



部落格
2016/05/27
我的 PCollection.map() 在哪裡?
您是否曾經好奇,為什麼 Beam 對所有事情都使用 PTransforms,而不是在 PCollection 上使用方法?來看看導致此設計決策(以及其他設計決策)的歷史背景。
雖然 Beam 相對較新,但其設計大量借鑒了多年在真實世界管道上的經驗。其中一個主要的靈感來源是 FlumeJava,它是 Google 內部 MapReduce 的後繼者,於 2009 年首次推出。
原始的 FlumeJava API 在 PCollection 上有 count 和 parallelDo 等方法。雖然稍微簡潔一些,但這種方法在可擴展性方面存在許多缺點。每個 FlumeJava 的新用戶都想添加轉換,而將它們作為 PCollection 的方法添加,根本無法很好地擴展。相反,Beam 中的 PCollection 有一個 apply 方法,它接受任何 PTransform 作為參數。
| FlumeJava | Beam |
|---|---|
PCollection<T> input = …
PCollection<O> output = input.count()
.parallelDo(...);
| PCollection<T> input = …
PCollection<O> output = input.apply(Count.perElement())
.apply(ParDo.of(...));
|
這是一種更具可擴展性的方法,原因如下。
在哪裡劃清界線?
在 PCollection 中添加方法,必須在值得這種特殊待遇的「有用」操作和不值得的操作之間劃清界線。很容易為 flat map、group by key 和 combine per key 辯護。但是,filter 呢?Count?Approximate count?Approximate quantiles?Most frequent?WriteToMyFavoriteSource?在這條路上走太遠,會導致一個包含幾乎所有想要做的事情的龐大類別。(FlumeJava 的 PCollection 類別超過 5000 行,包含約 70 個不同的操作,如果我們接受每一個提議,它可能會更大。)此外,由於 Java 不允許向類別添加方法,因此在添加到 PCollection 的操作和未添加到 PCollection 的操作之間存在明顯的語法差異。共享程式碼的傳統方法是使用函式庫,但函式(至少在像 Java 這樣的傳統語言中)是以前綴樣式編寫的,這與流暢的建構器樣式不相符(例如,input.operation1().operation2().operation3() vs. operation3(operation1(input).operation2()))。
相反,在 Beam 中,我們選擇了一種將所有轉換(無論是原始操作、SDK 中捆綁的複合操作,還是外部函式庫的一部分)都置於平等地位的樣式。這也有助於替代實作(甚至可能採用不同的選項),這些實作可以輕鬆互換。
| FlumeJava | Beam |
|---|---|
PCollection<O> output =
ExternalLibrary.doStuff(
MyLibrary.transform(input, myArgs)
.parallelDo(...),
externalLibArgs);
| PCollection<O> output = input
.apply(MyLibrary.transform(myArgs))
.apply(ParDo.of(...))
.apply(ExternalLibrary.doStuff(externalLibArgs));
|
可配置性
讓值(PCollection)成為傳遞和操作的物件(即,延遲執行圖的處理常式)可以形成流暢的樣式,但是操作本身需要是可組合、可配置和可擴展的。將 PCollection 方法用於操作在此處無法很好地擴展,尤其是在沒有預設或關鍵字參數的語言中。例如,ParDo 操作可以有任意數量的側輸入和側輸出,或者寫入操作可能有處理編碼和壓縮的配置。一種選擇是將這些分開為多個重載,甚至方法,但這會加劇上述問題。(FlumeJava 演變出了 parallelDo 方法的十幾個重載!)另一種選擇是向每個方法傳遞一個可以使用更多流暢的慣用語(如建構器模式)建立的配置物件,但在那時,可以將配置物件本身設為操作,這正是 Beam 所做的。
型別安全
許多操作只能應用於元素類型特定的集合。例如,GroupByKey 操作只能應用於 PCollection<KV<K, V>>。至少在 Java 中,不可能僅根據元素類型參數來限制方法。在 FlumeJava 中,這導致我們添加了一個 PTable<K, V> 子類化 PCollection<KV<K, V>>,以包含特定於鍵值對 PCollection 的所有操作。這導致了哪個元素類型足夠特殊到值得被 PCollection 子類別捕獲的問題。對於協力廠商來說,這不是非常可擴展的,並且通常需要手動向下轉型/轉換(這在 Java 中不能安全地鏈式化),以及產生這些 PCollection 特化的特殊操作。
對於產生輸出(其元素類型與其輸入的元素類型相同或相關)的轉換,這尤其不方便,需要額外的支援來產生正確的子類別(例如,對 PTable 的篩選應該產生另一個 PTable,而不僅僅是鍵值對的原始 PCollection)。
使用 PTransforms 允許我們繞過整個問題。我們可以根據其輸入的類型,對可以使用轉換的內容放置任意限制;例如,GroupByKey 是靜態輸入的,只能應用於 PCollection<KV<K, V>>。發生這種情況的方式可以概括為任意形狀,而無需引入像 PTable 這樣的專用類型。
可重複使用性和結構
雖然 PTransforms 通常在它們被使用的地方建構,但通過將它們作為單獨的物件取出,可以儲存它們並傳遞它們。
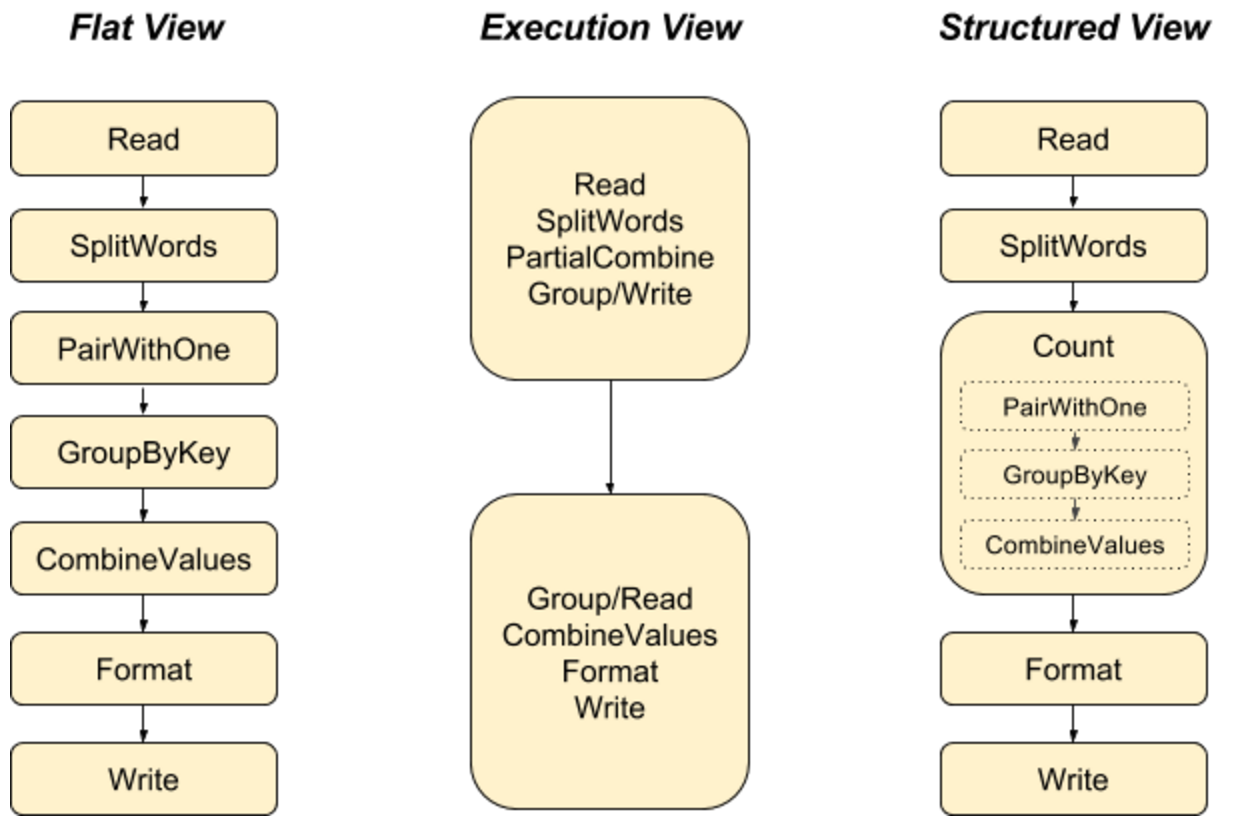
隨著管道的成長和發展,將管道結構化為模組化、通常可重複使用的組件非常有用,而 PTransforms 允許在資料處理管道中很好地執行此操作。此外,模組化 PTransforms 還將程式碼的邏輯結構暴露給系統(例如,用於監控)。在下面的 WordCount 管道的三種不同表示形式中,只有結構化的視圖捕獲了管道的高階意圖。讓即使是簡單的操作也成為 PTransforms,意味著將事物打包到複合操作中時,不會有突然的邊緣。
總結
儘管向 PCollection 添加方法很誘人,但這種方法並不可擴展、不可擴充,或不夠表達。在 PCollection 上放置單個 apply 方法,並將所有邏輯放入操作本身,可以讓我們兩全其美,並通過在簡單和複雜管道之間,以及在預定義和使用者定義操作之間具有單個一致的樣式,來避免複雜性的硬性斷崖。