



部落格
2017/02/13
使用 Apache Beam 的有狀態處理
Beam 讓您可以使用可攜式高階管線處理無界、亂序、全球規模的資料。有狀態處理是 Beam 模型的新功能,擴展了 Beam 的功能,解鎖了新的使用案例和新的效率。在這篇文章中,我將引導您了解 Beam 中的有狀態處理:它的運作方式、它如何與 Beam 模型的其他功能配合、您可能會用它來做什麼,以及它在程式碼中的樣子。
注意:這篇文章已於 2019 年 5 月更新,以包含 Python 片段!
警告:前方有新功能!:這是 Beam 模型的一個非常新的方面。執行器仍在新增支援。您今天可以在多個執行器上試用它,但請查看執行器功能矩陣,以了解每個執行器的目前狀態。
首先,快速回顧一下:在 Beam 中,一個大資料處理管線是一個有向、非循環的平行操作圖,稱為PTransforms,處理來自PCollections的資料。我將透過逐步說明這個範例來擴展這一點
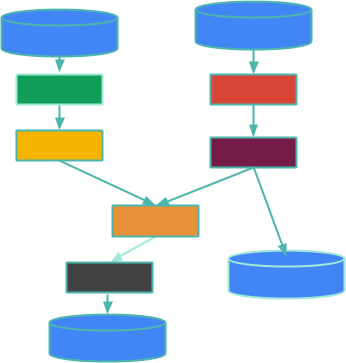
這些方塊是 PTransforms,邊緣代表 PCollections 中從一個 PTransform 流向另一個 PTransform 的資料。PCollection 可能是有界的(表示它是有限的,而且您知道它)或無界的(表示您不知道它是否有限 - 基本上,它就像一個傳入的資料串流,可能永遠不會終止)。這些圓柱體是管線邊緣的資料來源和接收器,例如記錄檔的有界集合或透過 Kafka 主題串流的無界資料。這篇部落格文章不是關於來源或接收器,而是關於介於兩者之間的處理 - 您的資料處理。
在 Beam 中處理資料有兩個主要的建構區塊:ParDo,用於跨所有元素平行執行操作,以及 GroupByKey(以及我很快會談到的密切相關的 CombinePerKey),用於聚合您已指定相同金鑰的元素。在下圖(我們許多簡報中都有)中,顏色表示元素的金鑰。因此,GroupByKey/CombinePerKey 轉換會收集所有綠色方塊以產生單一輸出元素。
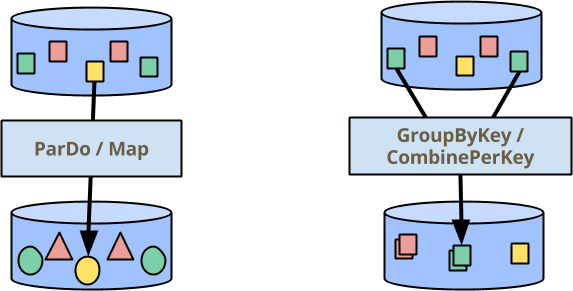
但並非所有使用案例都容易表達為簡單的 ParDo/Map 和 GroupByKey/CombinePerKey 轉換的管線。這篇部落格文章的主題是 Beam 程式設計模型的新擴展:透過可變狀態增強的每個元素操作。
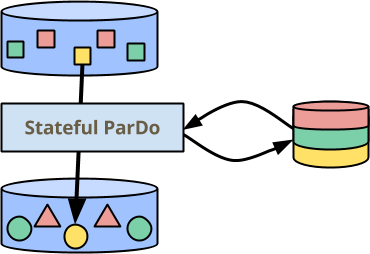
在上圖中,ParDo 現在在側邊具有一些持久的、一致的狀態,可以在處理每個元素期間讀取和寫入。狀態會依金鑰分割,因此會繪製為每個顏色都有不相交的部分。它也會依視窗分割,但我認為格子 ![]() 有點過多了 :-) 。我稍後會透過我的第一個範例談談為什麼狀態會以這種方式分割。
有點過多了 :-) 。我稍後會透過我的第一個範例談談為什麼狀態會以這種方式分割。
在這篇文章的剩餘部分,我將詳細描述 Beam 的這個新功能 - 它在高階層次上的運作方式、它與現有功能的不同之處、如何確保它仍然具有大規模的可擴展性。在模型層次介紹之後,我將逐步說明如何在 Beam Java SDK 中使用它的簡單範例。
Beam 中的有狀態處理如何運作?
您的 ParDo 轉換的處理邏輯是透過它應用於每個元素的 DoFn 來表示的。在沒有有狀態增強的情況下,DoFn 主要是一個從輸入到一個或多個輸出的純函數,對應於 MapReduce 中的 Mapper。有了狀態,DoFn 能夠在處理每個輸入元素時存取持久的可變狀態。請考慮這個範例
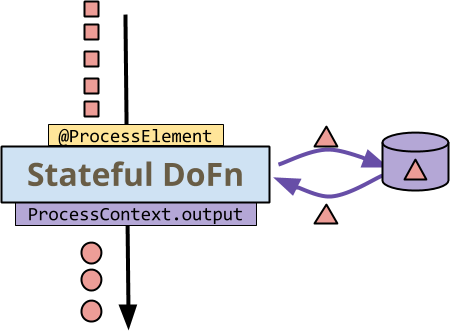
首先要注意的是,所有資料 - 小方塊、圓圈和三角形 - 都是紅色的。這是為了說明有狀態處理發生在單一金鑰的環境中 - 所有元素都是具有相同金鑰的金鑰值對。從您選擇的 Beam 執行器呼叫 DoFn 會以黃色著色,而從 DoFn 呼叫執行器則以紫色著色
- 執行器會針對金鑰 + 視窗中的每個元素調用
DoFn的@ProcessElement方法。 DoFn會讀取和寫入狀態 - 往返側邊儲存的彎曲箭頭。DoFn會透過ProcessContext.output(resp.ProcessContext.sideOutput) 像往常一樣將輸出(或側邊輸出)發送到執行器。
在這個非常高的層次上,它非常直觀:在您的程式設計經驗中,您可能在某個時候編寫了一個迴圈來處理元素,該迴圈會在執行其他動作時更新一些可變變數。有趣的問題是,它如何融入 Beam 模型:它如何與其他功能相關?它如何擴展,因為狀態表示某些同步?應該在何時使用它,而不是其他功能?
有狀態處理如何融入 Beam 模型?
要了解有狀態處理在 Beam 模型中的位置,請考慮另一種在處理許多元素時可以保留某些「狀態」的方式:CombineFn。在 Beam 中,您可以在 Java 或 Python 中編寫 Combine.perKey(CombineFn),以在具有通用金鑰(和視窗)的所有元素上應用關聯、可交換的累積操作。
這是一個說明 CombineFn 基本知識的圖表,執行器可能在每個金鑰的基礎上調用它的最簡單方法,以建立累加器並從最終累加器中擷取輸出
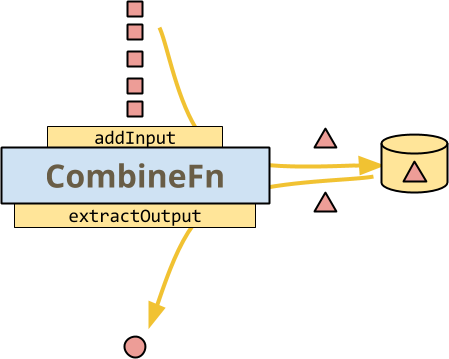
與有狀態 DoFn 的範例一樣,所有資料都以紅色著色,因為這是處理單一金鑰的 Combine。圖示的方法呼叫以黃色著色,因為它們都由執行器控制:執行器會在每個方法上調用 addInput,將其新增至目前的累加器。
- 執行器會在選擇時保存累加器。
- 執行器會在準備好發出輸出元素時呼叫
extractOutput。
此時,CombineFn 的圖表看起來很像有狀態 DoFn 的圖表。實際上,資料流程確實非常相似。但即便如此,仍有重要的差異
- 執行器會在這裡控制所有調用和儲存。您不會決定何時或如何保存狀態、何時捨棄累加器(基於觸發)或何時從累加器中擷取輸出。
- 您只能有一個狀態 - 累加器。在有狀態的 DoFn 中,您只能讀取您需要知道的內容,而只寫入已變更的內容。
- 您沒有
DoFn的擴展功能,例如每個輸入的多個輸出或側邊輸出。(這些可以透過足夠複雜的累加器來模擬,但它不會自然或有效率。DoFn的某些其他功能,例如側邊輸入和存取視窗,對於CombineFn來說是完全合理的)
但 CombineFn 允許執行器執行的主要操作是 mergeAccumulators,CombineFn 的關聯性的具體表達。這解鎖了一些巨大的最佳化:執行器可以在多個輸入上調用多個 CombineFn 實例,然後在經典的分而治之架構中合併它們,如下圖所示
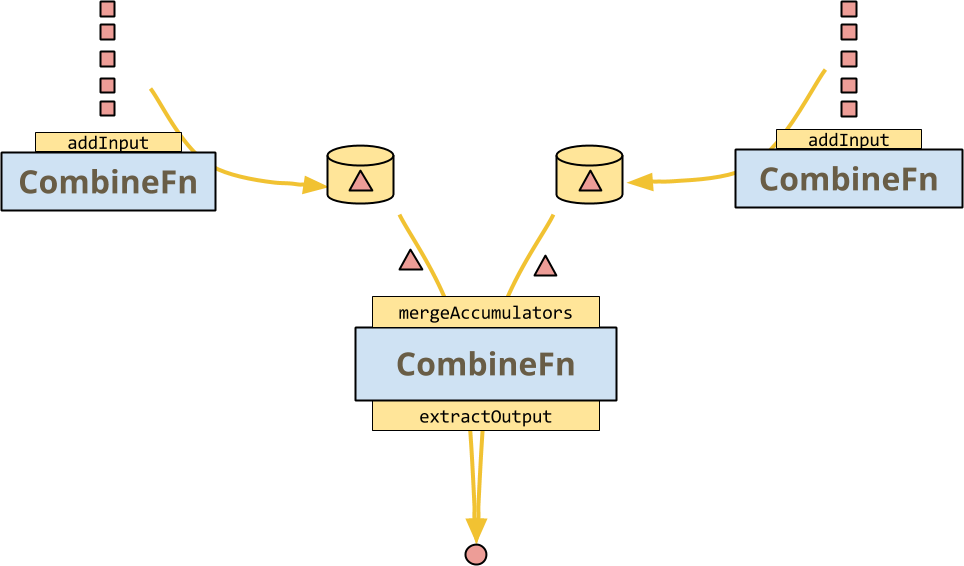
CombineFn 的合約是,無論執行器是否決定實際執行這種操作,或甚至是具有熱金鑰扇出的更複雜的樹狀結構等等,結果都應該完全相同。
有狀態的 DoFn 不(一定)會提供此合併操作:執行器無法自由地分支其執行並重新組合狀態。請注意,輸入元素仍然以任意順序接收,因此 DoFn 應對排序和捆綁不敏感,但這並不表示輸出必須完全相同。(有趣且簡單的事實:如果輸出實際上始終相等,那麼 DoFn 就是一個關聯且可交換的運算子)
現在您可以看到有狀態的 DoFn 與 CombineFn 的不同之處,但我想退後一步,將其推斷到一個高階畫面,了解 Beam 中的狀態如何與使用其他功能達到相同或相似目標相關:在許多情況下,有狀態處理所代表的是一個「深入了解」Beam 的高度抽象、主要確定性的函數式範例,並執行可能是不確定的強制式程式設計,而這種程式設計很難以其他方式表示。
範例:任意但一致的索引指派
假設您想要為每個傳入的鍵和視窗元素賦予索引。您不關心索引是什麼,只要它們是獨一無二且一致的即可。在深入探討如何在 Beam SDK 中執行此操作的程式碼之前,我將從模型的層面來探討這個範例。以圖片來說,您想要編寫一個轉換,將輸入映射到如下的輸出
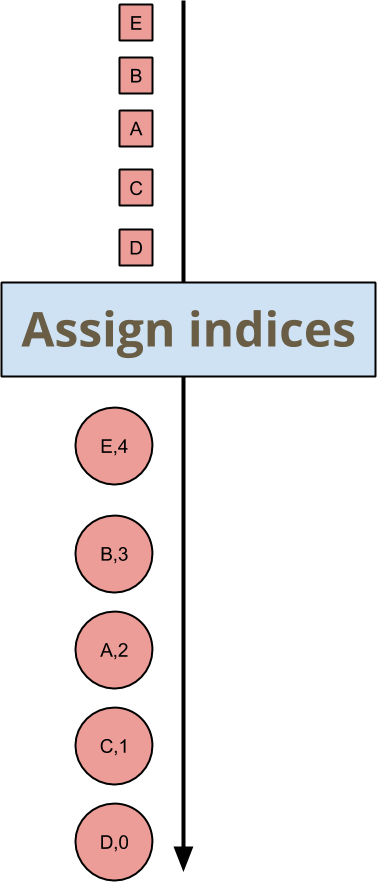
元素 A、B、C、D、E 的順序是任意的,因此它們被指派的索引也是任意的,但下游轉換只需要接受這一點即可。就實際值而言,沒有結合律或交換律。這種轉換的順序不敏感性僅延伸到確保輸出必要的屬性:沒有重複的索引、沒有間隙,並且每個元素都有一個索引。
從概念上將其表達為有狀態的迴圈非常簡單:您應該儲存的狀態是下一個索引。
- 當元素進入時,將其與下一個索引一起輸出。
- 遞增索引。
這提供了一個很好的機會來談論大數據和並行性,因為這些要點中的演算法根本無法並行化!如果您想將此邏輯應用於整個 PCollection,則必須一次處理 PCollection 的每個元素…這顯然不是一個好主意。Beam 中的狀態範圍很小,因此大多數情況下,執行器仍然可以並行執行有狀態的 ParDo 轉換,儘管您仍然需要仔細考慮它。
Beam 中的狀態單元範圍限定為鍵+視窗對。當您的 DoFn 透過名稱 "index" 讀取或寫入狀態時,它實際上是存取由 "index" *以及*目前正在處理的鍵和視窗指定的變更單元。因此,在考慮狀態單元時,將轉換的完整狀態視為表格可能會有所幫助,其中列根據您在程式中使用的名稱命名,例如 "index",而欄是鍵+視窗對,如下所示
| (鍵, 視窗)1 | (鍵, 視窗)2 | (鍵, 視窗)3 | … | |
|---|---|---|---|---|
"index" | 3 | 7 | 15 | … |
"fizzOrBuzz?" | "fizz" | "7" | "fizzbuzz" | … |
| … | … | … | … | … |
(如果您有超強的空間感,請隨意將其想像成立方體,其中鍵和視窗是獨立的維度)
您可以透過確保表格具有足夠的欄來提供並行處理的機會。您可能有很多鍵和很多視窗,或者您可能只有其中一個
- 在少數視窗中有很多鍵,例如按使用者 ID 鍵控的全域視窗化狀態計算。
- 在少數鍵上有很多視窗,例如對全域鍵進行的固定視窗化狀態計算。
注意事項:目前所有 Beam 執行器都只針對鍵進行並行處理。
大多數情況下,您的狀態心智模型可以僅專注於表格的單一欄,即單一的鍵+視窗對。根據設計,跨欄互動不會直接發生。
Beam Java SDK 中的狀態
現在我已經談論了一些關於 Beam 模型中的有狀態處理,並透過一個抽象範例進行了說明,我想向您展示如何使用 Beam 的 Java SDK 編寫有狀態處理程式碼。以下是一個有狀態 DoFn 的程式碼,它在每個鍵和視窗的基礎上為每個元素指派一個任意但一致的索引
new DoFn<KV<MyKey, MyValue>, KV<Integer, KV<MyKey, MyValue>>>() {
// A state cell holding a single Integer per key+window
@StateId("index")
private final StateSpec<ValueState<Integer>> indexSpec =
StateSpecs.value(VarIntCoder.of());
@ProcessElement
public void processElement(
ProcessContext context,
@StateId("index") ValueState<Integer> index) {
int current = firstNonNull(index.read(), 0);
context.output(KV.of(current, context.element()));
index.write(current+1);
}
}class IndexAssigningStatefulDoFn(DoFn):
INDEX_STATE = CombiningStateSpec('index', sum)
def process(self, element, index=DoFn.StateParam(INDEX_STATE)):
unused_key, value = element
current_index = index.read()
yield (value, current_index)
index.add(1)讓我們來剖析一下
- 首先要注意的是存在幾個
@StateId("index")注釋。這表示您在此DoFn中使用名為「index」的可變狀態單元。Beam Java SDK,以及您選擇的執行器,也會注意到這些注釋並使用它們來正確連結您的 DoFn。 - 第一個
@StateId("index")注釋在StateSpec類型的欄位上(表示「狀態規格」)。這會宣告和配置狀態單元。類型參數ValueState描述您可以從此單元中取得的狀態類型 -ValueState只儲存單一值。請注意,規格本身不是可用的狀態單元 - 您需要在管道執行期間由執行器提供。 - 若要完整指定
ValueState單元,您需要提供執行器將使用的編碼器(必要時)來序列化您將儲存的值。這是StateSpecs.value(VarIntCoder.of())的調用。 - 第二個
@StateId("index")注釋位於您的@ProcessElement方法的參數上。這表示存取先前指定的 ValueState 單元。 - 狀態以最簡單的方式存取:
read()讀取它,而write(newvalue)寫入它。 DoFn的其他功能可以像往常一樣使用 - 例如context.output(...)。您也可以使用側輸入、側輸出、存取視窗等。
關於 SDK 和執行器如何看待此 DoFn 的一些注意事項
- 您的狀態單元都已明確宣告,因此 Beam SDK 或執行器可以推斷它們,例如在視窗過期時清除它們。
- 如果您宣告一個狀態單元,然後使用錯誤的類型來使用它,Beam Java SDK 會為您捕獲該錯誤。
- 如果您宣告兩個具有相同 ID 的狀態單元,SDK 也會捕獲該錯誤。
- 執行器知道這是一個有狀態的
DoFn,並且可能會以截然不同的方式執行它,例如透過額外的資料洗牌和同步來避免同時存取狀態單元。
讓我們看看另一個如何使用此 API 的範例,這次更接近真實世界。
範例:異常偵測
假設您正在將使用者採取的動作串流輸入到一些複雜模型中,以預測他們採取的動作的某種定量表達,例如偵測詐欺活動。您將從事件建立模型,並將傳入的事件與最新的模型進行比較,以判斷是否有任何變更。
如果您嘗試將模型的建立表示為 CombineFn,您可能會在 mergeAccumulators 中遇到問題。假設您可以表達該模型,它可能看起來像這樣
class ModelFromEventsFn extends CombineFn<Event, Model, Model> {
@Override
public abstract Model createAccumulator() {
return Model.empty();
}
@Override
public abstract Model addInput(Model accumulator, Event input) {
return accumulator.update(input); // this is encouraged to mutate, for efficiency
}
@Override
public abstract Model mergeAccumulators(Iterable<Model> accumulators) {
// ?? can you write this ??
}
@Override
public abstract Model extractOutput(Model accumulator) {
return accumulator; }
}class ModelFromEventsFn(apache_beam.core.CombineFn):
def create_accumulator(self):
# Create a new empty model
return Model()
def add_input(self, model, input):
return model.update(input)
def merge_accumulators(self, accumulators):
# Custom merging logic
def extract_output(self, model):
return model現在,您有一種方法可以將特定使用者在視窗中的模型計算為 Combine.perKey(new ModelFromEventsFn())。您將如何將此模型應用於計算該模型的同一個事件串流?一種標準的方法是取得 Combine 轉換的結果,並在處理 PCollection 的元素時使用它,方法是將其讀取為 ParDo 轉換的側輸入。因此,您可以側向輸入模型,並根據該模型檢查事件串流,並輸出預測,如下所示
PCollection<KV<UserId, Event>> events = ...
final PCollectionView<Map<UserId, Model>> userModels = events
.apply(Combine.perKey(new ModelFromEventsFn()))
.apply(View.asMap());
PCollection<KV<UserId, Prediction>> predictions = events
.apply(ParDo.of(new DoFn<KV<UserId, Event>>() {
@ProcessElement
public void processElement(ProcessContext ctx) {
UserId userId = ctx.element().getKey();
Event event = ctx.element().getValue();
Model model = ctx.sideinput(userModels).get(userId);
// Perhaps some logic around when to output a new prediction
… c.output(KV.of(userId, model.prediction(event))) …
}
}));# Events is a collection of (user, event) pairs.
events = (p | ReadFromEventSource() | beam.WindowInto(....))
user_models = beam.pvalue.AsDict(
events
| beam.core.CombinePerKey(ModelFromEventsFn()))
def event_prediction(user_event, models):
user = user_event[0]
event = user_event[1]
# Retrieve the model calculated for this user
model = models[user]
return (user, model.prediction(event))
# Predictions is a collection of (user, prediction) pairs.
predictions = events | beam.Map(event_prediction, user_models)在這個管道中,每個使用者、每個視窗只會從 Combine.perKey(...) 發出一個模型,然後由 View.asMap() 轉換準備進行側向輸入。ParDo 對事件的處理將會封鎖,直到該側輸入準備就緒,緩衝事件,然後根據模型檢查每個事件。這是一種高延遲、高完整性的解決方案:模型會考量視窗中的所有使用者行為,但在視窗完成之前無法有任何輸出。
假設您想要更早取得一些結果,或者甚至沒有任何自然視窗化,而只是想要使用「目前為止的模型」進行持續分析,即使您的模型可能不完整。您如何控制您正在檢查事件的模型的更新?觸發器是 Beam 的通用功能,用於管理完整性與延遲之間的權衡。因此,以下是具有新增觸發器的相同管道,該觸發器會在輸入到達後一秒鐘輸出新的模型
PCollection<KV<UserId, Event>> events = ...
PCollectionView<Map<UserId, Model>> userModels = events
// A tradeoff between latency and cost
.apply(Window.triggering(
AfterProcessingTime.pastFirstElementInPane(Duration.standardSeconds(1)))
.apply(Combine.perKey(new ModelFromEventsFn()))
.apply(View.asMap());events = ...
user_models = beam.pvalue.AsDict(
events
| beam.WindowInto(GlobalWindows(),
trigger=trigger.AfterAll(
trigger.AfterCount(1),
trigger.AfterProcessingTime(1)))
| beam.CombinePerKey(ModelFromEventsFn()))這通常是在延遲和成本之間取得不錯的權衡:如果一秒鐘內湧入大量事件,那麼您只會發出一個新的模型,因此您不會被過時前甚至無法使用的模型輸出所淹沒。實際上,由於快取和準備側輸入的處理延遲,新的模型可能要過幾秒鐘後才會出現在側輸入通道上。許多事件(可能是一整批活動)將已通過 ParDo,並且已根據先前的模型計算其預測。如果執行器對快取過期提供了足夠嚴格的限制,並且您使用了更積極的觸發器,您或許能夠以額外的成本來改善延遲。
但還有另一個需要考慮的成本:您正在從 ParDo 輸出許多不有趣的輸出,這些輸出將在下游處理。如果輸出的「有趣程度」僅相對於先前的輸出有明確的定義,則您無法使用 Filter 轉換來減少下游的資料量。
有狀態處理可讓您解決側輸入的延遲問題,以及過多不有趣輸出的成本問題。以下是程式碼,僅使用我已經介紹的功能
new DoFn<KV<UserId, Event>, KV<UserId, Prediction>>() {
@StateId("model")
private final StateSpec<ValueState<Model>> modelSpec =
StateSpecs.value(Model.coder());
@StateId("previousPrediction")
private final StateSpec<ValueState<Prediction>> previousPredictionSpec =
StateSpecs.value(Prediction.coder());
@ProcessElement
public void processElement(
ProcessContext c,
@StateId("previousPrediction") ValueState<Prediction> previousPredictionState,
@StateId("model") ValueState<Model> modelState) {
UserId userId = c.element().getKey();
Event event = c.element().getValue()
Model model = modelState.read();
Prediction previousPrediction = previousPredictionState.read();
Prediction newPrediction = model.prediction(event);
model.add(event);
modelState.write(model);
if (previousPrediction == null
|| shouldOutputNewPrediction(previousPrediction, newPrediction)) {
c.output(KV.of(userId, newPrediction));
previousPredictionState.write(newPrediction);
}
}
};class ModelStatefulFn(beam.DoFn):
PREVIOUS_PREDICTION = BagStateSpec('previous_pred_state', PredictionCoder())
MODEL_STATE = CombiningValueStateSpec('model_state',
ModelCoder(),
ModelFromEventsFn())
def process(self,
user_event,
previous_pred_state=beam.DoFn.StateParam(PREVIOUS_PREDICTION),
model_state=beam.DoFn.StateParam(MODEL_STATE)):
user = user_event[0]
event = user_event[1]
model = model_state.read()
previous_prediction = previous_pred_state.read()
new_prediction = model.prediction(event)
model_state.add(event)
if (previous_prediction is None
or self.should_output_prediction(
previous_prediction, new_prediction)):
previous_pred_state.clear()
previous_pred_state.add(new_prediction)
yield (user, new_prediction)讓我們逐步了解一下
- 您宣告了兩個狀態單元,
@StateId("model")用於保留使用者的模型目前狀態,而@StateId("previousPrediction")用於保留先前輸出的預測。 - 如前所述,在
@ProcessElement方法中使用注釋存取兩個狀態單元。 - 您透過
modelState.read()讀取目前模型。在每個鍵和視窗中,這是一個僅適用於目前正在處理的事件的使用者 ID 的模型。 - 您會產生一個新的預測
model.prediction(event),並將其與您先前輸出的預測進行比較,該預測可透過previousPredicationState.read()存取。 - 然後,您會更新模型
model.update()並透過modelState.write(...)寫入。只要您還記得寫入已變更的值,則可以完全變更您從狀態中提取的值,就像您被鼓勵變更CombineFn累加器一樣。 - 如果預測自上次輸出以來已發生顯著變化,您會透過
context.output(...)發出它,並使用previousPredictionState.write(...)儲存預測。此處的決定是相對於先前的預測輸出,而不是上次計算的輸出 - 實際上您可能會在此處遇到一些複雜的條件。
以上大部分內容都只是在討論 Java!但在您開始將所有管道轉換為使用有狀態處理之前,我想先介紹一些關於它是否適合您的使用案例的注意事項。
效能考量
若要決定是否使用每個鍵和視窗的狀態,您需要考量其執行方式。您可以深入研究特定執行器如何管理狀態,但有一些一般事項需要牢記
- 每個鍵和視窗的分區:也許最重要的事情是,執行器可能必須對您的資料進行洗牌,才能將特定鍵+視窗的所有資料並置。如果資料已正確洗牌,則執行器可能會利用這一點。
- 同步額外負荷:API 的設計目的是讓執行器負責並行控制,但這表示即使在其他情況下有利,執行器也無法並行處理特定鍵+視窗的元素。
- 狀態的儲存和容錯:由於狀態是針對每個鍵和視窗的,因此您預期同時處理的鍵和視窗越多,就會產生越多的儲存空間。由於狀態受益於 Beam 中其他資料的所有容錯/一致性特性,這也會增加提交處理結果的成本。
- 狀態的過期:同樣由於狀態是針對每個視窗的,當視窗過期(當水位線超過其允許的延遲時間)時,執行器可以回收資源,但這可能意味著執行器正在追蹤每個鍵和視窗的額外計時器,以觸發回收程式碼的執行。
快去使用吧!
如果您是 Beam 的新手,我希望您現在有興趣看看具有狀態處理的 Beam 是否能解決您的使用案例。如果您已經在使用 Beam,我希望這個模型的新增功能能為您開啟新的使用案例。請查看功能矩陣,以了解您喜愛的後端對此新模型功能的支援程度。
請加入我們的社群:user@beam.apache.org。我們很樂意收到您的來信。