




「Apache Beam 對我們來說是理想的解決方案。擴展規模、回填歷史資料、試驗新的 ML 模型和新的用例……使用 Beam 都非常容易。」

「Apache Beam 為我們的資料科學家實現了自助式 ML。他們可以插入程式碼片段,這些轉換將自動附加到模型,無需任何工程方面的介入。我們的資料科學團隊可以在幾秒鐘內從實驗轉向生產。」

使用 Apache Beam 實現自助式機器學習工作流程和擴展 MLOps
背景
Credit Karma 是一家美國跨國個人理財公司,於 2007 年成立,現為 Intuit 的一部分。Credit Karma 透過免費的信用和財務管理平台,為近 1.3 億名會員提供個人化的財務見解和建議,幫助他們實現財務進展。
Credit Karma 的資料科學和工程團隊使用機器學習來為會員提供最相關的內容和優惠,並針對每位會員的財務狀況和目標進行最佳化。Credit Karma 的資深資料工程師 Avneesh Pratap 和 Raj Katakam 分享了 Apache Beam 如何幫助他們建立穩健、有彈性且可擴展的資料和 ML 基礎架構。他們還分享了統一的 Apache Beam 資料處理如何縮小試驗新的 ML 管線和將其部署到生產之間的差距。
普及化和擴展 MLOps
在 2018 年之前,Credit Karma 使用基於 PHP 的 ETL 管線從多個金融服務合作夥伴擷取資料,執行不同的轉換並將輸出記錄到他們自己的資料倉儲中。隨著合作夥伴和會員數量的持續增長,Credit Karma 的資料團隊發現擴展其 MLOps 具有挑戰性。進行任何變更和試驗新的管線和屬性都需要大量的工程開銷。例如,僅僅為了讓新的合作夥伴加入就花費了數週的時間。他們的資料工程團隊正在尋找方法來克服擷取資料和評估 ML 模型時的效能缺點,並在同一個管線內回填新功能。在 2018 年,Credit Karma 開始設計他們新的資料和 ML 平台 - Vega - 以跟上不斷增長的規模,更好地了解會員,並提高他們對高度個人化優惠的參與度。
Apache Beam,業界統一分散式處理的標準,已成為 Vega 的核心。
當我們開始探索 Apache Beam 時,我們發現這個程式設計模型非常有前景。起初,我們僅將一個合作夥伴遷移[到 Apache Beam 管線]。結果讓我們印象非常深刻,並立即遷移到其他合作夥伴管線。
使用 Apache Beam Dataflow 執行器,Credit Karma 受益於 Google Cloud Dataflow 的託管服務,以確保更高的擴展性和效率。Apache Beam 內建 I/O 連接器為各種接收器和來源提供原生支援,這使 Credit Karma 能夠將 Beam 無縫整合到他們的生態系統中,並結合各種 Google Cloud 工具和服務,包括 Pub/Sub、BigQuery 和 Cloud Storage。
Credit Karma 利用 Apache Beam 核心和 Jupyter Notebook 在 Vega 中建立探索環境,並使其資料科學家能夠在無需工程介入的情況下建立新的實驗性資料管線。
Credit Karma 的資料科學家主要使用 SQL 和 Python 來建立新的管線。Apache Beam 提供了強大的 使用者定義函數,具有多語言功能,允許以 Java 或 Scala 編寫純量或聚合函數,並在 SQL 查詢中呼叫它們。為了將 Scala 轉換普及到他們的資料科學團隊,Credit Karma 的工程師將 UDF、Tensorflow Transforms 和其他具有多種組件的複雜轉換(可重複使用和共享的「建構區塊」)抽象化,以建立 Credit Karma 的資料和 ML 平台。Apache Beam 和自訂抽象允許資料科學家在建立實驗性管線和轉換時操作這些組件,這些組件可以輕鬆地在預備和生產環境中重現。Credit Karma 的資料科學團隊將程式碼變更提交到共用的 GitHub 儲存庫,然後將管線合併到預備環境中,並組合到生產應用程式中。
在處理財務和敏感資訊時,Apache Beam 抽象層在將假設和實驗操作化為生產管線方面發揮了至關重要的作用。Apache Beam 允許在將資料寫入資料倉儲之前,直接在資料管線中遮蔽和篩選資料。Credit Karma 使用 Apache Thrift 註釋來標記資料行中繼資料,Apache Beam 管線根據 Thrift 註釋篩選資料中的特定元素,然後再將其傳送到資料倉儲。Credit Karma 的資料科學團隊可以使用可用的抽象或在其之上編寫資料轉換,以計算新的指標並驗證 ML 模型,而無需查看實際資料。
Apache Beam 幫助我們將財務方面和不可洩漏的資訊「黑箱化」,以便團隊可以在不實際存取所有資料的情況下處理成本和財務資訊。
目前,約有 20 個 Apache Beam 管線正在生產環境中執行,還有 100 多個實驗性管線正在開發中。許多即將推出的實驗性管線都利用 Apache Beam 有狀態處理,直接在串流管線中計算使用者彙總,而不是在資料倉儲中計算。Credit Karma 的資料科學團隊還計劃利用 Beam SQL 在串流處理管線中直接使用 SQL 語法,並輕鬆建立彙總。Apache Beam 對執行引擎和各種執行器的抽象允許 Credit Karma 使用不同的引擎在模擬資料上測試資料管線效能,建立基準並比較不同資料生態系統的結果,以根據特定的用例最佳化效能。
統一的串流和批次資料擷取
Apache Beam 使 Credit Karma 能夠改造他們最重要的用例之一 - 資料擷取管線。許多 Credit Karma 合作夥伴透過閘道將其金融產品和服務的相關資料傳送到 Pub/Sub 以進行下游處理。以 Scio 編寫的串流 Apache Beam 管線會即時使用 Pub/Sub 主題,並處理深度巢狀的 JSON 資料,將其扁平化為資料庫資料列格式。該管線還會結構化和分割資料,然後將結果寫入 BigQuery 資料倉儲以進行 ML 模型訓練。
Apache Beam 統一的程式設計模型執行批次和串流用例的業務邏輯,這使 Credit Karma 能夠開發一個統一的管線。資料擷取管線處理即時資料和批次資料擷取,以將合作夥伴的歷史資料回填到資料倉儲中。Credit Karma 的某些合作夥伴使用 GCS 或 S3 等物件儲存傳送歷史資料,而某些合作夥伴則使用 Pub/Sub。Apache Beam 透過在同一個管線中建立有界和無界 PCollection 來統一批次和串流處理,具體取決於用例。從批次物件儲存讀取會建立有界 PCollection。從串流和不斷更新的 Pub/Sub 讀取會建立無界 PCollection。在回填過去日期的功能時,Credit Karma 的資料工程團隊會將相同的串流 Apache Beam 管線設定為以批次方式處理合作夥伴傳送的歷史資料區塊:讀取整個資料集一次,並在有限長度的作業中將歷史資料元素與特定日期的資料聯結。
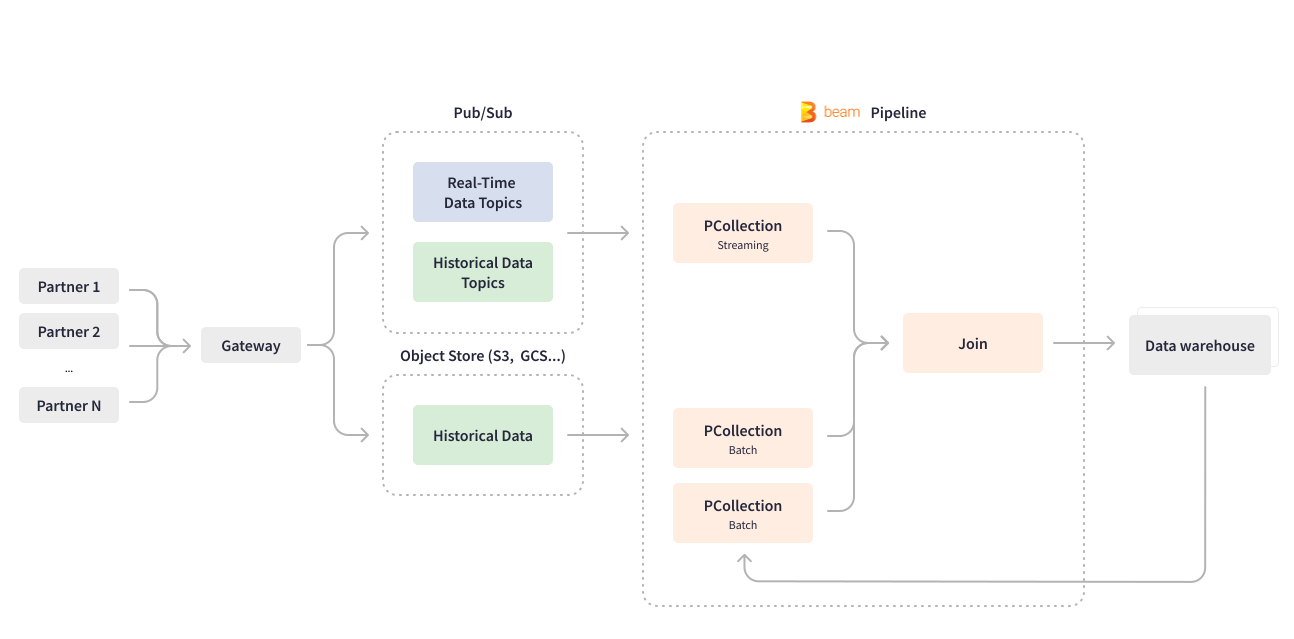
Apache Beam 非常靈活,其結構允許通用管線編碼和輕鬆設定,以便在不變更管線程式碼的情況下新增資料屬性、來源和合作夥伴。Cloud Dataflow 服務提供進階功能,例如動態地將正在進行的串流作業替換為新的管線。Apache Beam Dataflow 執行器使 Credit Karma 的資料工程團隊能夠在不耗盡正在進行的作業的情況下部署管線程式碼更新。
Credit Karma 為第三方資料提供者合作夥伴提供了一種部署其自有模型以進行內部決策和預測的方式。其中一些模型需要回填過去 3 到 8 個月的自訂屬性以進行模型訓練,這會產生巨大的資料峰值。Apache Beam 抽象層及其 Dataflow 執行器有助於在處理這些定期峰值時最大限度地減少基礎架構管理工作。
透過 Apache Beam,您可以輕鬆新增複雜的處理邏輯,例如,您可以在處理時間上新增可設定的觸發器。同時,Dataflow 執行器會為您管理執行,它會自動上傳您的可執行程式碼和依賴項。而且您可以使用現成的 Dataflow 自動擴展功能。您不必擔心橫向擴展的問題。
目前,資料擷取管線處理和轉換超過 1 億條訊息,以及定期回填,相當於大約 5-10 TB 的資料。
自助式機器學習
在 Credit Karma,資料科學家負責建立模型和分析資料,因此公司讓他們擁有輕鬆建立、測試和部署新模型的能力和靈活性至關重要。Apache Beam 提供了一個抽象,使資料科學家能夠在原始功能空間上編寫自己的轉換,以實現高效的 ML 工程,同時保持模型服務層獨立於任何自訂程式碼。
Apache Beam 協助 Credit Karma 自動化其機器學習的流程,包括模型串接與評分,以及準備用於機器學習模型訓練的資料。Apache Beam 提供 Beam DataFrame API 來識別並實作所需的預處理步驟,以便更快地迭代至產品階段。Apache Beam 內建的 I/O 轉換功能可原生讀寫 TensorFlow TFRecord 檔案,Credit Karma 利用這種連結性來預處理資料、評估模型,並使用模型分數來推薦金融產品和內容。
Apache Beam 使 Credit Karma 能夠處理大量的數據,無論是針對預處理和模型驗證,還是在預處理過程中進行數據實驗。他們使用 TensorFlow Transforms 來對批次資料和即時模型推論應用轉換。TensorFlow Transforms 的輸出會匯出為 TensorFlow 圖表,並附加到模型上,使預測服務獨立於任何轉換。Credit Karma 能夠通過對原始資料進行即時轉換,而不是對需要數據工程團隊參與的彙總資料進行轉換,來卸載預測服務上的臨時變更。他們的資料科學家現在可以使用 SQL 在原始資料上編寫任何類型的轉換,並在不變更基礎設施的情況下部署新模型。
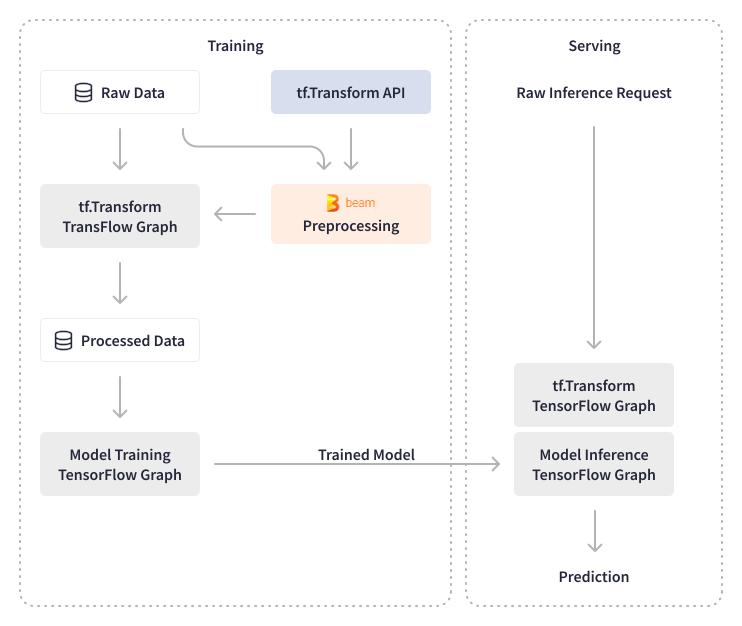
Apache Beam 和客製化抽象化使 Credit Karma 的數據科學團隊能夠創建新模型,特別是為 Credit Karma 的推薦系統提供動力,而無需工程上的額外負擔。數據科學家創建的程式碼會自動編譯成 Airflow DAG,部署到暫存沙箱,然後部署到生產環境。在模型訓練和推論方面,Credit Karma 的數據工程師使用建立在 Apache Beam 之上的 Tensorflow 函式庫 - TensorFlow Model Analysis (TFMA) 和 TensorFlow Data Validation (TFDV) - 來執行機器學習模型和特徵的驗證,並實現自動化的機器學習模型更新。對於模型分析,他們利用原生的 Apache Beam 轉換來計算統計數據,並建立了內部函式庫轉換,用於驗證新模型的效能和準確性。例如,批次 Apache Beam 管道會計算機器學習模型的演算法特徵(分數)。
Apache Beam 為我們的數據科學家實現了自助式機器學習。他們可以插入程式碼片段,這些轉換將會自動附加到模型上,而無需任何工程上的參與。在幾秒鐘內,我們的數據科學團隊只需變更部署路徑,即可將 DAG 從實驗環境移動到生產環境。
經證明,由 Apache Beam 驅動的機器學習管道非常可靠,每天處理超過 1 億個事件,並使用新數據更新機器學習模型。
實現即時資料可用性
Credit Karma 利用機器學習來分析使用者行為,並推薦最相關的產品和內容。在使用 Apache Beam 之前,跨多個系統收集使用者行為(日誌)需要大量的手動步驟和多種工具,這導致處理效能不佳,並且每當需要進行任何變更時,團隊之間都需要來回溝通。Apache Beam 協助自動化此日誌管道。跨系統的使用者會話日誌記錄在 Kafka 主題中,並儲存在 Google Cloud Storage 中。以 Scio 編寫的批次 Apache Beam 管道會解析特定追蹤 ID 的使用者行為,轉換和清理數據,然後將其寫入 BigQuery。
現在我們已經將日誌管道遷移到 Apache Beam,我們對其速度和效能感到非常滿意,並且我們計劃將此批次管道轉換為串流管道。
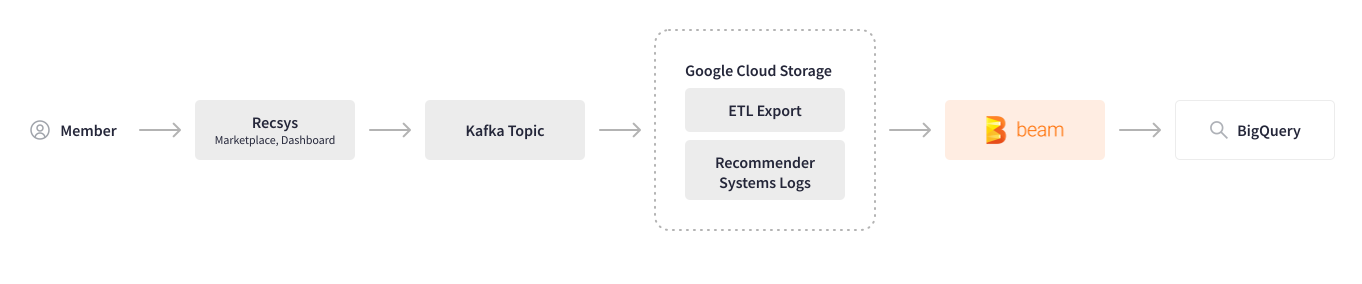
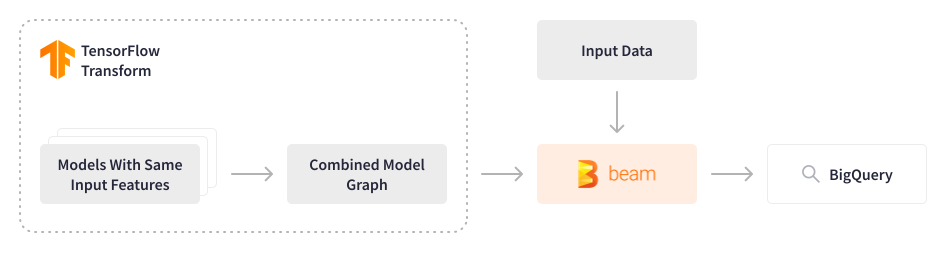
Credit Karma 使用其部分機器學習模型為推薦系統提供動力,並處理近 1.3 億會員的數據,因此採用 FinOps 文化,不斷探索優化基礎設施成本同時提高處理效能的方法。Credit Karma 中使用的 Tensorflow 模型過去是逐個循序評分的,即使輸入特徵相同,這也導致了過高的計算成本。
Apache Beam 提供了一個重新考慮這種方法的機會。數據工程團隊開發了一個 Apache Beam 批次管道,該管道將多個 Tensorflow 模型合併為一個單一合併模型,以每秒 5,000 個事件的速度處理過去 3-9 個月(約 2-3 TB)的數據,並將輸出儲存在特徵商店中。然後,這些特徵會用於輕量級模型進行即時預測,以便在會員登入平台的第一時間推薦相關內容。這種優雅的解決方案可以節省計算資源並顯著降低相關成本,同時提高處理效能。該配置是動態的,允許資料科學家無縫地實驗和部署新模型。
結果
Apache Beam 使 Credit Karma 的數據生態系統具備了可擴展性和彈性,能夠管理由 200 個機器學習模型處理的超過 20,000 個特徵,每天為近 1.3 億會員提供推薦。自採用 Apache Beam 以來,數據處理規模增長了 2 倍,而他們的數據工程團隊無需對基礎設施進行任何重大變更。與使用 Apache Beam 之前需要的數週相比,加入新合作夥伴僅需對管道進行最小的變更。Apache Beam 攝取管道將數據載入資料倉儲的時間從數天縮短到不到一小時,每天處理約 5-10 TB 的數據。Apache Beam 批次評分管道會處理歷史數據,並為輕量級機器學習模型產生特徵,為 Credit Karma 會員實現即時體驗。
Apache Beam 通過抽象化基礎設施的底層細節,並為統一的自助式機器學習工作流程提供數據處理框架,為 Credit Karma 實現端到端的數據科學流程和高效的機器學習工程鋪平了道路。Credit Karma 的數據科學家現在可以試驗新模型,並將其自動部署到生產環境,而無需任何工程資源或基礎設施變更。Credit Karma 在 Beam Summit 2022 上展示了他們使用 Apache Beam 建立自助式數據和機器學習平台以及擴展 MLOps 管道的經驗。
影響
這些可擴展性措施使 Credit Karma 能夠為其會員提供以透明、選擇和個人化為基礎的金融體驗。人們的財務狀況總是在變化,金融機構在批准消費者購買金融產品時的資格標準也是如此,尤其是在經濟不確定時期。隨著 Credit Karma 繼續擴展其數據生態系統,包括自動化的模型更新,會員可以放心,當他們使用 Credit Karma 時,可以更自信地購買金融產品,因為他們知道自己獲得批准的可能性,這為其會員和合作夥伴創造了雙贏的局面,無論時局多麼不明朗。
了解更多
Vega:使用 Apache Beam 和 Dataflow 在 Credit Karma 擴展 MLOps 管道
這個資訊有用嗎?