情景下的分佈。匯總的 MTM 矩陣確定未來的風險敞口向量和所需的 XVA 調整。
由於涉及大量的矩陣數據和長時間範圍,XVA 計算需要大量的計算能力。為了計算一筆交易的 MTM 矩陣,估值函數需要數十萬次迭代多個 SDE 矩陣,這些矩陣的大小為數兆字節,並且每個矩陣包含數十萬個元素。
在多方交易對手投資組合上計算 XVA 涉及更複雜的計算,這是在一個龐大的系統方程式中進行的。估值函數會處理數百 GB 的 SDE 矩陣,生成數百萬個交易級別的 MTM 矩陣,將它們匯總到交易對手級別的矩陣,然後計算每個交易對手的未來風險敞口和 XVA。
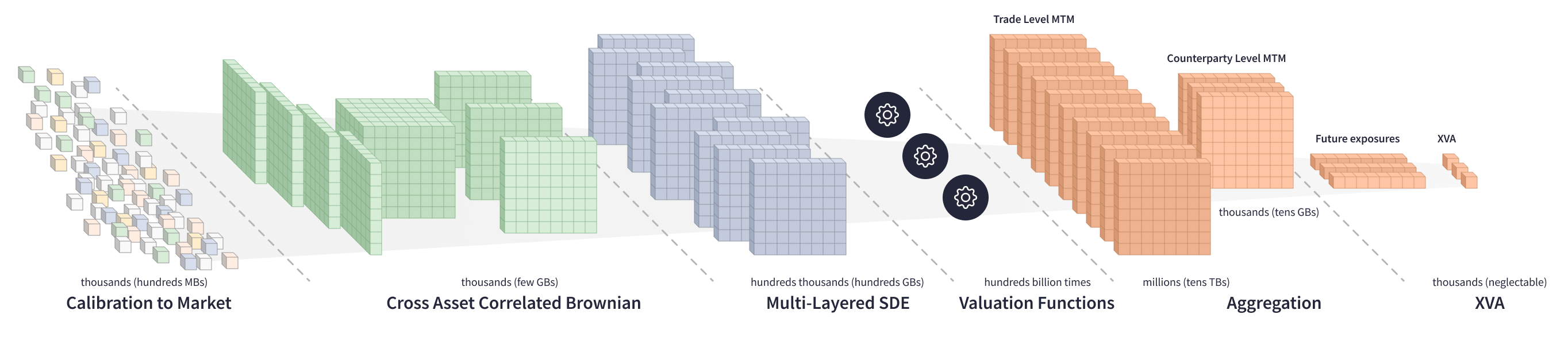
當處理對眾多市場因素敏感的 XVA 時,技術挑戰會加劇。為了消除交易對手投資組合中的所有市場風險,投資銀行需要計算數百個市場因素的 XVA 敏感度。計算 XVA 敏感度的方法主要有兩種:
- 透過反向傳播分析計算輸入
- 透過觀察 XVA 的梯度如何移動來進行數值計算
為了獲得 XVA 變異數,估值函數必須在龐大的系統方程式中迭代數千億次,這是一個計算量極大的過程。
XVA 模型對於了解金融業的交易對手信用風險至關重要,其準確計算對於評估衍生性金融商品的全部價格至關重要。由於涉及大量的數據和複雜的計算,這些計算的有效且及時的執行對於確保交易員能夠做出明智的決策至關重要。
邁向 Beam 的旅程
NOLA 是滙豐銀行用於 XVA 計算的內部數據基礎架構。其先前版本 NOLA1 是一個內部部署的解決方案,使用 10 TB 的檔案伺服器作為媒介,在單一批次中處理數兆字節的數據,在每個系統方程式中經歷一個龐大的相互依賴網路,然後重複該過程。滙豐銀行的模型開發團隊在建立量化函式庫時創建新的統計模型,而其 IT 團隊則將必要的數據提取到函式庫中,兩個團隊共同協作以規劃系統方程式之間的協調。
2007 年至 08 年的金融危機凸顯了整個行業對穩健且高效的 XVA 計算的需求,並在金融業引入了額外的法規,這些法規要求指數級更高的計算量。因此,滙豐銀行尋求一種數值解決方案來計算數百個市場因素的 XVA 敏感度。以單一批次處理數據已成為一個障礙和吞吐量瓶頸。NOLA1 基礎架構及其密集的 I/O 利用率[當時]不利於擴展。
滙豐銀行的工程師開始尋找一種新的方法,該方法可以擴展其資料處理、最大限度地提高吞吐量並滿足關鍵的業務時間表。
然後,滙豐銀行的工程團隊選擇 Apache Beam 作為 NOLA 的風險引擎,因為它具有可擴展性、彈性和並行處理大量數據的能力。他們發現 Apache Beam 是 XVA 計算的轉換式、有向無環圖流程的自然程序執行器。Apache Beam Python SDK 提供了一個簡單的 API 來在 Python 中建構新的數據管道,而它的抽象提供了一種重複使用 C++ 中普遍存在的分析方法的方式。Apache Beam 執行器的多樣性提供了可移植性,並且滙豐銀行的工程師使用在Apache Flink 和 Cloud Dataflow 上運行的 Apache Beam 管道建構了其數據基礎架構的新版本 - NOLA2。
資料分發比以往更輕鬆
Apache Beam 極大地簡化了 XVA 計算的數據分發,並允許使用工作程式之間的分散式處理來處理相互關聯的蒙特卡洛模擬。
Apache Beam SDK 使使用者能夠建構具表現力的 DAG,並輕鬆建立串流或批次多階段管道,在這些管道中,可以使用側輸入或聯結將並行管道階段重新組合在一起。資料移動由執行器處理,資料表示為 PCollection 物件,這些物件是不可變的並行元素集合。
Apache Beam 提供了幾種分發 C++ 元件的方法:
- 將 C++ 元件側載到自訂工作程式容器映像(例如,自訂 Apache Beam 或 Cloud Dataflow 容器),然後使用 DoFn 與現成的 C++ 元件互動
- 在 Apache Beam 中使用 JAR 檔案捆綁 C++,其中 C++ 元素(二進位檔案、組態等)在 DoFn 中的設定/關閉過程中被解壓縮到本機磁碟
- 將 C++ 元件作為側輸入包含在 PCollection 中,然後將其部署到本機磁碟
Apache Beam 與 C++ 的無縫整合讓滙豐銀行的工程師能夠重複使用普遍存在的分析方法(依賴於 NAG 和 MKL 函式庫),並根據使用案例和部署環境選擇邏輯分發方法。滙豐銀行發現 protobufs 特別適用於資料交換,當 PCollections 將呼叫和輸入數據從 Java 或 Python 管道傳輸到 C++ 函式庫時。protobuf 數據可以透過磁碟、網路或直接使用 pybind11 等工具進行共享。

匯豐銀行將其 XVA 計算遷移到批次 Apache Beam 管道。每天,XVA 管道在短短 1 小時內計算超過數千億次的估值,消耗約 2 GB 的外部輸入數據,在方程式系統內處理 10 到 20 TB 的數據,並產生約 4 GB 的輸出報告。Apache Beam 將 XVA 計算分配到多個具有任務的 PCollection 中,獨立且並行地執行必要的轉換,並產生 map-reduce 的結果 - 全部在一次處理中完成。
Apache Beam 提供了強大的轉換和協調功能,幫助匯豐銀行的工程師優化了 XVA 敏感度計算的分析方法,並實現了以前不可能實現的數值方法。匯豐銀行的工程師沒有迭代整個方程式系統的估值函數,而是將方程式系統視為計算圖,將其分解為具有可重複使用元素的集群,並迭代最小的計算圖。他們使用 Apache Beam 協調,通過調用 C++「可執行檔」,有效地處理每個投資組合數萬個集群。Apache Beam 使匯豐銀行能夠使用 KV PCollections 捆綁多個市場因素,將 PCollection 的每個輸入元素與一個鍵關聯起來,並在單個 Apache Beam 批次管道中計算數百個市場因素的 XVA 敏感度。
執行分析和數值 XVA 敏感度計算的 Apache Beam 管道每天分兩個獨立的批次運行。第一個批次管道在午夜運行,確定交易員的信用額度消耗和資本利用率,直接影響他們第二天的交易量。第二個批次在上午 8 點之前完成,計算可能影響交易員風險管理和對沖策略的 XVA 敏感度。該管道每天消耗約 2 GB 的外部市場數據,在方程式系統中處理高達 400 TB 的內部數據,並將數據聚合到僅約 4 GB 的輸出報告中。在每個月的月底,該管道會在方程式系統中處理超過 5 PB 的每月數據,以產生完整的 XVA 敏感度報告。Apache Beam 解決了數據分佈和熱點問題,協助管理複雜計算中涉及的數據。
Apache Beam 為匯豐銀行提供了傳統風險引擎的所有特性,甚至更多,使匯豐銀行能夠擴展基礎架構並通過分散式處理最大限度地提高吞吐量。
Apache Beam 使數據分發比以前容易得多。蒙地卡羅方法顯著增加了要處理的數據量。Apache Beam 幫助我們利用了所有這些數據量。
Beam 作為平台
Apache Beam 不僅僅是一個數據處理框架。它還是一個計算平台,可以實現實驗、加速新開發的上市時間並簡化部署。
Apache Beam 以 PCollection 形式的數據集抽象,通過提供一種組織組件所有權、減少組織依賴性和瓶頸的方式,提高了匯豐銀行的模型開發效率。模型開發團隊現在擁有數據管道:實施新的方程式系統、在黑盒模式下定義方程式系統內的數據傳輸,並將其發送給 IT 團隊。IT 團隊獲取、控制並協調整個方程式系統所需的外部數據。
總體而言,我們過去至少需要 6 個月才能將即使很小的變更部署到生產中的方程式系統。通過 Apache Beam 驅動的新團隊結構,我們現在可以在 1 週內快速部署變更。
通過利用 Apache Beam 統一編程模型提供的抽象,匯豐銀行的模型開發團隊可以無縫創建新的數據管道、選擇合適的執行器,並在沒有底層基礎架構的情況下進行大數據實驗。Apache Beam 模型規則確保了實驗代碼的高質量,並使將生產級管道從實驗轉移到生產變得非常容易。
通過 Apache Beam,很容易試驗「如果…會怎樣」的問題。如果我們想知道更改某些參數的影響,我們可以編寫一個簡單的 Apache Beam 代碼,運行管道,並在幾分鐘內得到答案。
Apache Beam 用於蒙地卡羅模擬和交易對手信用風險分析的一個主要優勢是,它能夠在各種環境中,在本地或雲端,使用不同的執行器運行相同的複雜模擬邏輯。這種靈活性在需要在不同國家和合規區域進行本地風險分析的情況下尤其關鍵,因為敏感的財務數據和信息不能超出本地範圍傳輸。通過 Apache Beam,匯豐銀行可以輕鬆地在執行器之間切換,並為任何變更提供數據處理的未來保障。匯豐銀行在 Cloud Dataflow 中運行大多數工作流程,受益於其強大的託管服務和自動縮放功能,以便在每天運行兩次批次管道時管理高達 18,000 個 vCPU 的峰值。在某些國家,他們還使用 Apache Beam Flink 執行器,以符合當地有關數據存儲和處理的法規。
結果
Apache Beam 利用大量的金融市場數據和指標,生成數十億次的交易估值以掃描未來 70 年左右的可能情景,並將其聚合為有意義的統計數據,使匯豐銀行能夠建模其未來情景,並在預測和決策中量化風險。
通過 Apache Beam,匯豐銀行的工程師實現了數據處理性能提高了 2 倍,並將其 XVA 批次管道與原始解決方案相比擴展了 100 倍。Apache Beam 抽象開闢了一種在生產中實施 XVA 敏感度計算的數值方法,這在以前是不可能實現的。批次 Apache Beam 管道計算數百個市場因素的 XVA 敏感度,每天處理約 400 TB 的內部數據,每月處理高達 5 PB 的數據。
Apache Beam 的可移植性使匯豐銀行能夠根據當地數據處理要求在不同地區使用不同的執行器,並為監管變更提供數據處理的未來保障。
Apache Beam 提供與 C++ 中高度優化的計算組件的無縫集成和開箱即用交互,這為匯豐銀行節省了將多年來累積的 C++ 分析重寫為 Python 所需的工作量。
Apache Beam Python SDK 通過為匯豐銀行的模型開發團隊提供一種構建新 Python 管道的簡便方法,將數學帶到了協調層。由 Apache Beam 驅動的新工作結構將上市時間縮短了 24 倍,使匯豐銀行的團隊能夠在短短幾週內將變更和新模型部署到生產中。
通過利用 Apache Beam 通用且可擴展的特性來計算處理大型微分方程系統和蒙地卡羅模擬的有向無環圖,金融機構可以有效地評估和管理交易對手信用風險,即使在需要本地化分析和嚴格遵守數據安全法規的情況下也是如此。
了解更多
此資訊是否有用?