



部落格
2017/08/16
在 Apache Beam 中使用可分割 DoFn 的強大模組化 IO 連接器
Apache Beam 生態系統中最重要的部分之一是其快速增長的連接器集合,這些連接器允許 Beam 管道讀取和寫入各種數據存儲系統(「IO」)。目前,Beam 附帶了超過 20 個 IO 連接器,還有更多連接器正在積極開發中。隨著用戶對 IO 連接器的需求增加,我們在改進相關 Beam API(特別是 Source API)上的工作產生了一個意想不到的結果:Beam 最基本原語 DoFn 的概括。
讀者注意事項
你好,讀者!這篇部落格是 Splittable DoFn 的絕佳介紹,但撰寫時文件還在趕工中。閱讀完本文後,您可以在官方Beam 文件中繼續學習 Splittable DoFn 的內容以及如何實作。
連接器作為迷你管道
這個充滿活力的 IO 連接器生態系統的主要原因之一是開發基本的 IO 相對簡單:許多連接器實作只是由基本 Beam ParDo 和 GroupByKey 原語組成的迷你管道(複合 PTransform)。例如,ElasticsearchIO.write() 擴展成一個 ParDo,並針對效能進行批次處理;JdbcIO.read() 擴展成 Create.of(query),重新洗牌以防止融合和 ParDo(執行子查詢)。一些 IO 構建更複雜的管道。
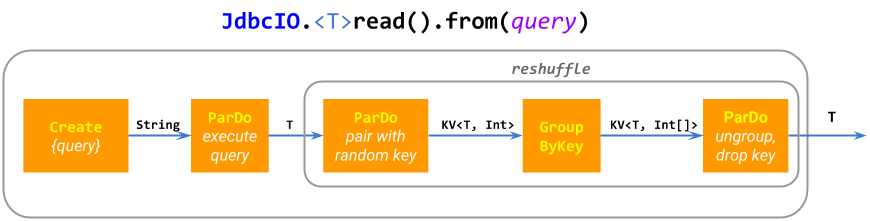
這種「迷你管道」方法很靈活、模組化,並且可以推廣到從動態計算的 PCollection 位置讀取的數據源,例如 SpannerIO.readAll(),它從 Cloud Spanner 讀取 PCollection 的查詢結果,相比之下,SpannerIO.read() 則執行單個查詢。我們認為這種動態數據源是非常有用的功能,通常被其他數據處理框架所忽略。
當 ParDo 和 GroupByKey 不夠用時
儘管 ParDo、GroupByKey 及其衍生產品具有靈活性,但在某些情況下,構建高效的 IO 連接器需要額外的功能。
例如,想像一下使用序列 ParDo(filepattern → 展開為檔案)、ParDo(filename → 讀取記錄) 讀取檔案,或者使用 ParDo(topic → 列出分割區)、ParDo(topic, partition → 讀取記錄) 讀取 Kafka 主題。這種方法有兩個大問題
在檔案範例中,某些檔案可能比其他檔案大得多,因此第二個
ParDo可能會有非常長的個別@ProcessElement呼叫。因此,管道可能會因延遲者而導致效能不佳。在 Kafka 範例中,使用常規
DoFn根本不可能實作第二個ParDo,因為它需要針對每個輸入元素topic, partition輸出無限數量的記錄 (狀態處理 接近,但它有其他限制,使其不足以完成此任務)。
Beam Source API
Apache Beam 歷史上提供了一個 Source API(BoundedSource 和 UnboundedSource),它沒有這些限制,並允許開發用於批次和串流系統的高效數據源。管道透過內建的 PTransform Read.from(Source) 使用此 API。
Source API 與大多數其他數據處理框架的 API 大致相似,並允許系統使用多個工作程序平行讀取數據,以及檢查點並從無界數據源恢復讀取。此外,Beam BoundedSource API 提供進階功能,例如進度報告和動態重新平衡(它們共同實現自動縮放)和 UnboundedSource 支援報告來源的水印和積壓 (在 SDF 之前,我們認為「批次」和「串流」數據源根本不同,因此需要根本不同的 API)。
不幸的是,這些功能是有代價的。針對 Source API 進行編碼涉及大量樣板程式碼並且容易出錯,而且它與 Beam 模型其餘部分不能很好地組合,因為 Source 只能出現在管道的根目錄。例如
使用 Source API,無法讀取 filepatterns 的
PCollection。Source無法讀取側輸入,或等待另一個管道步驟來產生資料。Source無法發出額外的輸出(例如,未能剖析的記錄)等等。
Source API 甚至無法與自身組合。例如,假設 Alice 實作一個無界 Source,它監視目錄中新的匹配檔案,而 Bob 實作一個無界 Source,它追蹤一個檔案。Source API 不允許它們簡單地將來源鏈接在一起並獲得一個 Source,該來源會傳回目錄中新日誌檔案中的新記錄(這是一個非常常見的用戶請求)。相反,這樣的來源必須主要從頭開始開發,而且我們的經驗表明,這種 Source 的功能齊全的整體式實作非常困難且容易出錯。
Source API 的另一類問題來自其嚴格的有界/無界二分法
很難或不可能在看似非常相似的有界和無界來源之間重複使用程式碼,例如,產生序列
[a, b)的BoundedSource和產生序列[a, inf)的UnboundedSource在 Beam Java SDK 中不共享任何程式碼。不清楚如何分類對非常大且不斷增長的資料集的擷取。擷取其「已可用」部分似乎需要一個
BoundedSource:執行器可以從了解其大小中受益,並且可以執行動態重新平衡。但是,擷取不斷到達的新資料似乎需要一個UnboundedSource來提供水印。從這個角度來看,SourceAPI 具有與 Lambda 架構相同的問題。
大約兩年前,我們開始思考如何解決 Source API 的限制,結果令人驚訝地解決了 DoFn 的限制。
進入可分割 DoFn
可分割 DoFn (SDF) 是 DoFn 的概括,它賦予它 Source 的核心功能,同時保留 DoFn 的語法、靈活性、模組化和易於編碼。因此,可以使用更短、更簡單、更可重複使用的程式碼來開發比以前更強大的 IO 連接器。
請注意,與 Source 不同,SDF 沒有獨立的有界/無界 API,就像常規 DoFn 沒有一樣:只有一個 API,它涵蓋了這兩種用例以及介於兩者之間的任何內容。因此,SDF 填補了 Apache Beam 統一批次/串流程式設計模型中的最後一個差距。
在閱讀以下 SDF 的解釋時,請記住將檔案名稱作為輸入並輸出該檔案中的記錄的 DoFn 的執行範例。熟悉 Source API 的人可能會發現將 SDF 視為一種讀取來源的 PCollection 的方法很有用,將來源本身視為管道中的另一段數據 (事實上,這是導致創建 SDF 的早期設計迭代之一)。
Source 比常規 DoFn 具有優勢的兩個方面是
可分割性:將
DoFn應用於單個元素是整體式的,但從Source讀取是非整體式的。不必一次讀取整個Source;相反,它是分部分讀取的,稱為捆綁包。例如,通常會在多個捆綁包中讀取一個大檔案,每個捆綁包都讀取檔案內某些子範圍的偏移量。同樣,Kafka 主題(當然,永遠無法「完全」讀取)是在無限數量的捆綁包中讀取的,每個捆綁包都讀取有限數量的元素。與執行器的互動:執行器將
DoFn應用於單個元素作為「黑盒子」,但與Source的互動非常豐富。Source為執行器提供資訊,例如其估計大小(或其概括,「積壓」)、讀取捆綁包的進度、水印等。執行器使用此資訊來調整執行並控制Source分解為捆綁包。例如,一個進度緩慢的大型檔案捆綁包可能會在變成延遲者之前被以批次為重點的執行器動態分割,而以延遲為重點的串流執行器可能會控制它在每個捆綁包中從來源讀取多少元素,以優化延遲與每個捆綁包的開銷。
具有限制的非整體式元素處理
可分割 DoFn 透過允許單個元素的處理是非整體式的來支援類似 Source 的功能。
SDF 對單一元素的處理會分解成 (可能無限多個) 限制,每個限制描述針對整個元素要完成的部分工作。SDF 的 @ProcessElement 呼叫的輸入是一對元素和限制 (相較於只接收元素的常規 DoFn)。
每個元素的處理都從建立描述整個工作的初始限制開始,然後將初始限制進一步分割成子限制,這些子限制在邏輯上必須加總回原始限制。例如,對於一個名為 ReadFn 的可分割 DoFn,它接收一個檔案名稱並輸出檔案中的記錄,限制可能是一對起始和結束位元組偏移量,而 ReadFn 可能會將其解釋為讀取起始偏移量在給定範圍內的記錄。
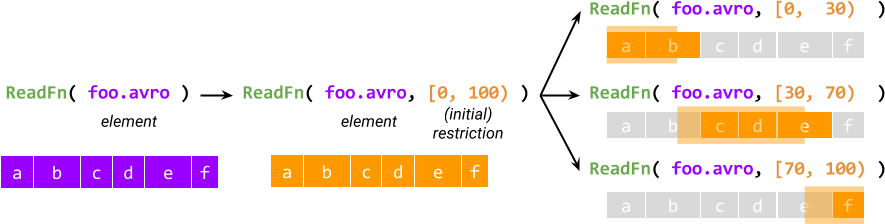
限制的概念提供了非單體式的執行方式,這是與 Source 達到對等性的第一個要素。另一個要素是與執行器的互動:執行器可以存取 SDF 每個活動 @ProcessElement 呼叫的限制,可以查詢呼叫的進度,最重要的是,可以在處理時分割限制 (因此稱為可分割 DoFn)。
分割會產生一個主要和剩餘限制,它們加總回被分割的原始限制:當前的 @ProcessElement 呼叫會繼續處理主要限制,而剩餘限制將由另一個 @ProcessElement 呼叫處理。例如,執行器可能會安排在另一個工作節點上並行處理剩餘限制。
執行中的 @ProcessElement 呼叫的分割有兩個至關重要的用途
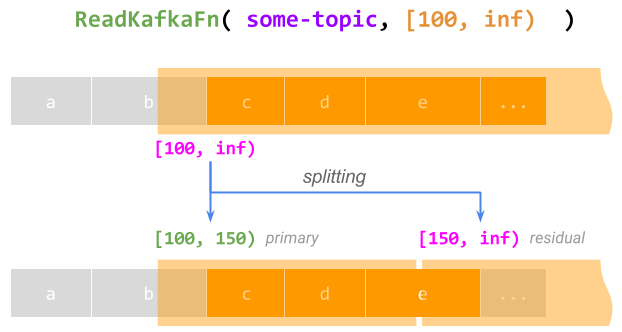
- 支援每個元素的無限工作量。 一般來說,限制不一定需要描述有限的工作量。例如,從位移量 100 開始讀取 Kafka 主題,可以用限制 [100, inf) 表示。處理整個限制的
@ProcessElement呼叫當然永遠不會完成。但是,在這樣的呼叫運行時,執行器可以將限制分割成一個有限的主要限制 [100, 150) (讓當前呼叫完成這部分),以及一個無限的剩餘限制 [150, inf) 稍後處理,有效地對呼叫進行檢查點和恢復;這可以永遠重複。
- 動態重新平衡。 當 (通常以批次為主的) 執行器偵測到
@ProcessElement呼叫將會花費太長時間並成為落後者時,它可以按比例分割限制,使主要限制足夠短而不會成為落後者,並且可以在另一個工作節點上並行安排剩餘限制。有關詳細資訊,請參閱 No Shard Left Behind。
在邏輯上,SDF 對元素的執行會按照以下圖表進行,其中「魔法」代表執行器特定的分割限制和安排剩餘限制處理的能力。
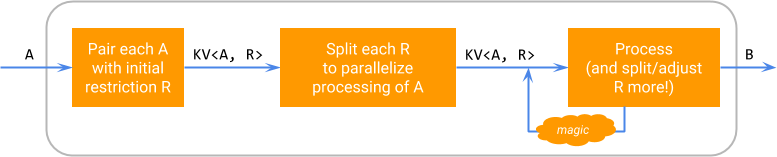
此圖表強調可分割性是特定 DoFn 的實作細節:可分割 DoFn 對其使用者而言仍然看起來像 DoFn<A, B>,並且可以透過 ParDo 應用於 PCollection<A>,產生 PCollection<B>。
哪些 DoFn 需要可分割
請注意,將元素分解為元素/限制對並非自動或「神奇」:SDF 是一個用於撰寫 DoFn 的新 API,而不是執行現有 DoFn 的新方式。在使 DoFn 可分割時,作者需要
考量其針對每個元素執行的工作結構。
提出一個使用限制描述這部分工作的方案。
撰寫程式碼以建立初始限制、分割它,並執行元素/限制對。
在使用者管線中找到的絕大多數 DoFn 並不需要設為可分割:SDF 是一個進階且功能強大的 API,主要針對新的 IO 連接器作者(儘管它也有有趣的非 IO 應用:請參閱 非 IO 範例)。
限制的執行和資料一致性
可分割 DoFn 設計中最重要的部分之一與其如何在分割時實現資料一致性有關。例如,當執行器準備分割活動 @ProcessElement 呼叫的限制時,它如何確保呼叫沒有同時進展到超出分割點?
這是透過要求限制的處理遵循特定模式來實現的。我們將限制視為一系列區塊 - 由位置識別的基本不可分割的工作單元。@ProcessElement 呼叫逐個處理這些區塊,首先聲明區塊的位置以原子地檢查它是否仍在限制範圍內,直到整個限制處理完成。
下圖說明了針對處理元素 foo.avro 且限制為 [30, 70) 的 ReadFn (讀取 Avro 檔案的可分割 DoFn) 的情況。此 @ProcessElement 呼叫掃描 Avro 檔案中從位移量 30 開始的 資料區塊,並聲明此範圍內每個區塊的位置。如果成功聲明區塊,則呼叫會輸出此資料區塊中的所有記錄,否則會終止。
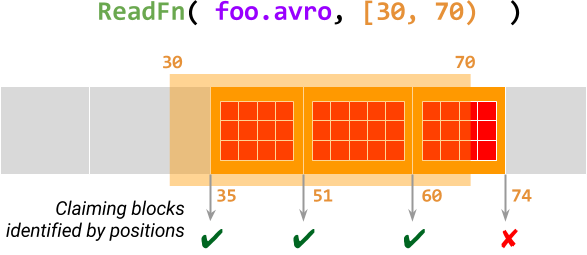
有關詳細資訊,請參閱設計提案文件中的 限制、區塊和位置。
程式碼範例
讓我們來看一些 SDF 程式碼範例。這些範例使用 Beam Java SDK,它 將可分割 DoFns 表示 為彈性的 基於註釋的 DoFn 機制的一部分,以及 針對 Python 提出的 SDF 語法。
可分割
DoFn是一個DoFn- 不需要新的基礎類別。任何 SDF 都衍生自DoFn類別並具有@ProcessElement方法。除了當前元素之外,
@ProcessElement方法還採用一個額外的RestrictionTracker參數,該參數提供對當前限制的存取權。SDF 需要定義一個
@GetInitialRestriction方法,該方法可以建立描述給定元素完整工作的限制。還有一些不太重要的可選方法,例如用於將初始限制預先分割成幾個較小限制的
@SplitRestriction,以及其他一些方法。
SDF 的「Hello World」是一個計數器,它接收成對的 (x, N) 作為輸入,並產生成對的 (x, 0), (x, 1), …, (x, N-1) 作為輸出。
class CountFn<T> extends DoFn<KV<T, Long>, KV<T, Long>> {
@ProcessElement
public void process(ProcessContext c, OffsetRangeTracker tracker) {
for (long i = tracker.currentRestriction().getFrom(); tracker.tryClaim(i); ++i) {
c.output(KV.of(c.element().getKey(), i));
}
}
@GetInitialRestriction
public OffsetRange getInitialRange(KV<T, Long> element) {
return new OffsetRange(0L, element.getValue());
}
}
PCollection<KV<String, Long>> input = …;
PCollection<KV<String, Long>> output = input.apply(
ParDo.of(new CountFn<String>());class CountFn(DoFn):
def process(element, tracker=DoFn.RestrictionTrackerParam)
for i in xrange(*tracker.current_restriction()):
if not tracker.try_claim(i):
return
yield element[0], i
def get_initial_restriction(element):
return (0, element[1])這個簡短的 DoFn 包含 CountingSource 的功能,但更具彈性:CountingSource 僅在管線建構時產生一個指定的序列,而此 DoFn 可以產生動態的序列族,每個輸入集合中的元素一個序列 (輸入集合是有界還是無界並不重要)。
但是,CountingSource 的 Source 特定功能在 CountFn 中仍然可用。例如,如果一個序列有很多元素,則以批次為主的執行器仍然可以對其應用動態重新平衡,並透過分割 OffsetRange 並行產生序列的不同子範圍。同樣地,以串流為主的執行器可以使用相同的分割邏輯來檢查點和恢復序列的產生,即使在實際應用中它是無限的 (例如,當應用於 KV(..., Long.MAX_VALUE) 時)。
一個稍微複雜的範例是上面考慮的 ReadFn,它從 Avro 檔案中讀取資料並說明區塊的概念:我們提供虛擬程式碼來說明該方法。
class ReadFn extends DoFn<String, AvroRecord> {
@ProcessElement
void process(ProcessContext c, OffsetRangeTracker tracker) {
try (AvroReader reader = Avro.open(filename)) {
// Seek to the first block starting at or after the start offset.
reader.seek(tracker.currentRestriction().getFrom());
while (reader.readNextBlock()) {
// Claim the position of the current Avro block
if (!tracker.tryClaim(reader.currentBlockOffset())) {
// Out of range of the current restriction - we're done.
return;
}
// Emit all records in this block
for (AvroRecord record : reader.currentBlock()) {
c.output(record);
}
}
}
}
@GetInitialRestriction
OffsetRange getInitialRestriction(String filename) {
return new OffsetRange(0, new File(filename).getSize());
}
}class AvroReader(DoFn):
def process(filename, tracker=DoFn.RestrictionTrackerParam)
with fileio.ChannelFactory.open(filename) as file:
start, stop = tracker.current_restriction()
# Seek to the first block starting at or after the start offset.
file.seek(start)
block = AvroUtils.get_next_block(file)
while block:
# Claim the position of the current Avro block
if not tracker.try_claim(block.start()):
# Out of range of the current restriction - we're done.
return
# Emit all records in this block
for record in block.records():
yield record
block = AvroUtils.get_next_block(file)
def get_initial_restriction(self, filename):
return (0, fileio.ChannelFactory.size_in_bytes(filename))這個假設的 DoFn 從單個 Avro 檔案讀取記錄。特別缺少擴展檔案模式的程式碼:它不再需要成為此 DoFn 的一部分!相反地,SDK 包括一個 FileIO.matchAll() 轉換,用於將檔案模式擴展到檔案名稱的 PCollection,而不同的檔案格式 IO 可以重複使用相同的轉換,使用不同的 DoFn 讀取檔案。
此範例展示了 SDF 所允許的模組化增強的優勢:FileIO.matchAll() 支援使用 .continuously() 在串流管線中持續擷取新檔案,並且此功能會自動提供給各種檔案格式 IO。例如,TextIO.read().watchForNewFiles() 在幕後使用 FileIO.matchAll())。
目前狀態
可分割 DoFn 是一個重要的全新 API,其交付和廣泛採用涉及 Apache Beam 生態系統中不同部分的許多工作。其中一些工作已經完成,並透過新的 IO 連接器為使用者提供了直接的好處。但是,大量工作正在進行或計畫中。
截至 2017 年 8 月,SDF 可用於 Beam Java Direct 執行器和 Dataflow 串流執行器,並且正在 Flink 和 Apex 執行器中實作;請參閱 功能矩陣 以了解目前狀態。Python SDK 中對 SDF 的支援正在 積極開發中。
多個基於 SDF 的轉換和 IO 連接器可供 Beam 使用者在 HEAD 上使用,並將包含在 Beam 2.2.0 中。TextIO 和 AvroIO 最終透過 .watchForNewFiles() 提供檔案的持續擷取 (最常要求的功能之一),該功能由實用工具轉換 FileIO.matchAll().continuously() 和更通用的 Watch.growthOf() 提供支援。這些實用工具轉換對於「高階使用者」的用例也具有獨立的實用性。
為了為目前基於 Source API 的 IO 啟用更彈性的用例,我們將變更它們以使用 SDF。此轉換由 TextIO 開創,並且暫時 透過 Source API 執行 SDF,以支援缺乏直接執行 SDF 能力的執行器。
除了啟用新的 IO 之外,SDF 的工作還影響了我們對 Beam 程式設計模型其他部分的思考
SDF 統一了 Beam 程式設計模型中最後一個非批次/串流不可知的部分 (
SourceAPI)。這促使我們考慮無法描述為純粹批次或串流的用例 (例如,擷取大量的歷史資料並繼續處理即時到達的更多資料),並開發 「進度」和「待辦事項」的統一概念。Fn API - Beam 未來支援跨語言管線的基礎 - 使用 SDF 作為表示資料擷取的唯一概念。
SDF 的實施已促成正式化 pipeline 終止語義,並使其在不同的執行器之間保持一致。
SDF 為模組化 IO 連接器樹立了新標準,啟發了為某些非基於 SDF 的連接器創建類似的 API(例如,
SpannerIO.readAll()和計劃中的JdbcIO.readAll())。
行動呼籲
Apache Beam 的蓬勃發展歸功於龐大的貢獻者社群。以下是一些您可以參與 SDF 工作並幫助 Beam IO 連接器生態系統更加模組化的方式
使用目前可用的基於 SDF 的 IO 連接器,提供回饋、提交錯誤、並建議或實施改進。
提出或開發一個基於 SDF 的新 IO 連接器。
在您最喜歡的執行器中實施或改進對 SDF 的支援。
訂閱並參與在 user@beam.apache.org(Beam 使用者郵件列表)和 dev@beam.apache.org(Beam 開發者郵件列表)上偶爾出現的與 SDF 相關的討論!