



部落格
2024/01/03
在 Apache Beam 上擴展串流工作負載,每秒 100 萬個事件以上

擴展串流工作負載對於確保管線能夠處理大量數據,同時將延遲降至最低並高效執行至關重要。如果沒有適當的擴展,管線可能會遇到效能問題,甚至完全失敗,延誤業務洞察的時間。
鑑於 Apache Beam 對工作負載所需來源和接收器的支援,開發串流管線可能會很簡單。您可以專注於處理(轉換、擴充或彙總)以及設定每個案例的正確組態。
但是,您需要找出關鍵的效能瓶頸,並確保管線擁有有效處理負載所需的資源。這可能涉及調整工作人員數量、了解管線來源和接收器所需的設定、最佳化處理邏輯,甚至決定傳輸格式。
本文說明如何管理在 Apache Beam 中開發並使用 Dataflow 在 Google Cloud 上執行的串流工作負載的擴展和最佳化問題。目標是達到每秒 100 萬個事件,同時將執行期間的延遲和資源使用降至最低。該工作負載使用 Pub/Sub 作為串流來源,並使用 BigQuery 作為接收器。我們描述了我們用來幫助工作負載達到所需規模及以上的組態設定和程式碼變更背後的邏輯。
本文中描述的進展對應於實際工作負載的演變,並進行了簡化。在達到管線的初始業務需求後,重點轉向最佳化效能並減少管線執行所需的資源。
執行設定
在本文中,我們建立了一個測試套件,用於建立管線執行所需的元件。您可以在這個 Github 儲存庫中找到程式碼。您可以在這個資料夾中找到每次執行時引入的後續組態變更,這些變更可作為您可以執行以達到類似結果的腳本。
所有執行腳本也可以執行基於 Terraform 的自動化,以建立 Pub/Sub 主題和訂閱,以及 BigQuery 資料集和資料表來執行工作負載。此外,它還會啟動兩個管線:一個資料產生管線,將事件推送到 Pub/Sub 主題,以及一個擷取管線,示範潛在的改進點。
在所有情況下,管線都從空的 Pub/Sub 主題和訂閱以及空的 BigQuery 資料表開始。計畫是每秒產生 100 萬個事件,並在幾分鐘後檢閱擷取管線如何隨時間擴展。自動產生的資料基於組態提供的結構描述或 IDL(或介面描述語言),目標是讓訊息的大小介於 800 位元組到 2 KB 之間,總計約 1 GB/秒的吞吐量。此外,擷取管線在所有執行中都使用相同的工作人員類型組態 (n2d-standard-4 GCE 機器),並且限制了最大工作人員數量,以避免非常大的機群。
所有執行都在使用 Dataflow 的 Google Cloud 上執行,但是您可以在其他支援的 Apache Beam 執行器上執行時,將所有組態和格式變更套用至套件。變更和建議並非特定於執行器。
本機環境需求
在啟動啟動腳本之前,請在本機環境中安裝以下項目
gcloud,以及正確的權限- Terraform
- JDK 17 或更高版本
- Maven 3.6 或更高版本
如需更多資訊,請參閱 GitHub 儲存庫中的需求章節。
此外,請檢閱您的 Google Cloud 專案中可用的服務配額和資源。特別是:Pub/Sub 區域容量、BigQuery 擷取配額,以及測試所選區域中可用的 Compute Engine 執行個體。
工作負載描述
專注於擷取管線,我們的工作負載很簡單。它會完成以下步驟
- 從 Pub/Sub 讀取特定格式的資料 (在本例中為 Apache Thrift)
- 處理潛在的壓縮和批次處理設定 (預設未啟用)
- 執行 UDF (預設為身分函式)
- 將輸入格式轉換為
BigQueryIO轉換支援的格式之一 - 將資料寫入設定的資料表

我們用於測試的管線具有高度可組態性。如需有關如何調整擷取的更多詳細資訊,請參閱檔案中的選項。我們的任何步驟都不需要程式碼變更。執行腳本會處理所需的組態。
雖然這些測試的重點是從 Pub/Sub 讀取資料,但擷取管線能夠從一般串流來源讀取資料。儲存庫包含其他範例,示範如何啟動從 Pub/Sub Lite 和 Kafka 讀取資料的相同測試套件。在所有情況下,管線自動化都會設定串流基礎架構。
最後,您可以在組態選項中看到,管線支援輸入的許多傳輸格式選項,例如 Thrift、Avro 和 JSON。此套件的重點是 Thrift,因為它是一種常見的開放原始碼格式,而且因為它會產生格式轉換需求。目的是要讓工作負載處理承受一些壓力。您可以針對 Avro 和 JSON 輸入資料執行類似的測試。串流資料產生器管線可以透過直接在結構描述 (Avro 和 JSON) 或針對執行提供的 IDL (Thrift) 上執行來為三種支援的格式產生隨機資料。
第一次執行:預設設定
執行的預設值會使用 BigQueryIO 的 STREAMING_INSERTS 模式將資料寫入 BigQuery。此模式與 BigQuery 的 tableData insertAll API 相關。此 API 支援 JSON 格式的資料。從 Apache Beam 的角度來看,使用 BigQueryIO.writeTableRows 方法可讓我們將寫入解析為 BigQuery。
對於我們的擷取管線,Thrift 格式需要轉換為 TableRow。為此,我們需要將 Thrift IDL 轉換為 BigQuery 資料表結構描述。這可以透過將 Thrift IDL 轉換為 Avro 結構描述,然後使用 Beam 公用程式來轉換 BigQuery 的資料表結構描述來達成。我們可以在啟動時執行此動作。結構描述轉換會快取在 DoFn 層級。
設定資料產生和擷取管線,並讓管線執行幾分鐘後,我們看到管線無法維持所需的吞吐量。
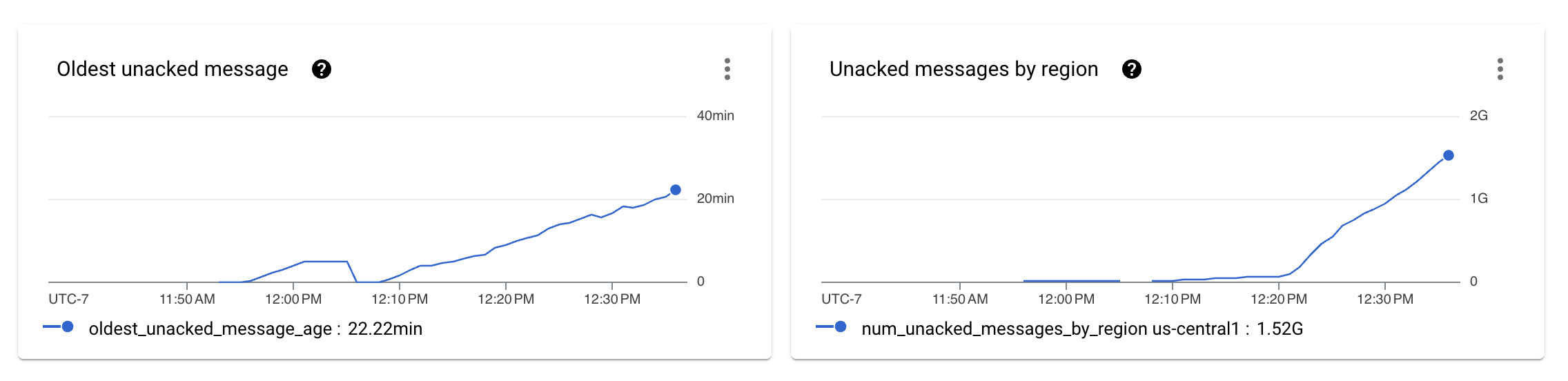
先前的影像顯示,擷取管線未處理的訊息數量開始在 Pub/Sub 指標中顯示為未確認的訊息。
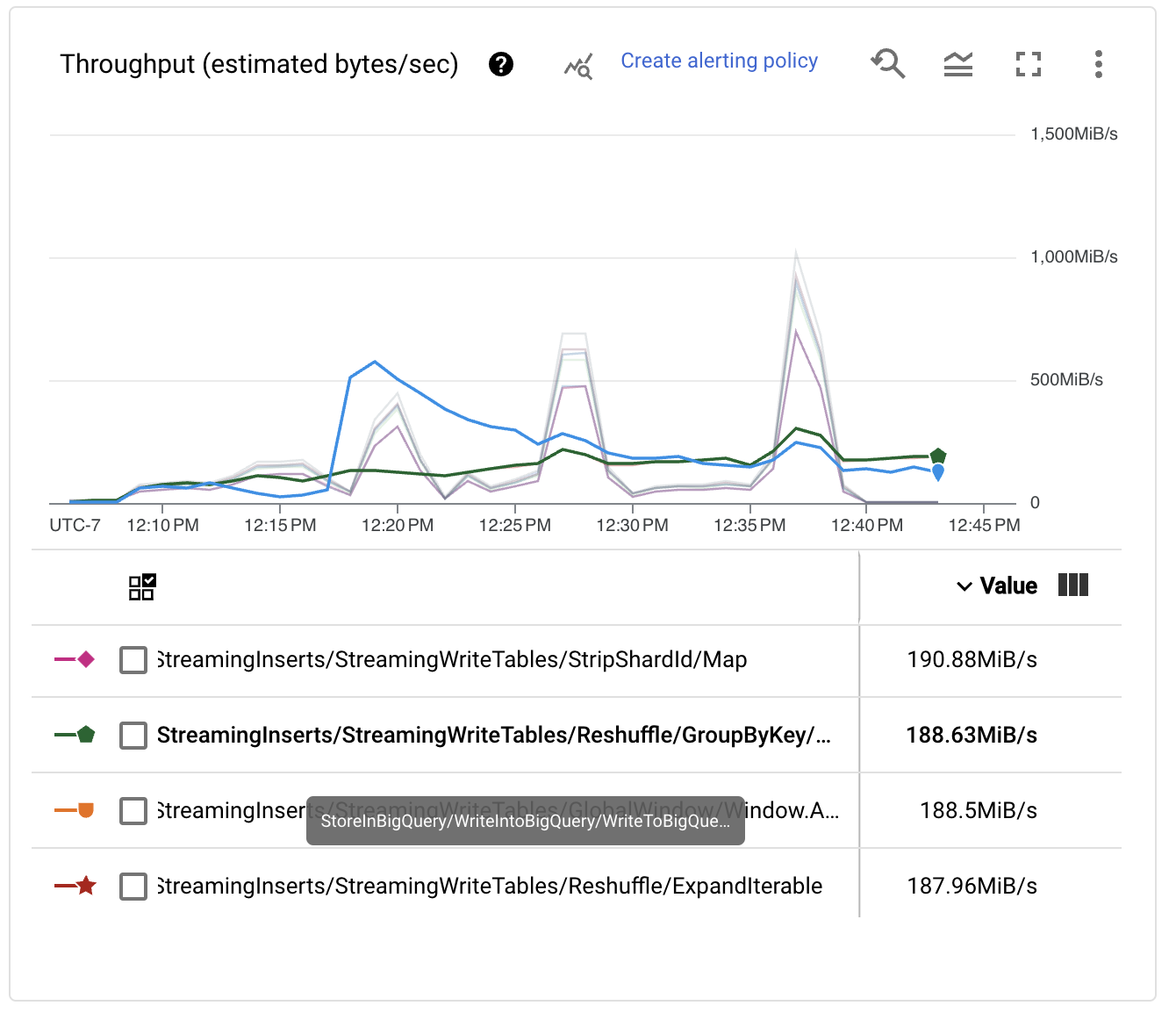
檢閱每個階段的效能指標,我們看到管線顯示鋸齒狀,這通常與 Dataflow 執行器在某些階段充當吞吐量瓶頸時使用的節流機制相關。此外,我們看到 BigQueryIO 寫入轉換上的 Reshuffle 步驟並未如預期般擴展。
之所以發生此行為,是因為預設情況下,BigQueryOptions 使用 50 個不同的索引鍵將資料改組到工作人員,然後再在 BigQuery 上發生寫入。為了解決這個問題,我們可以將組態新增至我們的啟動腳本,以啟用寫入操作來擴展到更多的工作人員,進而提高效能。
第二次執行:改善寫入瓶頸
將串流索引鍵的數量增加到更高的數量 (在我們的案例中為 512 個索引鍵) 後,我們重新啟動了測試套件。Pub/Sub 指標開始改善。在初始的待辦事項大小增加後,曲線開始趨於平緩。
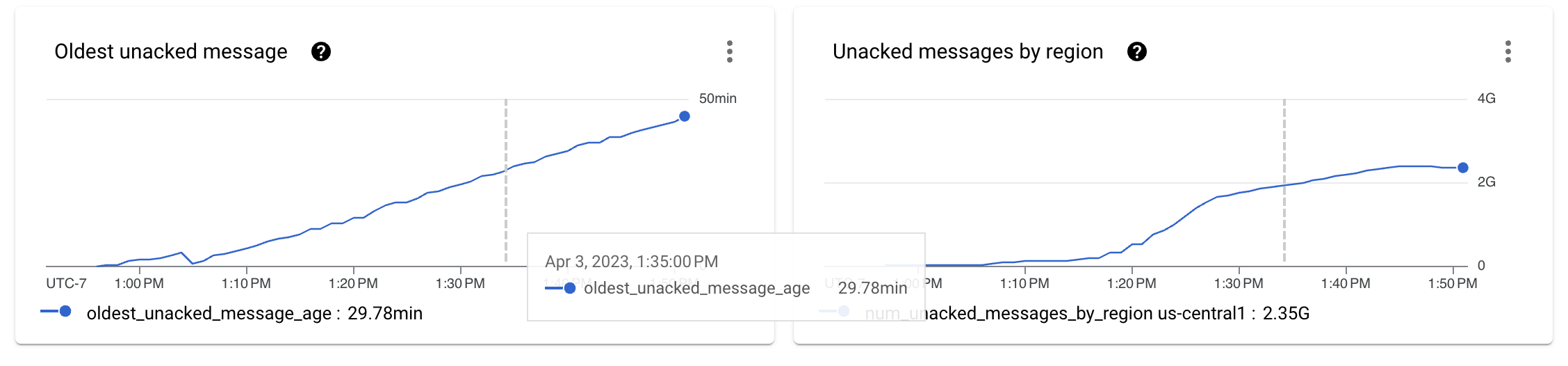
這很好,但我們應該查看每個階段的吞吐量數字,以了解我們是否已達成我們為此練習設定的目標。
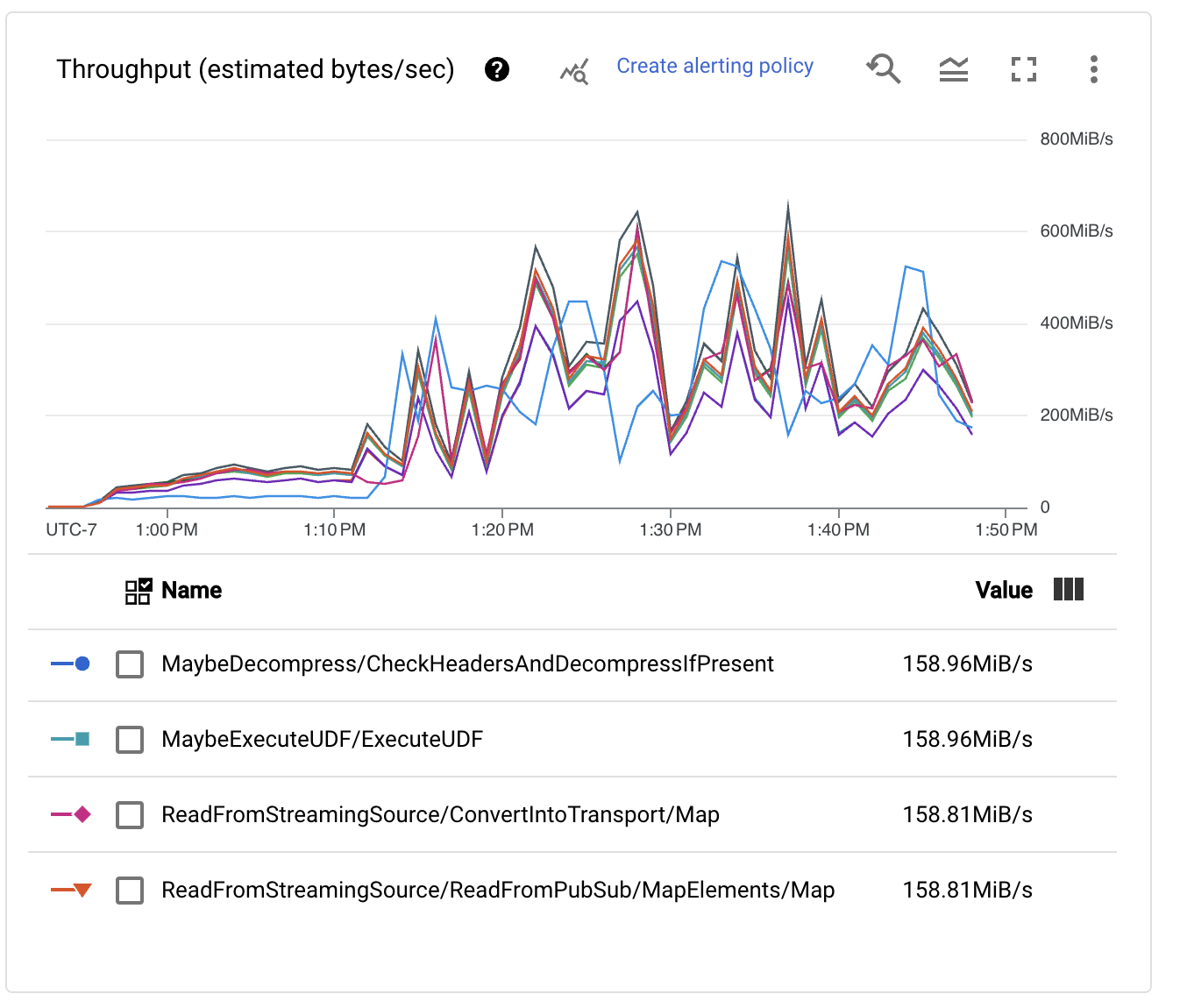
雖然效能顯然已提高,而且 Pub/Sub 待辦事項不再單調增加,但我們仍然遠離擷取管線每秒處理 100 萬個事件 (1 GB/秒) 的目標。事實上,吞吐量指標到處跳動,表示瓶頸正在阻止處理進一步擴展。
第三次執行:釋放自動擴展
幸運的是,在寫入 BigQuery 時,我們可以自動調整寫入的規模。此步驟簡化了組態,因此我們不必猜測正確的分片數。我們切換了管線的組態,並為下一個啟動腳本啟用此設定。
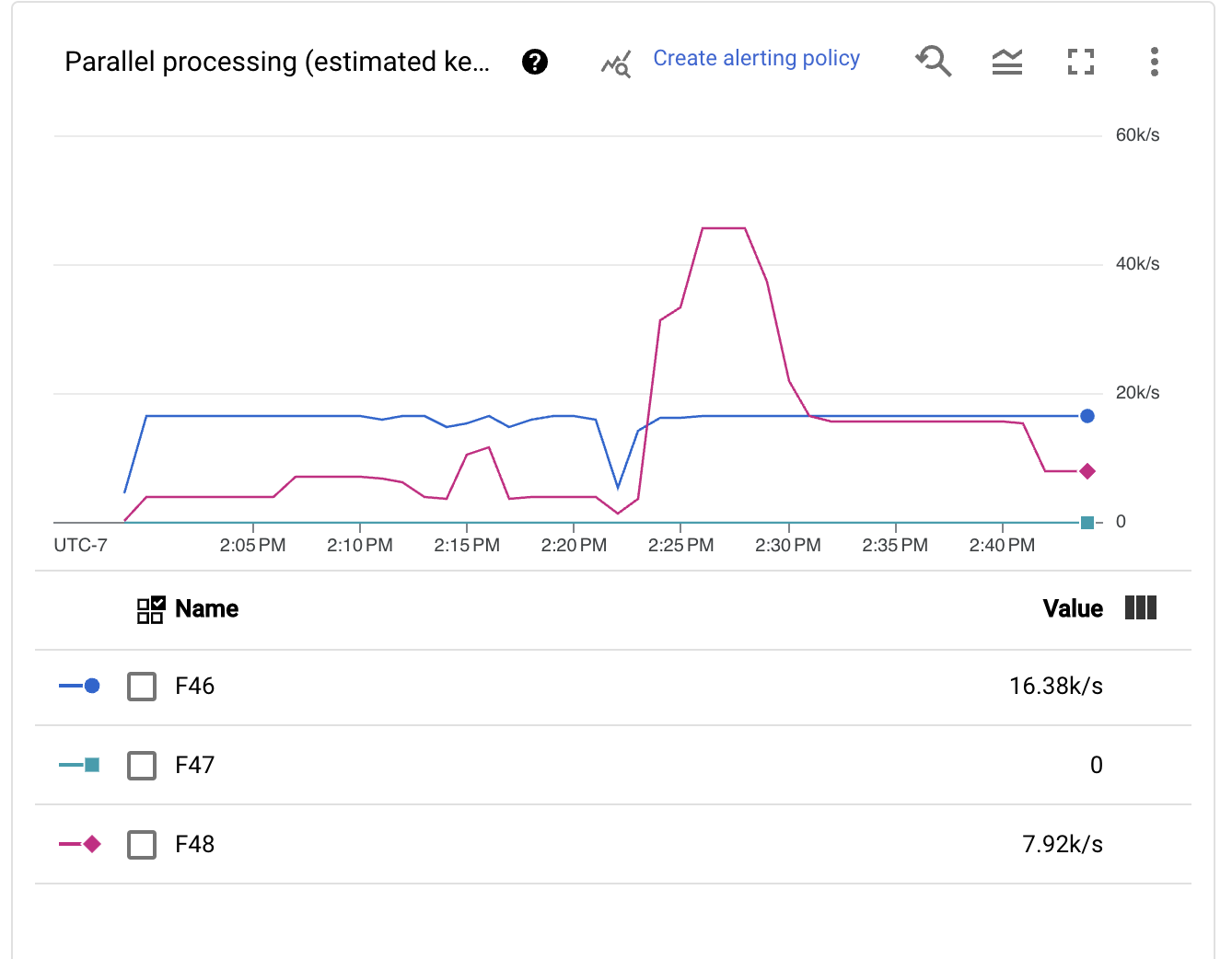
我們立即看到,自動分片機制會以動態方式非常積極地調整索引鍵數量。此變更很好,因為時間上的不同時刻可能會有不同的規模需求,例如早期的待辦事項復原和執行中的高峰。
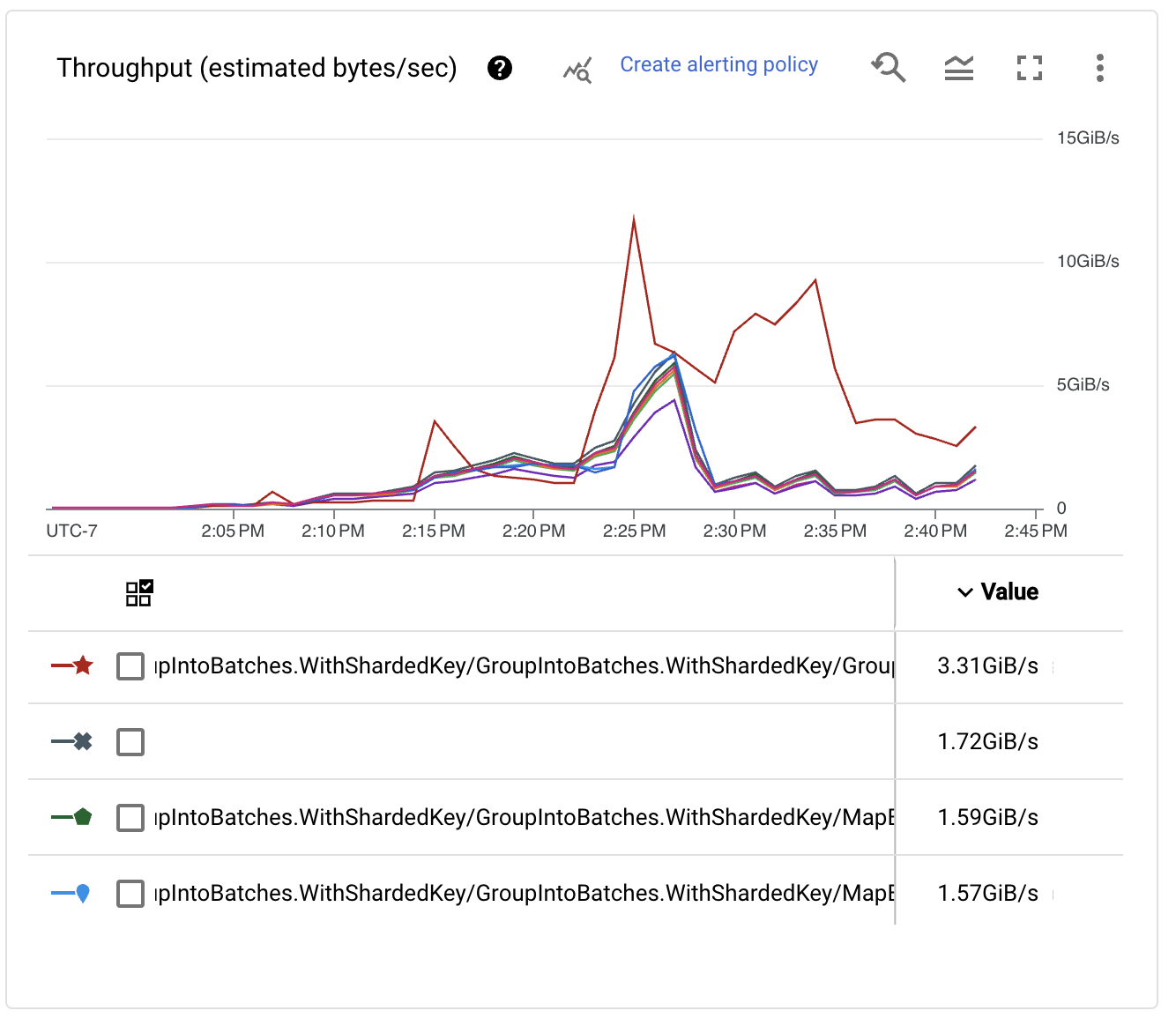
檢查每個階段的吞吐量效能,我們看到隨著索引鍵數量的增加,寫入的效能也隨之增加。事實上,它達到了非常大的數字!
在耗盡初始待辦事項且管線穩定後,我們看到已達到所需的效能數字。管線可以持續處理來自 Pub/Sub 的每秒超過 100 萬個事件,以及每秒數 GB 的 BigQuery 擷取。耶!
不過,我們想看看是否可以做得更好。我們可以對管線進行多項改進,以使執行更有效率。在大多數情況下,改進是組態變更。我們只需要知道接下來的重點在哪裡。
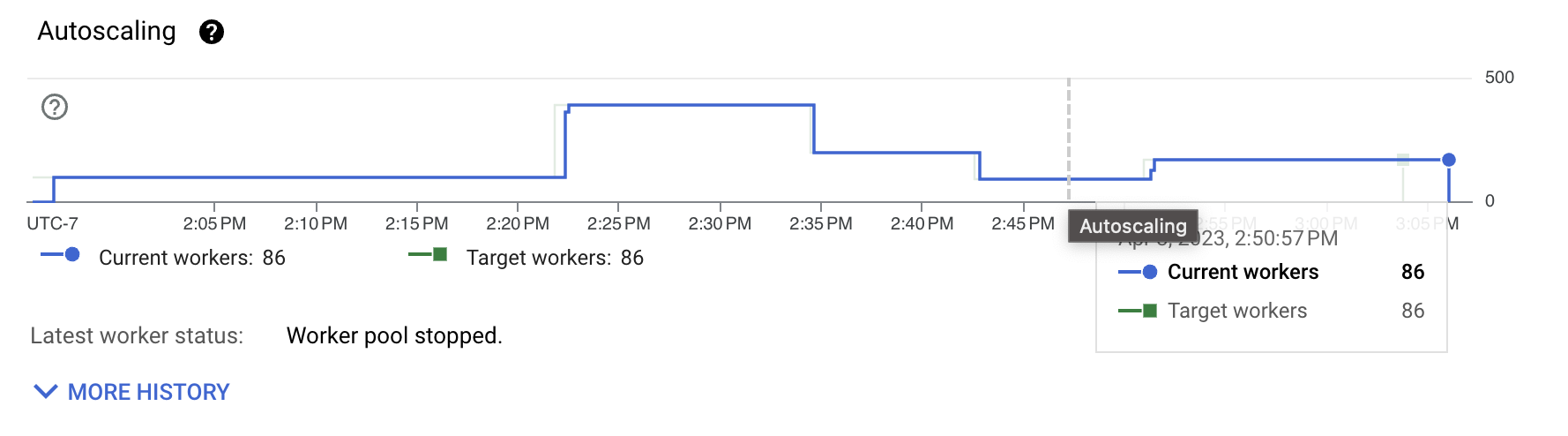
先前的影像顯示,維持此吞吐量所需的工作人員數量仍然相當高。工作負載本身並非 CPU 密集型。大部分成本都花在轉換格式和 I/O 互動上,例如改組和實際寫入。為了了解要改進的地方,我們首先研究傳輸格式。
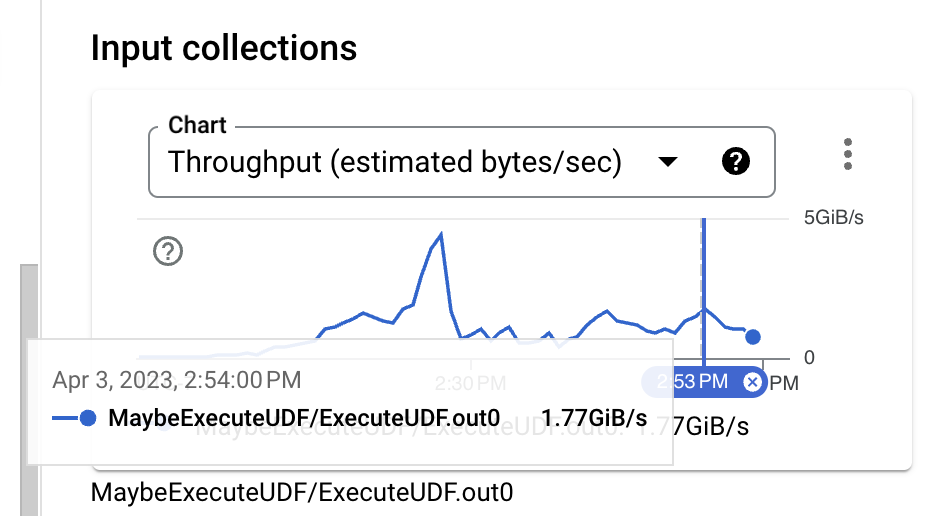
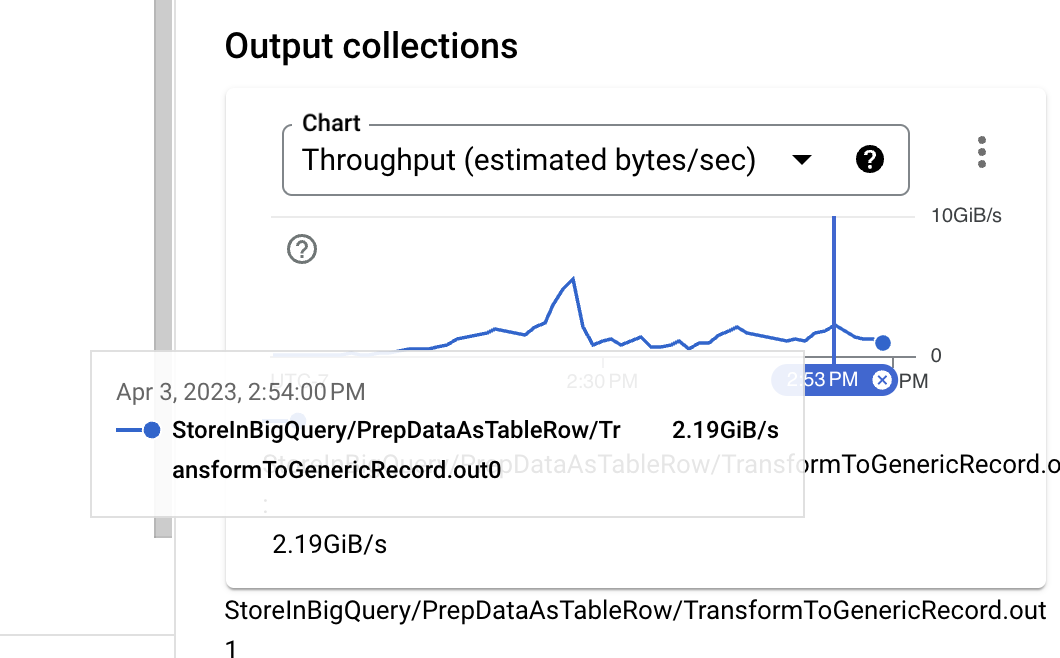
觀察輸入大小,在身分 UDF 執行之前,資料格式為二進位的 Thrift,即使不使用壓縮,也是一種相當緊湊的格式。然而,當將 PCollection 的近似大小與 BigQuery 擷取所需的 TableRow 格式進行比較時,可以明顯看到大小增加。我們可以透過變更所使用的 BigQuery 寫入 API 來改善這一點。
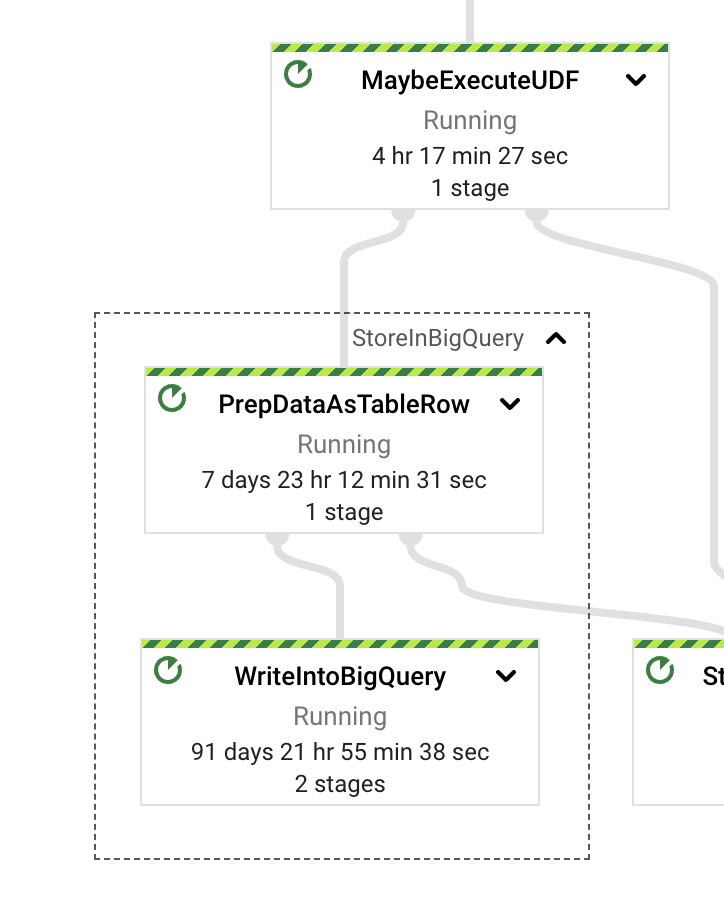
當我們檢查 StoreInBigQuery 轉換時,我們發現大部分的實際執行時間都花在實際寫入上。此外,將資料轉換為目標格式 (TableRows) 所花費的執行時間,相較於實際寫入所花費的時間來說非常長:寫入的時間大了 13 倍。為了改善這種情況,我們可以切換管線寫入模式。
第四次執行:導入新功能
在這次執行中,我們使用 StorageWrite API。為此管線啟用 StorageWrite API 很簡單。我們將寫入模式設定為 STORAGE_WRITE_API,並定義寫入觸發頻率。在此測試中,我們最多每十秒寫入一次資料。寫入觸發頻率會控制每個資料流的資料累積時間。數值越高,表示在資料流指派後要寫入的輸出越大,但也代表從 Pub/Sub 讀取的每個元素的端對端延遲時間越長。與 STREAMING_WRITES 設定類似,BigQueryIO 可以處理寫入的自動分片,我們已經證明這是效能最佳的設定。
在兩個管線都穩定下來之後,使用 BigQueryIO 中的 StorageWrite API 所看到的效能優勢就很明顯了。啟用新實作後,格式轉換與寫入操作之間的執行時間比率會降低。寫入所花費的執行時間只比格式轉換的時間多出約 34%。
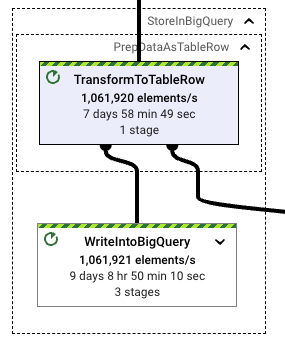
穩定後,管線輸送量也相當平穩。執行器可以快速且穩定地縮減維持所需輸送量所需的管線資源。
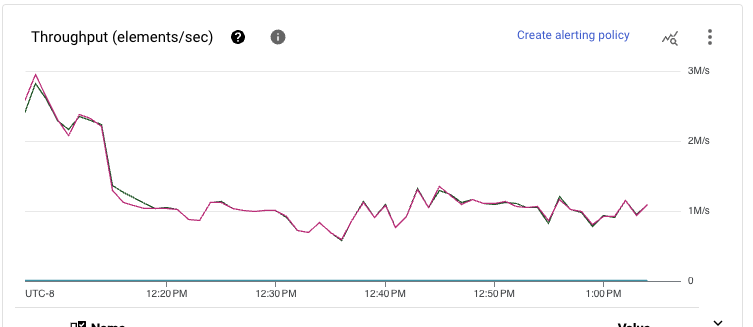
觀察處理資料所需的資源規模,可以看到另一個顯著的改進。基於串流插入的管線需要 80 多個工作站才能維持輸送量,而儲存寫入管線只需要 49 個,改善了 40%。
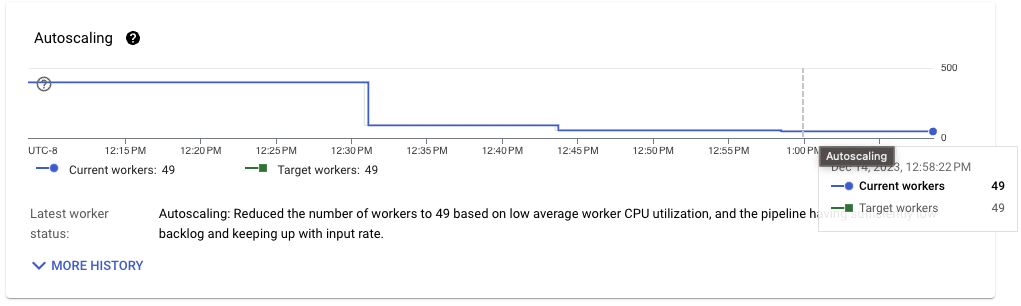
我們可以將資料產生管線作為參考。此管線只需要隨機產生資料,並將事件寫入 Pub/Sub。它穩定的運行,平均需要 40 個工作站。使用適合工作負載的正確設定,可改善擷取管線的效能,使其更接近產生所需的資源。
與基於串流插入的管線類似,將資料寫入 BigQuery 需要執行格式轉換,前者是從 Thrift 到 TableRow,後者是從 Thrift 到 Protocol Buffers (protobuf)。因為我們使用的是 BigQueryIO.writeTableRows 方法,所以我們在格式轉換中增加了另一個步驟。由於 TableRow 格式也會增加正在處理的 PCollection 大小,因此我們希望看看是否可以改善此步驟。
第五次執行:更好的寫入格式
當使用 STORAGE_WRITE_API 時,BigQueryIO 轉換會公開一個方法,我們可以用它將 Beam 列類型直接寫入 BigQuery。這個步驟很有用,因為列類型為互通性和結構描述管理提供了彈性。此外,它對於重新洗牌和密集程度也比 TableRow 更有效率,因此我們的管線會有較小的 PCollection 大小。
對於下一次執行,由於我們的資料量不小,因此我們在寫入 BigQuery 時會降低觸發頻率。因為我們使用不同的格式,所以會執行稍微不同的程式碼。對於此變更,測試管線腳本會使用標記 --formatToStore=BEAM_ROW 進行設定。
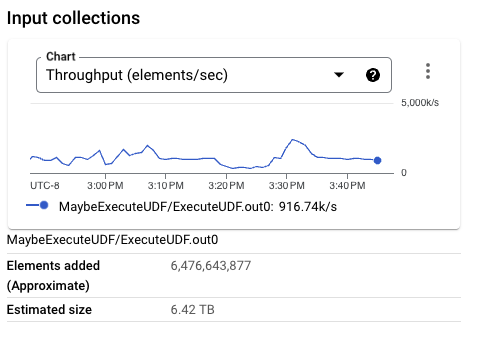
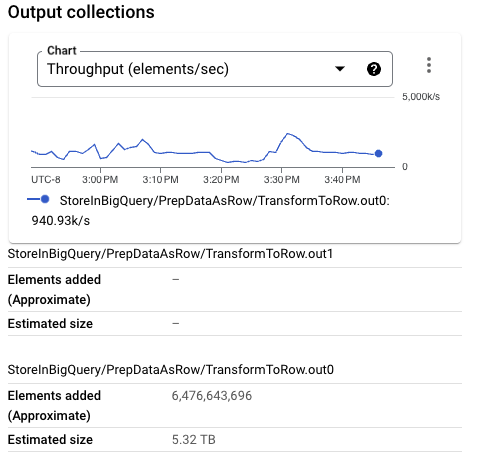
寫入 BigQuery 的 PCollection 大小明顯小於先前的執行。事實上,對於這次特定的執行,Beam 列格式的大小小於 Thrift 格式。由較大的每個元素大小組成的較大 PCollection,可能會對較小的工作站設定造成相當大的記憶體壓力,進而降低整體輸送量。
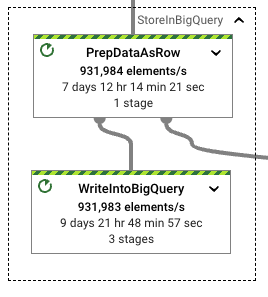
格式轉換和實際 BigQuery 寫入的實際執行時間比率也保持非常相似的比率。處理 Beam 列格式並不會在格式轉換和後續寫入中造成效能損失。當輸送量變得穩定時,管線使用的工作站數量也證實了這一點,雖然略小於上次執行,但明顯在相同的範圍內。
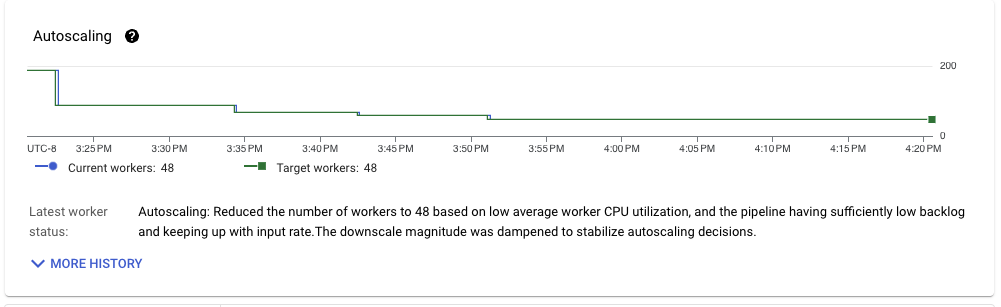
雖然我們的情況比剛開始時好得多,但考慮到我們的測試管線輸入格式,仍有改進的空間。
第六次執行:進一步減少格式轉換的工作
對於 BigQueryIO 轉換中的輸入 PCollection,另一個支援的格式可能對我們的輸入格式有利。writeGenericRecords 方法可讓轉換在寫入操作之前直接將 Avro GenericRecords 轉換為 protobuf。Apache Thrift 可以非常有效地轉換為 Avro GenericRecords。我們可以執行另一個測試執行,透過在執行腳本上設定選項 --formatToStore=AVRO_GENERIC_RECORD 來設定測試擷取管線。
這次,格式轉換和寫入之間的差異顯著增加,進而改善了效能。轉換為 Avro GenericRecords 只佔將這些記錄寫入 BigQuery 所花費寫入工作的 20%。考慮到測試管線具有相似的執行時間,而且在 WriteIntoBigQuery 階段看到的實際執行時間也與其他 StorageWrite 相關的執行一致,因此使用這種格式適合此工作負載。
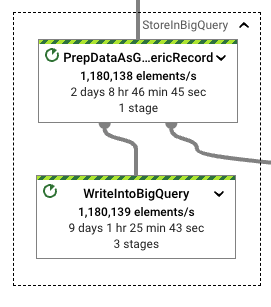
當我們觀察資源利用率時,會看到更多增益。我們需要較少的 CPU 時間來執行工作負載的格式轉換,同時達到所需的輸送量。
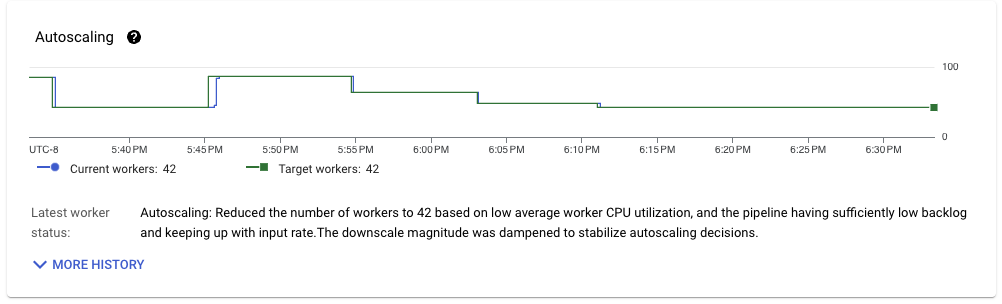
此管線在上次執行的基礎上進行了改進,當輸送量穩定時,可以穩定地在 42 個工作站上執行。考慮到所使用的工作站設定 (nd2-standard-4) 以及工作負載處理的輸送量 (約 1 GB/s),我們每個 CPU 核心的輸送量約為 6 MB/s,對於具有完全一次語意的串流管線來說,這非常令人印象深刻。
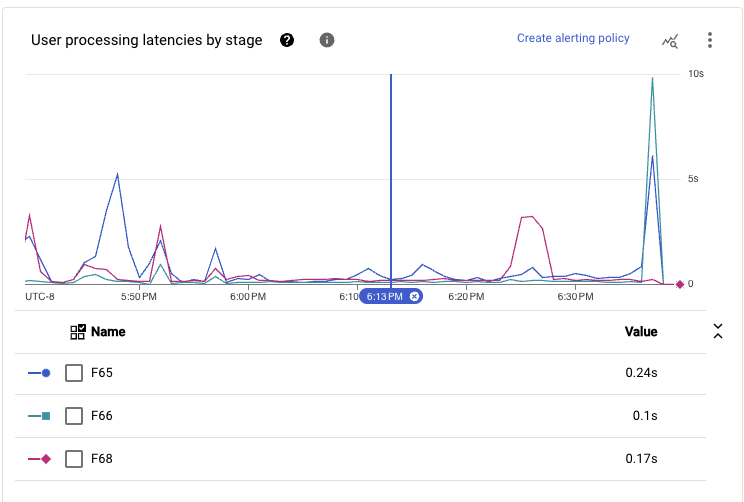
當我們將管線主要路徑中執行的所有階段加總時,在這個規模下看到的延遲時間在持續的一段時間內,可以達到次秒級的端對端延遲時間。
考慮到工作負載需求和實作的管線程式碼,在不進一步調整執行器的特定設定下,這種效能是我們可以取得的最佳效能。
第七次執行:讓我們放鬆一下(至少一些限制)
當為 BigQueryIO 使用 STORAGE\_WRITE\_API 設定時,我們會強制寫入執行完全一次語意。此設定非常適合需要對處理的資料具有強一致性的使用案例,但會造成效能和成本的損失。
從高階角度來看,寫入 BigQuery 是以批次方式進行,這些批次會根據目前的分片和觸發頻率釋放。如果寫入在特定套件的執行期間失敗,則會重試。只有在該特定套件中的所有資料都正確附加到資料流時,才會將資料套件提交到 BigQuery。這種實作需要重新洗牌完整的資料量來建立要寫入的批次,以及完成批次的資訊以供稍後提交 (雖然最後一部分與第一部分相比非常小)。
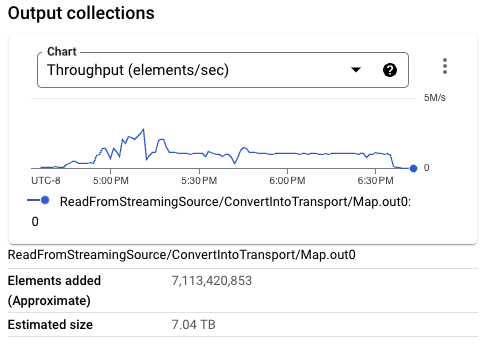
觀察先前的管線執行,Streaming Engine 處理的管線總資料量大於從 Pub/Sub 讀取的資料量。例如,從 Pub/Sub 讀取了 7 TB 的資料,而管線整個執行的資料處理會將 25 TB 的資料移入和移出 Streaming Engine。

如果資料一致性不是擷取的硬性要求,您可以對 BigQueryIO 寫入模式使用至少一次語意。此實作避免了重新洗牌和分組資料以進行寫入。然而,此變更可能會導致少量重複的列寫入目標表格。這可能會因附加錯誤、不頻繁的工作站重新啟動,和其他更不頻繁的錯誤而發生。
因此,我們新增設定以使用 STORAGE_API_AT_LEAST_ONCE 寫入模式。為了指示 StorageWrite 用戶端在寫入資料時重複使用連線,我們還新增了設定標記 –useStorageApiConnectionPool。此設定選項僅適用於 STORAGE_API_AT_LEAST_ONCE 模式,它可以減少類似於 Storage Api write delay more than 8 seconds 的警告發生次數。
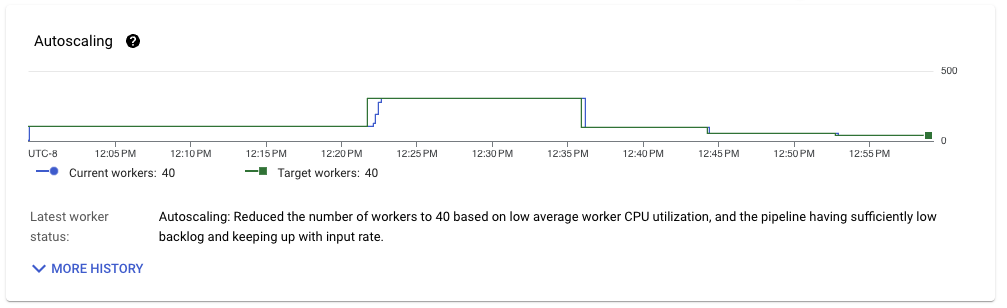
當管線輸送量穩定時,我們看到工作負載的資源利用率出現類似的模式。使用中的工作站數量達到 40 個,與上次執行相比略有改善。然而,從 Streaming Engine 移出的資料量與從 Pub/Sub 讀取的資料量更為接近。
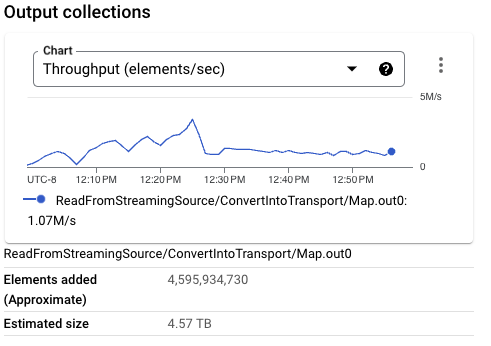

考慮到所有這些因素,此變更進一步最佳化了工作負載,每個 CPU 核心可實現 6.4 MB/s 的輸送量。與使用一致寫入到 BigQuery 時的相同工作負載相比,此改進幅度較小,但使用的串流資料資源較少。此設定代表我們工作負載的最佳設定,每個資源的輸送量最高,且跨工作站的串流資料量最低。
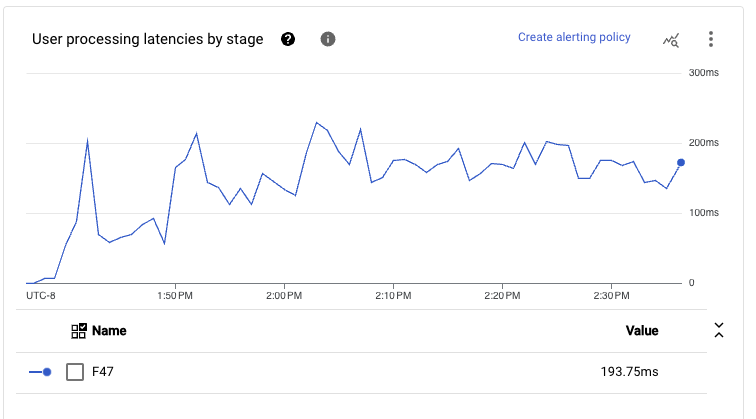
此設定的端對端處理延遲也相當低。考慮到我們管線的主要路徑已從讀取到寫入合併在單一執行階段中,我們看到即使在 p99 時,在相當大的輸送量 (如先前所述約 1 GB/s) 下,延遲時間也往往低於 300 毫秒。
回顧
為了獲得低延遲和高效的執行,最佳化 Apache Beam 串流工作負載需要仔細的分析和決策,以及正確的設定。
考慮到本文討論的案例,除了為工作負載撰寫正確的管線外,還必須考慮整體 CPU 利用率、每個階段的輸送量和延遲時間、PCollection 大小、每個階段的實際執行時間、寫入模式和傳輸格式等因素。
我們的實驗顯示,使用 StorageWrite API、自動分片寫入,以及 Avro GenericRecords 作為傳輸格式,產生了最有效率的結果。放寬寫入的一致性可以進一步提高效能。
隨附的 Github 儲存庫 包含一個測試套件,您可以使用它來複製您在 Google Cloud 專案上或使用不同執行器設定所做的分析。歡迎您隨意試用。我們隨時歡迎任何意見和 PR。