



部落格
2017/08/28
使用 Apache Beam 進行即時(以及具狀態的)處理
在先前的部落格文章中,我介紹了 Apache Beam 中具狀態處理的基本概念,重點放在將狀態添加到每個元素的處理中。所謂的即時處理,透過讓您設定計時器以在未來某個時間點請求(具狀態的)回呼,來補充 Beam 中的具狀態處理。
您可以使用 Beam 中的計時器做什麼?以下是一些範例
- 您可以在經過一定處理時間後,輸出緩衝在狀態中的資料。
- 當浮水印估計您已收到直到事件時間中指定點的所有資料時,您可以採取特殊動作。
- 您可以撰寫具有逾時的工作流程,這些逾時會在一段時間內沒有其他輸入的情況下,變更狀態並發出輸出。
這些只是一些可能性。狀態和計時器共同形成了一個強大的程式設計範例,可進行細微控制,以表達各種各樣的工作流程。Beam 中的具狀態和即時處理可在資料處理引擎之間移植,並與 Beam 統一的事件時間視窗模型整合,無論是串流處理還是批次處理。
什麼是具狀態和即時處理?
在我先前的文章中,我透過與結合性、交換性組合器的對比,來發展對具狀態處理的理解。在這篇文章中,我將強調一個我僅簡要提及的觀點:可以存取每個鍵和視窗狀態和計時器的元素式處理,代表一種「令人尷尬地平行」計算的基本模式,與 Beam 中的其他模式不同。
事實上,具狀態和即時計算是其他計算的底層計算模式。正是因為它是較低層級的,它允許您真正微觀管理您的計算,以解鎖新的使用案例和新的效率。這會導致手動管理您的狀態和計時器的複雜性 - 這不是魔術!讓我們先再次看看 Beam 中的兩種主要計算模式。
元素式處理 (ParDo、Map 等)
最基本的令人尷尬地平行模式,只是使用一堆電腦將相同的函式應用於大量集合的每個輸入元素。在 Beam 中,像這樣的每個元素處理表示為基本的 ParDo - 類似於 MapReduce 中的「Map」- 它類似於增強的「map」、「flatMap」等,來自函式程式設計。
下圖說明了每個元素的處理。輸入元素是正方形,輸出元素是三角形。元素的顏色代表它們的鍵,這稍後會很重要。每個輸入元素都會完全獨立地對應到對應的輸出元素。處理可以以任何方式分佈在電腦上,產生基本上無限的平行處理能力。
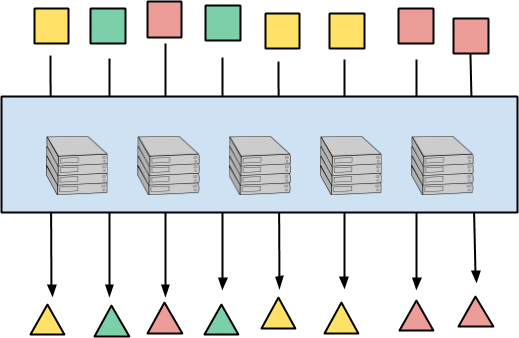
此模式顯而易見,存在於所有資料平行範例中,並且具有簡單的無狀態實作。每個輸入元素都可以獨立或以任意捆綁方式處理。在電腦之間平衡工作實際上是困難的部分,可以透過分割、進度估計、工作竊取等來解決。
每個鍵(和視窗)的彙總 (Combine、Reduce、GroupByKey 等)
Beam 核心的另一個令人尷尬地平行設計模式是每個鍵(和視窗)的彙總。共享鍵的元素會被放在一起,然後使用一些結合性和交換性運算子組合。在 Beam 中,這表示為 GroupByKey 或 Combine.perKey,並對應於 MapReduce 中的 shuffle 和「Reduce」。有時將每個鍵的 Combine 視為基本運算會很有幫助,而原始的 GroupByKey 則只是串連輸入元素的組合器。輸入元素的通訊模式相同,除了 Combine 可能進行的一些最佳化。
在此處的說明中,回想一下每個元素的顏色代表鍵。因此,所有紅色正方形都會路由到同一個位置,它們會在那裡被彙總,而紅色三角形是輸出。黃色和綠色正方形等也是如此。在實際應用中,您可能會有數百萬個鍵,因此平行處理能力仍然很強大。
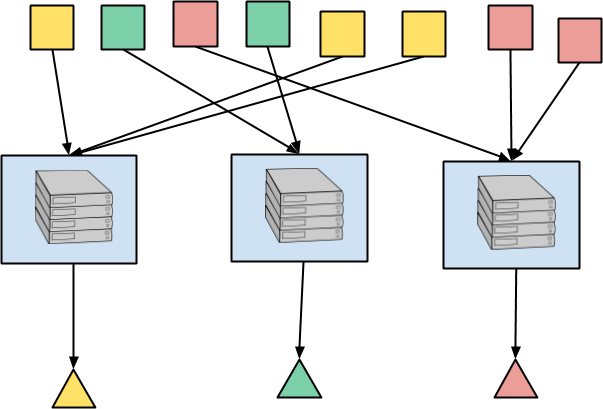
底層資料處理引擎將在某個抽象層級上使用狀態來對到達鍵的所有元素執行此彙總。特別是,在串流執行中,彙總處理可能需要等待更多資料到達,或等待浮水印估計事件時間視窗的所有輸入都已完成。這需要某種方式來儲存輸入元素之間的的中間彙總,以及在應該發出結果時接收回呼的方式。因此,串流處理引擎對每個鍵的彙總的執行,基本上涉及狀態和計時器。
但是,您的程式碼只是彙總運算子的宣告式表達。執行器可以選擇多種方式來執行您的運算子。我在我先前專注於狀態的文章中詳細介紹了這一點。由於您沒有以任何定義的順序觀察元素,也沒有直接操作可變狀態或計時器,所以我稱這既不是具狀態的處理,也不是即時處理。
每個鍵和視窗的具狀態、即時處理
ParDo 和 Combine.perKey 都是可以追溯到數十年前的平行處理標準模式。在大型分散式資料處理引擎中實作這些模式時,我們可以強調一些特別重要的特性。
讓我們考慮 ParDo 的這些特性
- 您撰寫單執行緒程式碼來處理一個元素。
- 元素的處理順序任意,元素處理之間沒有任何相依性或互動。
以及 Combine.perKey 的這些特性
- 會收集具有共同鍵和視窗的元素。
- 使用者定義的運算子會應用於這些元素。
結合不受限制的平行對應和每個鍵和視窗組合的一些特性,我們可以識別出一個巨型原始物件,我們可以用它來建構具狀態和即時處理
- 會收集具有共同鍵和視窗的元素。
- 元素的處理順序任意。
- 您撰寫單執行緒程式碼來處理一個元素或計時器,可能存取狀態或設定計時器。
在下圖中,紅色正方形會被收集,並逐個饋送至具狀態、即時的 DoFn。在處理每個元素時,DoFn 可以存取狀態(右側的顏色分割圓柱體),並可以設定計時器以接收回呼(左側的彩色時鐘)。
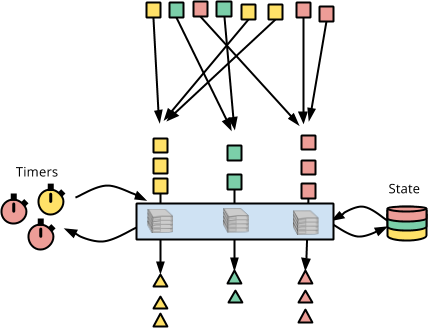
這就是 Apache Beam 中每個鍵和視窗具狀態、即時處理的抽象概念。現在讓我們看看撰寫存取狀態、設定計時器和接收回呼的程式碼是什麼樣子。
範例:批次 RPC
為了示範具狀態和即時處理,讓我們透過一個具體的範例(包含程式碼)進行說明。
假設您正在撰寫一個分析事件的系統。您有大量的資料湧入,並且需要透過 RPC 連線到外部系統來豐富每個事件。您不能只針對每個事件發出一個 RPC。這不僅會嚴重影響效能,而且還可能會超出您在外部系統的配額。因此,您需要收集多個事件,為它們全部發出一個 RPC,然後輸出所有豐富的事件。
狀態
讓我們設定追蹤元素批次所需的狀態。當每個元素進來時,我們將元素寫入緩衝區,同時追蹤我們已緩衝的元素數量。以下是程式碼中的狀態儲存格
new DoFn<Event, EnrichedEvent>() {
@StateId("buffer")
private final StateSpec<BagState<Event>> bufferedEvents = StateSpecs.bag();
@StateId("count")
private final StateSpec<ValueState<Integer>> countState = StateSpecs.value();
… TBD …
}class StatefulBufferingFn(beam.DoFn):
BUFFER_STATE = BagStateSpec('buffer', EventCoder())
COUNT_STATE = CombiningValueStateSpec('count',
VarIntCoder(),
combiners.SumCombineFn())逐步檢查程式碼,我們有
- 狀態儲存格
"buffer"是緩衝事件的無序袋。 - 狀態儲存格
"count"追蹤已緩衝的事件數量。
接下來,作為讀取和寫入狀態的回顧,讓我們撰寫 @ProcessElement 方法。我們將選擇緩衝區大小的限制,MAX_BUFFER_SIZE。如果我們的緩衝區達到此大小,我們將執行單個 RPC 來豐富所有事件並輸出。
new DoFn<Event, EnrichedEvent>() {
private static final int MAX_BUFFER_SIZE = 500;
@StateId("buffer")
private final StateSpec<BagState<Event>> bufferedEvents = StateSpecs.bag();
@StateId("count")
private final StateSpec<ValueState<Integer>> countState = StateSpecs.value();
@ProcessElement
public void process(
ProcessContext context,
@StateId("buffer") BagState<Event> bufferState,
@StateId("count") ValueState<Integer> countState) {
int count = firstNonNull(countState.read(), 0);
count = count + 1;
countState.write(count);
bufferState.add(context.element());
if (count >= MAX_BUFFER_SIZE) {
for (EnrichedEvent enrichedEvent : enrichEvents(bufferState.read())) {
context.output(enrichedEvent);
}
bufferState.clear();
countState.clear();
}
}
… TBD …
}class StatefulBufferingFn(beam.DoFn):
MAX_BUFFER_SIZE = 500;
BUFFER_STATE = BagStateSpec('buffer', EventCoder())
COUNT_STATE = CombiningValueStateSpec('count',
VarIntCoder(),
combiners.SumCombineFn())
def process(self, element,
buffer_state=beam.DoFn.StateParam(BUFFER_STATE),
count_state=beam.DoFn.StateParam(COUNT_STATE)):
buffer_state.add(element)
count_state.add(1)
count = count_state.read()
if count >= MAX_BUFFER_SIZE:
for event in buffer_state.read():
yield event
count_state.clear()
buffer_state.clear()以下是程式碼的說明
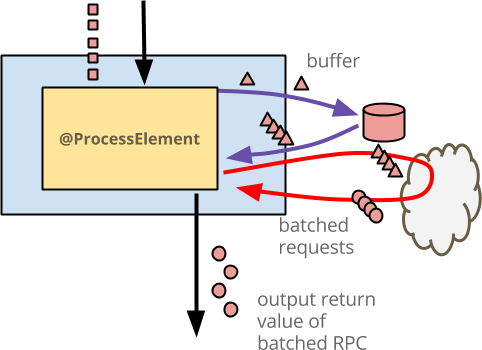
- 藍色方塊是
DoFn。 - 其中的黃色方塊是
@ProcessElement方法。 - 每個輸入事件都是一個紅色正方形 - 此圖僅顯示單一鍵的活動,以紅色表示。您的
DoFn將針對所有鍵(可能是使用者 ID)平行執行相同的工作流程。 - 每個輸入事件都會以紅色三角形的形式寫入緩衝區,表示事實上您可能會緩衝的不僅僅是原始輸入,即使此程式碼沒有這麼做。
- 外部服務會繪製成雲端。當有足夠的緩衝事件時,
@ProcessElement方法會從狀態讀取事件,並發出單個 RPC。 - 每個輸出的豐富事件都會繪製成紅色圓圈。對於此輸出的消費者來說,它看起來就像一個元素式操作。
到目前為止,我們僅使用了狀態,但沒有使用計時器。您可能已經注意到一個問題 - 緩衝區中通常會留下資料。如果沒有其他輸入到達,這些資料將永遠不會被處理。在 Beam 中,每個視窗在事件時間中都有一個時間點,當該時間點視窗的任何進一步輸入都過晚,並且會被捨棄。在這一點上,我們說視窗已「過期」。由於無法再有其他輸入到達來存取該視窗的狀態,因此該狀態也會被捨棄。對於我們的範例,我們需要確保當視窗過期時,會輸出所有剩餘事件。
事件時間計時器
事件時間計時器會在輸入 PCollection 的水位線達到某個閾值時請求回呼。換句話說,您可以使用事件時間計時器在事件時間的特定時刻(即 PCollection 的特定完整點)執行動作,例如在視窗過期時。
在我們的範例中,讓我們加入一個事件時間計時器,以便在視窗過期時處理緩衝區中剩餘的任何事件。
new DoFn<Event, EnrichedEvent>() {
…
@TimerId("expiry")
private final TimerSpec expirySpec = TimerSpecs.timer(TimeDomain.EVENT_TIME);
@ProcessElement
public void process(
ProcessContext context,
BoundedWindow window,
@StateId("buffer") BagState<Event> bufferState,
@StateId("count") ValueState<Integer> countState,
@TimerId("expiry") Timer expiryTimer) {
expiryTimer.set(window.maxTimestamp().plus(allowedLateness));
… same logic as above …
}
@OnTimer("expiry")
public void onExpiry(
OnTimerContext context,
@StateId("buffer") BagState<Event> bufferState) {
if (!bufferState.isEmpty().read()) {
for (EnrichedEvent enrichedEvent : enrichEvents(bufferState.read())) {
context.output(enrichedEvent);
}
bufferState.clear();
}
}
}class StatefulBufferingFn(beam.DoFn):
…
EXPIRY_TIMER = TimerSpec('expiry', TimeDomain.WATERMARK)
def process(self, element,
w=beam.DoFn.WindowParam,
buffer_state=beam.DoFn.StateParam(BUFFER_STATE),
count_state=beam.DoFn.StateParam(COUNT_STATE),
expiry_timer=beam.DoFn.TimerParam(EXPIRY_TIMER)):
expiry_timer.set(w.end + ALLOWED_LATENESS)
… same logic as above …
@on_timer(EXPIRY_TIMER)
def expiry(self,
buffer_state=beam.DoFn.StateParam(BUFFER_STATE),
count_state=beam.DoFn.StateParam(COUNT_STATE)):
events = buffer_state.read()
for event in events:
yield event
buffer_state.clear()
count_state.clear()讓我們分解一下這個程式碼片段的各個部分
我們使用
@TimerId("expiry")宣告一個事件時間計時器。我們將使用識別符"expiry"來識別計時器,以便設定回呼時間以及接收回呼。使用
@TimerId註解的變數expiryTimer設定為TimerSpecs.timer(TimeDomain.EVENT_TIME)的值,表示我們希望根據輸入元素的事件時間水位線進行回呼。在
@ProcessElement元素中,我們註解一個參數@TimerId("expiry") Timer。Beam 執行器會自動提供此Timer參數,我們可以使用它來設定(和重設)計時器。重複重設計時器並不會耗費太多資源,因此我們只需在每個元素上設定它即可。我們定義了
onExpiry方法,並使用@OnTimer("expiry")進行註解,該方法會執行最終的事件擴充 RPC 並輸出結果。Beam 執行器會透過匹配其識別符將回呼傳遞給此方法。
為了說明此邏輯,我們有以下圖表
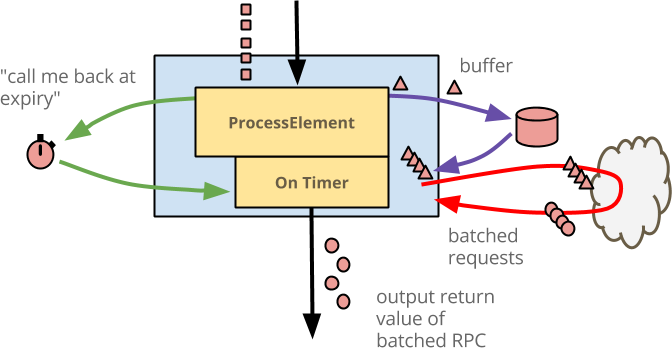
@ProcessElement 和 @OnTimer("expiry") 方法都執行相同的緩衝狀態存取、執行相同的批次 RPC,並輸出擴充後的元素。
現在,如果我們以串流即時方式執行此操作,特定緩衝資料的延遲可能仍然是無限的。如果水位線移動非常緩慢,或者事件時間視窗選擇得非常大,那麼在根據足夠的元素或視窗過期發出輸出之前,可能會經過很長一段時間。我們也可以使用計時器來限制處理緩衝元素之前的實際時間(又稱處理時間)。我們可以選擇一些合理的時間量,以便即使我們發出的 RPC 沒有那麼大,仍然足以避免超出外部服務的配額。
處理時間計時器
處理時間(在管道執行時經過的時間)中的計時器直觀上很簡單:您想要等待一段時間,然後接收回呼。
為了完成我們的範例,我們會在任何資料被緩衝時立即設定一個處理時間計時器。請注意,我們僅在目前緩衝區為空時才設定計時器,這樣我們就不會不斷重設計時器。當第一個元素到達時,我們會將計時器設定為當前時刻加上 MAX_BUFFER_DURATION。在分配的處理時間過去後,將會觸發回呼,並擴充和發出任何緩衝的元素。
new DoFn<Event, EnrichedEvent>() {
…
private static final Duration MAX_BUFFER_DURATION = Duration.standardSeconds(1);
@TimerId("stale")
private final TimerSpec staleSpec = TimerSpecs.timer(TimeDomain.PROCESSING_TIME);
@ProcessElement
public void process(
ProcessContext context,
BoundedWindow window,
@StateId("count") ValueState<Integer> countState,
@StateId("buffer") BagState<Event> bufferState,
@TimerId("stale") Timer staleTimer,
@TimerId("expiry") Timer expiryTimer) {
if (firstNonNull(countState.read(), 0) == 0) {
staleTimer.offset(MAX_BUFFER_DURATION).setRelative();
}
… same processing logic as above …
}
@OnTimer("stale")
public void onStale(
OnTimerContext context,
@StateId("buffer") BagState<Event> bufferState,
@StateId("count") ValueState<Integer> countState) {
if (!bufferState.isEmpty().read()) {
for (EnrichedEvent enrichedEvent : enrichEvents(bufferState.read())) {
context.output(enrichedEvent);
}
bufferState.clear();
countState.clear();
}
}
… same expiry as above …
}class StatefulBufferingFn(beam.DoFn):
…
STALE_TIMER = TimerSpec('stale', TimeDomain.REAL_TIME)
MAX_BUFFER_DURATION = 1
def process(self, element,
w=beam.DoFn.WindowParam,
buffer_state=beam.DoFn.StateParam(BUFFER_STATE),
count_state=beam.DoFn.StateParam(COUNT_STATE),
expiry_timer=beam.DoFn.TimerParam(EXPIRY_TIMER),
stale_timer=beam.DoFn.TimerParam(STALE_TIMER)):
if count_state.read() == 0:
# We set an absolute timestamp here (not an offset like in the Java SDK)
stale_timer.set(time.time() + StatefulBufferingFn.MAX_BUFFER_DURATION)
… same logic as above …
@on_timer(STALE_TIMER)
def stale(self,
buffer_state=beam.DoFn.StateParam(BUFFER_STATE),
count_state=beam.DoFn.StateParam(COUNT_STATE)):
events = buffer_state.read()
for event in events:
yield event
buffer_state.clear()
count_state.clear()以下是最終程式碼的說明
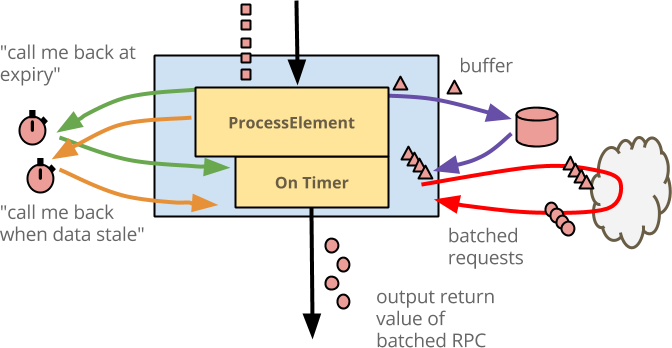
回顧整個邏輯
- 當事件到達
@ProcessElement時,它們會被緩衝在狀態中。 - 如果緩衝區的大小超過上限,則會擴充事件並輸出。
- 如果緩衝區填滿的速度太慢,並且事件在達到上限之前變得過時,則計時器會導致回呼,該回呼會擴充緩衝的事件並輸出。
- 最後,當任何視窗過期時,該視窗中緩衝的任何事件都會在該視窗的狀態被捨棄之前進行處理並輸出。
最後,我們有一個完整的範例,該範例使用狀態和計時器來明確管理 Beam 中效能敏感轉換的底層細節。隨著我們添加越來越多的功能,我們的 DoFn 實際上變得相當大。這是有狀態的即時處理的正常特徵。您真的深入研究並管理許多細節,而當您使用 Beam 的較高層級 API 來表達邏輯時,這些細節會自動處理。您從這種額外努力中獲得的是處理使用案例和實現效率的能力,否則這些能力可能無法實現。
Beam 統一模型中的狀態和計時器
Beam 在串流和批次處理之間針對事件時間的統一模型對狀態和計時器有著新的含義。通常,您不需要對有狀態和即時的 DoFn 進行任何操作,即可使其在 Beam 模型中良好地運作。但是,了解以下注意事項將會有所幫助,特別是如果您以前在 Beam 之外使用過類似的功能。
事件時間視窗化「開箱即用」
Beam 存在的原因之一是正確處理亂序的事件資料,而這幾乎是所有事件資料。Beam 解決亂序資料的方案是事件時間視窗化,其中事件時間中的視窗無論使用者選擇什麼視窗化方式或事件以什麼順序進入,都會產生正確的結果。
如果您編寫有狀態的即時轉換,則無論周圍的管道如何選擇視窗化事件時間,它都應該可以運作。如果管道選擇一小時的固定視窗(有時稱為滾動視窗)或 30 分鐘滑動 10 分鐘的視窗,則有狀態的即時轉換應透明地正確運作。
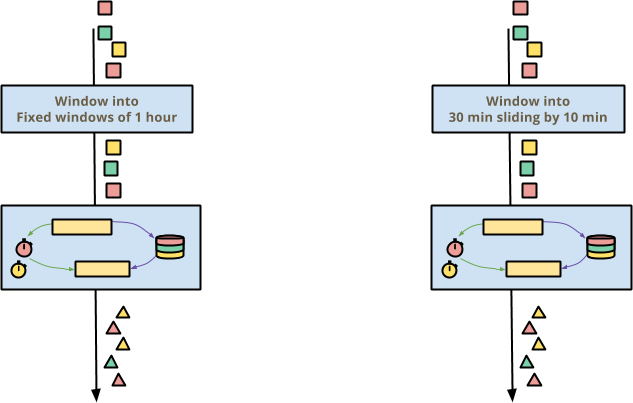
這在 Beam 中會自動運作,因為狀態和計時器會按鍵和視窗進行分割。在每個鍵和視窗內,有狀態的即時處理基本上是獨立的。此外,事件時間的流逝(即水位線的推進)允許在視窗過期時自動釋放無法存取的狀態,因此您通常不必擔心清除舊狀態。
統一的即時和歷史處理
Beam 語義模型的第二個原則是,批次處理和串流處理之間必須統一。此統一的一個重要用例是能夠將相同的邏輯應用於即時事件流和相同事件的封存儲存。
封存資料的一個常見特徵是,它可能會以完全亂序的方式到達。封存檔案的分片通常會導致處理的順序與近即時傳入的事件完全不同。從管道的角度來看,資料也會全部可用,因此會立即傳送。無論是針對過去的資料執行實驗還是重新處理過去的結果以修正資料處理錯誤,您的處理邏輯都必須能夠像應用於近即時傳入的資料一樣輕鬆地應用於封存的事件,這至關重要。
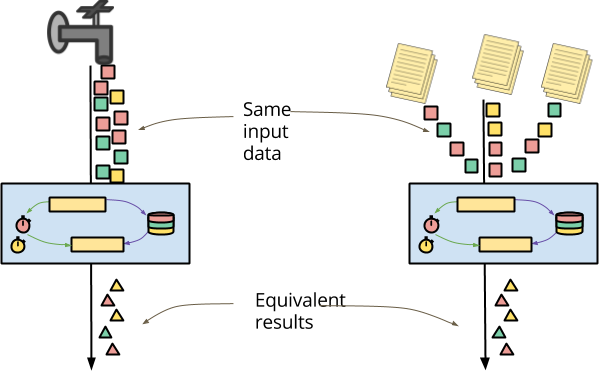
(故意地)可以編寫一個有狀態且即時的 DoFn,它會傳回取決於順序或傳遞時間的結果,因此從這個意義上來說,您(即 DoFn 作者)有額外的責任來確保這種不確定性落在記錄的允許範圍內。
開始使用吧!
我將以與上一篇貼文相同的方式結束這篇貼文。我希望您會嘗試使用 Beam 進行有狀態的即時處理。如果它為您開啟了新的可能性,那就太好了!如果沒有,我們希望聽到您的意見。由於這是一項新功能,請查看功能矩陣,以了解您偏好的 Beam 後端的支援層級。
並且請加入 Beam 社群,網址為user@beam.apache.org,並在 Twitter 上追蹤 @ApacheBeam。