



部落格
2023/10/02
使用 Apache Beam 自製 GenAI 內容探索平台
使用 Apache Beam 自製 GenAI 內容探索平台
您的數位資產,例如文件、PDF、試算表和簡報,包含豐富的寶貴資訊,但有時很難找到您要找的內容。這篇部落格文章說明如何建立基於近乎即時的攝取處理和大型語言模型 (LLM) 的 DIY 入門架構,以從您的資產中提取有意義的資訊。該模型透過簡單的自然語言查詢,使資訊可供存取和探索。
為內容攝取建構近乎即時的處理管道可能看起來是一項複雜的任務,而且確實如此。為了讓管道建構更容易,Apache Beam 架構公開了一組強大的結構。這些結構消除了以下複雜性:與多種內容來源和目的地互動、錯誤處理和模組化。它們還以最小的努力維持彈性和可擴展性。您可以使用 Apache Beam 串流管道來完成以下任務
- 連接到解決方案的許多元件。
- 快速處理文件的內容攝取請求。
- 在攝取後幾秒鐘內即可取得文件中資訊。
LLM 通常用於提取內容並總結儲存在許多不同位置的資訊。組織可以使用 LLM 快速找到分散在多年來撰寫的多個文件中的相關資訊。這些資訊可能採用不同的格式,或者文件可能太長且複雜而無法快速閱讀和理解。使用 LLM 處理此內容,讓使用者更容易找到他們需要的資訊。
請按照本指南中的步驟建立用於資料提取、內容攝取和儲存的可擴充自訂解決方案。了解如何使用 Google Cloud 產品和生成式 AI 產品來啟動基於 LLM 的解決方案的開發。Google Cloud 的設計旨在簡單易用、可擴充且具彈性,因此您可以將其作為進一步擴展或實驗的起點。
高階流程
在此工作流程中,內容擷取和查詢互動是完全分開的。外部內容擁有者可以傳送儲存在 Google 文件或二進位文字格式的文件,並收到攝取請求的追蹤 ID。攝取程序會取得文件的內容,並建立可設定大小的區塊。每個文件區塊都用於產生嵌入。這些嵌入以 768 維向量的形式表示內容語義。給定文件識別碼和區塊識別碼,您可以將嵌入儲存在向量資料庫中以進行語義比對。此程序對於將使用者查詢情境化至關重要。
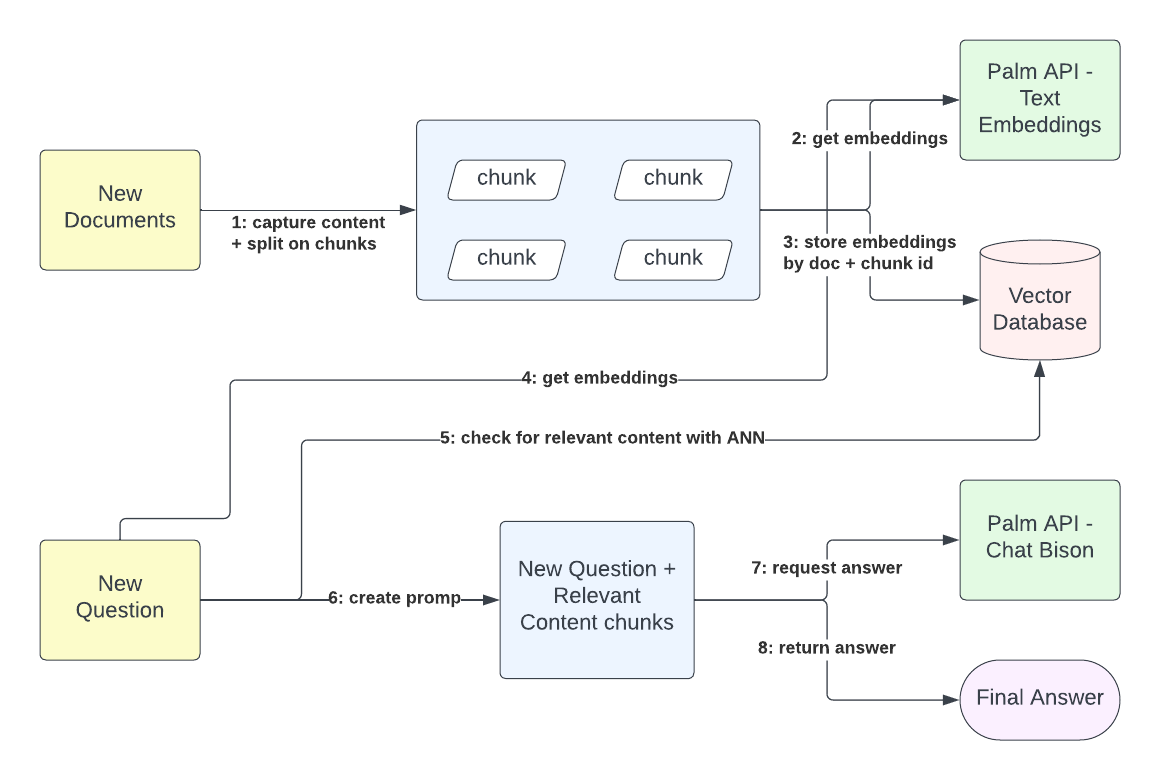
查詢解析程序不直接依賴資訊攝取。使用者會收到基於查詢請求當下所攝取內容的相關答案。即使平台沒有儲存任何相關內容,平台也會傳回聲明它沒有相關內容的答案。因此,查詢解析程序首先從查詢內容和先前存在的上下文(例如與平台的先前交換)產生嵌入,然後將這些嵌入與從內容儲存的現有嵌入向量進行比對。當平台有正面比對時,它會擷取內容嵌入所代表的純文字內容。最後,透過使用查詢的文字表示和比對內容的文字表示,平台會向 LLM 發出請求,以提供對原始使用者查詢的最終答案。
解決方案的元件
使用 Google Cloud 服務的低操作功能來建立一組高度可擴充的功能。您可以將解決方案分為兩個主要元件:服務層和內容攝取管道。服務層充當文件攝取和使用者查詢的進入點。這是一組透過 Cloud Run 公開的簡單 REST 資源,並使用 Quarkus 和用戶端程式庫來存取其他服務(Vertex AI 模型、Cloud Bigtable 和 Pub/Sub)實作。內容攝取管道包含以下元件
- 一個串流管道,可從使用者內容所在的任何位置擷取使用者內容。
- 一個將此內容的意義提取為一組多維向量(文字嵌入)的程序。
- 一個簡化知識內容和使用者查詢之間內容比對的儲存系統(向量資料庫)。
- 另一個儲存系統,將知識表示與實際內容對應,形成查詢的彙總內容。
- 一個能夠理解彙總內容,並透過提示工程傳遞有意義答案的模型。
- 基於 HTTP 和 gRPC 的服務。
這些元件共同為內容探索平台提供全面且簡單的實作。
工作流程架構
本節說明不同元件如何互動。
元件的依賴關係
下圖顯示平台整合的所有元件。它還顯示解決方案的元件與 Google Cloud 服務之間存在的所有依賴關係。
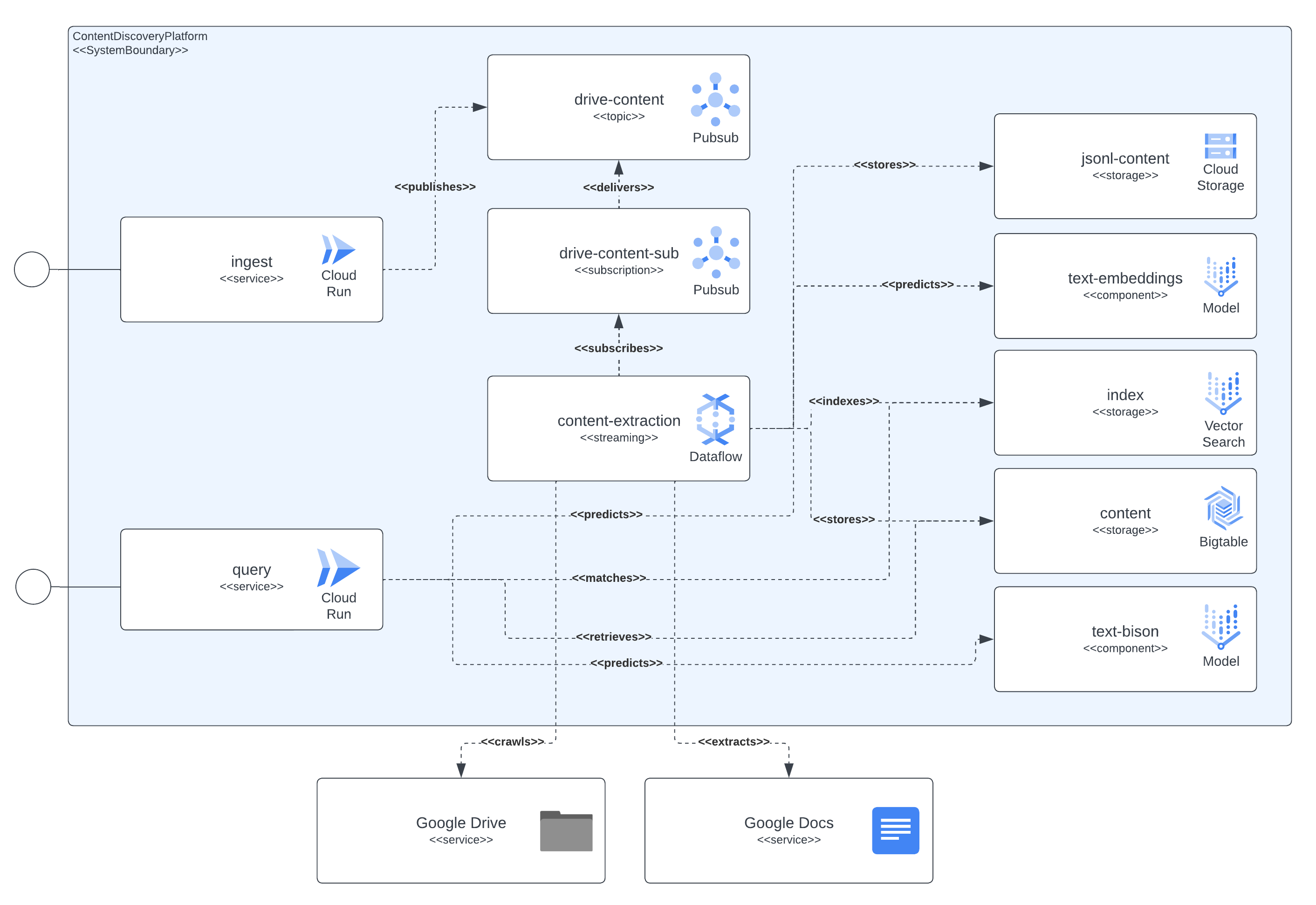
如圖所示,內容提取元件是負責擷取文件內容的中心環節,它也從嵌入模型中擷取語義意義,並將相關資料(區塊文字內容、區塊嵌入、JSON-L 內容)儲存在持久性儲存系統中以供日後使用。Pub/Sub 資源是串流管道和非同步處理之間的橋樑,擷取使用者攝取請求、來自攝取管道潛在錯誤的重試(例如在文件已傳送以進行攝取但尚未授與權限的情況下,在幾分鐘後觸發重試)和內容重新整理事件(管道會定期掃描攝取的文件,檢閱最新版本,並定義是否應觸發內容重新整理)。
內容提取元件會擷取文件的內容,並將其分成區塊。它還使用 LLM 互動來計算從提取的內容產生的嵌入。然後,它將相關資料(區塊文字內容、區塊嵌入、JSON-L 內容)儲存在持久性儲存系統中以供日後使用。Pub/Sub 資源連接串流管道和非同步處理,擷取以下動作
- 使用者攝取請求
- 來自攝取管道錯誤的重試,例如當文件傳送以進行攝取但遺失存取權限時
- 內容重新整理事件(管道會定期掃描攝取的文件、檢閱最新版本,並決定是否觸發內容重新整理)
此外,CloudRun 在公開服務、與許多 Google Cloud 服務互動以解決使用者查詢或攝取請求方面發揮重要作用。例如,在解決查詢請求時,服務將
- 透過與嵌入模型互動來請求計算使用者查詢的嵌入
- 使用查詢嵌入表示從 Vertex AI 向量搜尋(先前稱為比對引擎)中尋找鄰近比對
- 使用其識別碼從 BigTable 擷取這些比對向量的文字內容,以便將 LLM 提示情境化
- 最後,建立對 VertexAI Chat-Bison 模型的請求,產生系統將傳遞給使用者查詢的回應。
Google Cloud 產品
本節說明解決方案中使用的 Google Cloud 產品和服務,以及它們的用途。
Cloud Build:所有容器映像(包括服務和管道)都是使用 Cloud Build 直接從原始碼建置的。使用 Cloud Build 可簡化解決方案部署期間的程式碼散佈。
CloudRun:解決方案的服務進入點由 CloudRun 部署並自動調整規模。
Pub/Sub:Pub/Sub 主題和訂閱佇列會將 Google 雲端硬碟或獨立內容的所有攝取請求排入佇列,並將請求傳遞到管道。
Dataflow:多語言串流 Apache Beam 管道會處理攝取請求。這些請求是從 Pub/Sub 訂閱傳送到管道的。管道會從 Google 文件、Google 雲端硬碟 URL 和獨立二進位編碼文字內容中提取內容。然後,它會產生內容區塊。這些區塊會傳送到其中一個 Vertex AI 基礎模型以進行嵌入表示。文件中的嵌入和區塊會傳送到 Vertex AI 向量搜尋和 Cloud Bigtable 以進行索引和快速存取。最後,攝取的文件會以 JSON-L 格式儲存在 Google Cloud Storage 中,可用於微調 Vertex AI 模型。透過使用 Dataflow 執行 Apache Beam 串流管道,您可以最大限度地減少調整資源規模所需的操作。如果您有大量攝取請求,Dataflow 可以將延遲時間保持在不到一分鐘內。
Vertex AI - 向量搜尋:向量搜尋是一種高效能、低延遲的向量資料庫。這些向量資料庫通常稱為向量相似度搜尋或近似最近鄰 (ANN) 服務。我們使用向量搜尋索引來儲存所有攝取的文件嵌入作為意義表示。這些嵌入會依區塊和文件 ID 編製索引。稍後,這些識別碼可用於將使用者查詢情境化,並透過提供直接從 BigTable 上儲存的文件內容對應中提取的知識來豐富對 LLM 發出的請求(使用相同的區塊文件識別碼)。
Cloud BigTable:此儲存系統在可預測的規模下,依識別碼提供低延遲搜尋。考慮到請求解決的低延遲,它非常適合使用者查詢和平台元件互動之間的線上交換。它用於儲存從文件中提取的內容,因為它是按區塊和文件識別碼編製索引的。每當使用者向查詢服務發出請求,並且在查詢文字嵌入被解析並與現有內容比對後,就會使用文件和區塊 ID 來擷取文件內容,該內容將用作請求正在使用的 LLM 回答的內容。此外,BigTable 也用於追蹤使用者與平台之間的對話交換,進一步豐富包含在傳送到 LLM 的請求中的內容(嵌入、摘要、聊天問答)。
Vertex AI - 文字嵌入模型:文字嵌入是文字片段的濃縮向量(數值)表示。如果兩個文字片段在語義上相似,則它們對應的嵌入將會位於嵌入向量空間中彼此接近的位置。如需更多詳細資訊,請參閱取得文字嵌入。這些嵌入在處理文件內容和查詢服務時,會由攝取管道直接使用,作為將使用者查詢語義與向量搜尋中索引的現有內容比對的輸入。
Vertex AI - 文字摘要模型: Text-bison 是 PaLM 2 LLM 的名稱,它能理解、摘要和產生文字。Text-bison 可以建立的內容類型包括文件摘要、問題解答和分類所提供輸入內容的標籤。我們使用此 LLM 來摘要先前維護的對話,目的是豐富使用者的查詢並更好地嵌入匹配。總之,使用者不必包含其問題的所有上下文,我們會從對話歷史中提取並摘要這些內容。
Vertex AI - 文字聊天模型: Chat-bison 是 PaLM 2 LLM,擅長語言理解、語言生成和對話。此聊天模型經過微調,可進行自然的多輪對話,非常適合需要來回互動的程式碼文字任務。我們使用此 LLM 來提供解決方案使用者查詢的答案,包括雙方之間的對話歷史,並使用解決方案中儲存的內容來豐富模型的上下文。
提取管道
內容提取管道是平台的中心。它負責處理內容擷取請求、提取文件內容並從該內容計算嵌入,最後將資料儲存在專用的儲存系統中,這些系統將用於查詢服務元件以進行快速存取。
高階檢視
如前所述,該管道是使用 Apache Beam 框架實作,並在 GCP 的 Dataflow 服務上以串流方式執行。
透過使用 Apache Beam 和 Dataflow,我們可以確保最低延遲(次分鐘處理時間)、低作業 (無需在流量隨時間激增時手動擴展或縮減管道、工作站回收、更新等),並具有高度可觀察性(提供清楚且豐富的效能指標)。
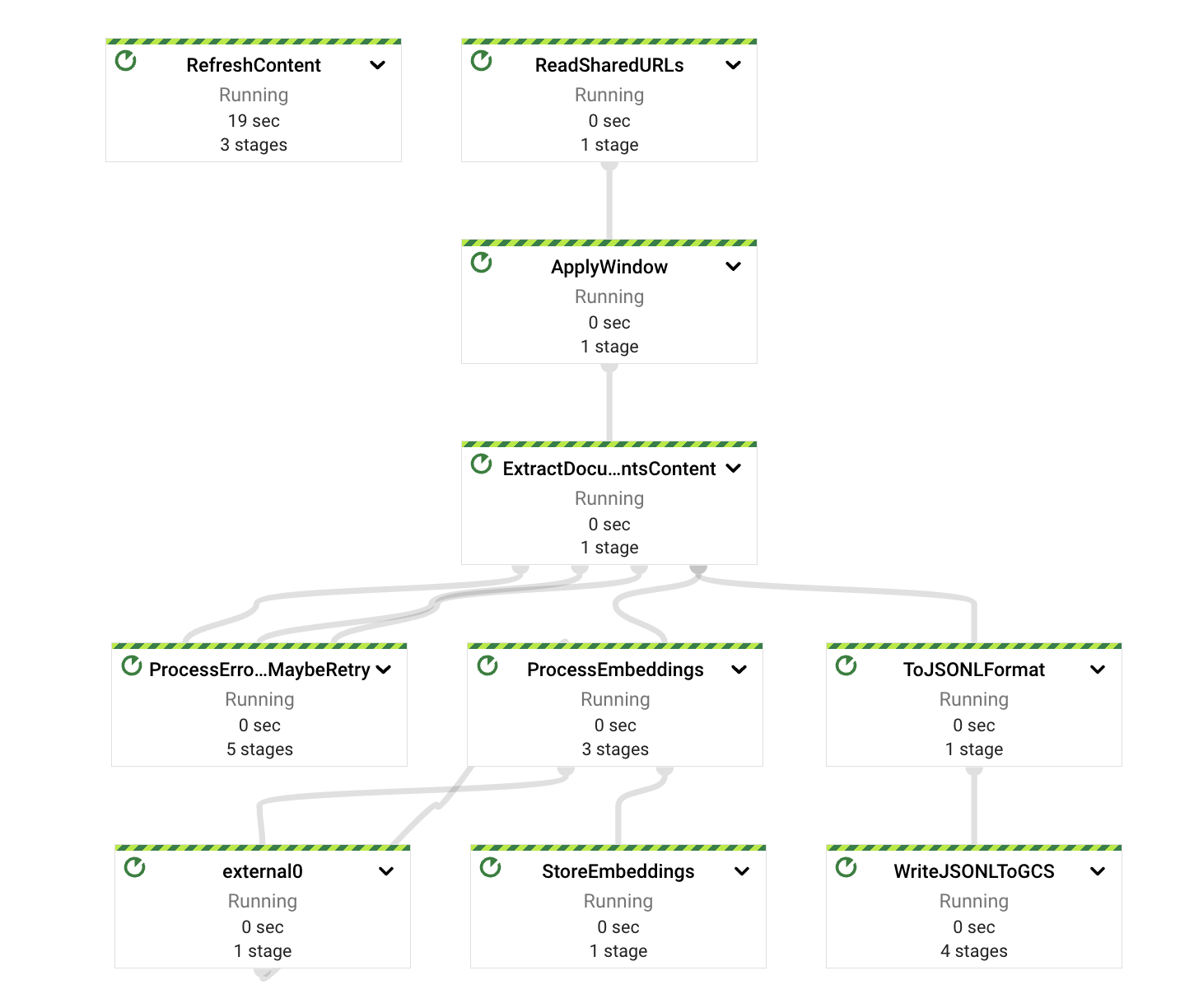
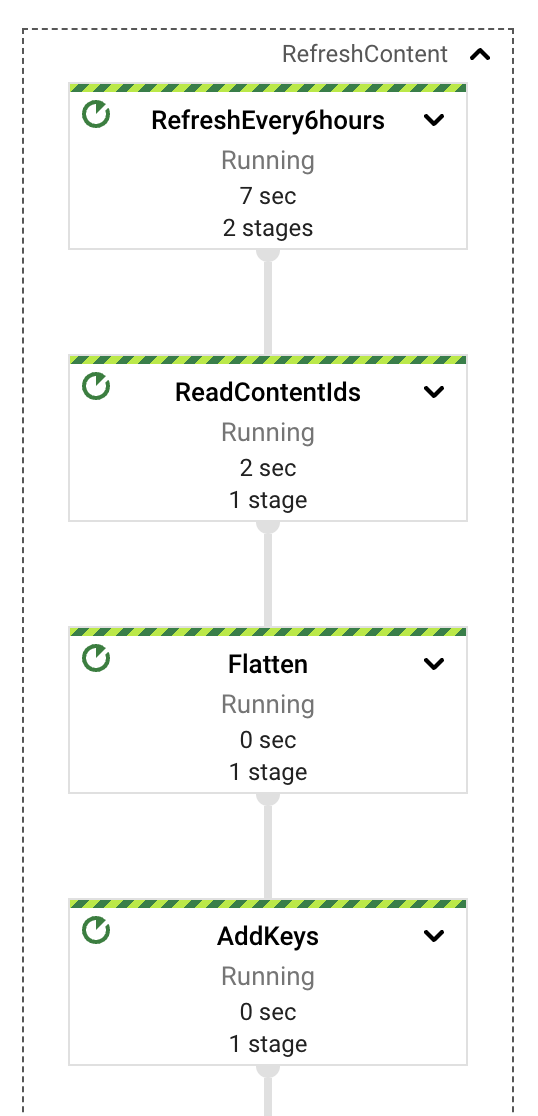
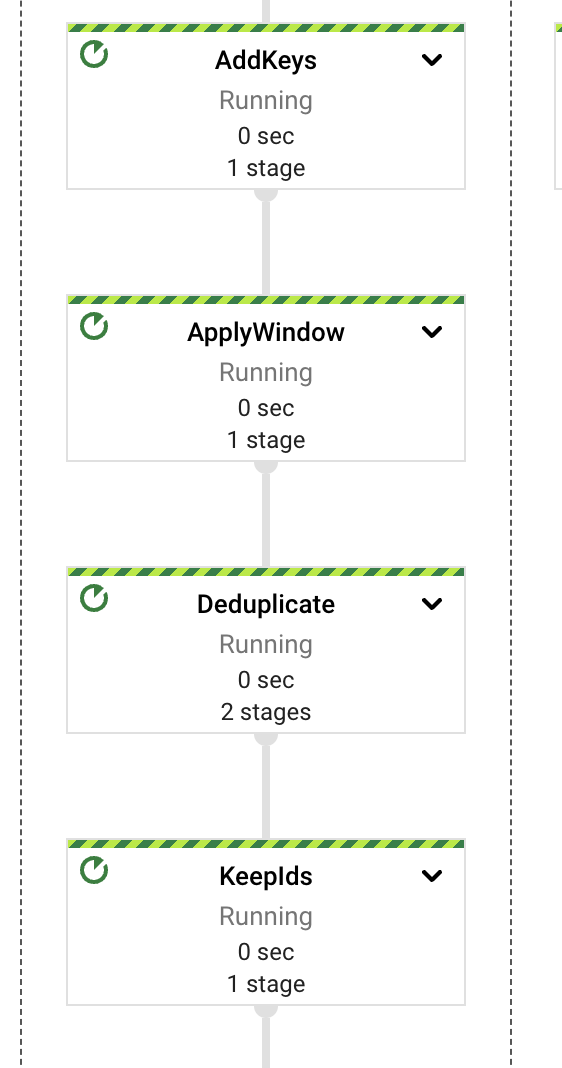
在高階層面上,該管道將提取、計算、錯誤處理和儲存責任分離在不同的元件或 PTransform 上。如圖所示,訊息是從 PubSub 訂閱中讀取,然後立即在內容提取之前包含在視窗定義中。
每個 PTransform 都可以展開,以揭示有關實作的底層階段的更多詳細資訊。我們將在以下章節中深入探討每個階段。
該管道是使用多語言方法實作,主要元件是以 Java 語言 (JDK 版本 17) 編寫,而那些與嵌入計算相關的元件則是以 Python (版本 3.11) 編寫,因為 Vertex AI API 用戶端可用於此語言。
內容提取
內容提取元件負責檢閱擷取請求承載,並決定(根據事件屬性)是否需要從事件本身 (自含內容、以文字為基礎的文件二進位編碼) 擷取內容,或從 Google 雲端硬碟擷取內容。
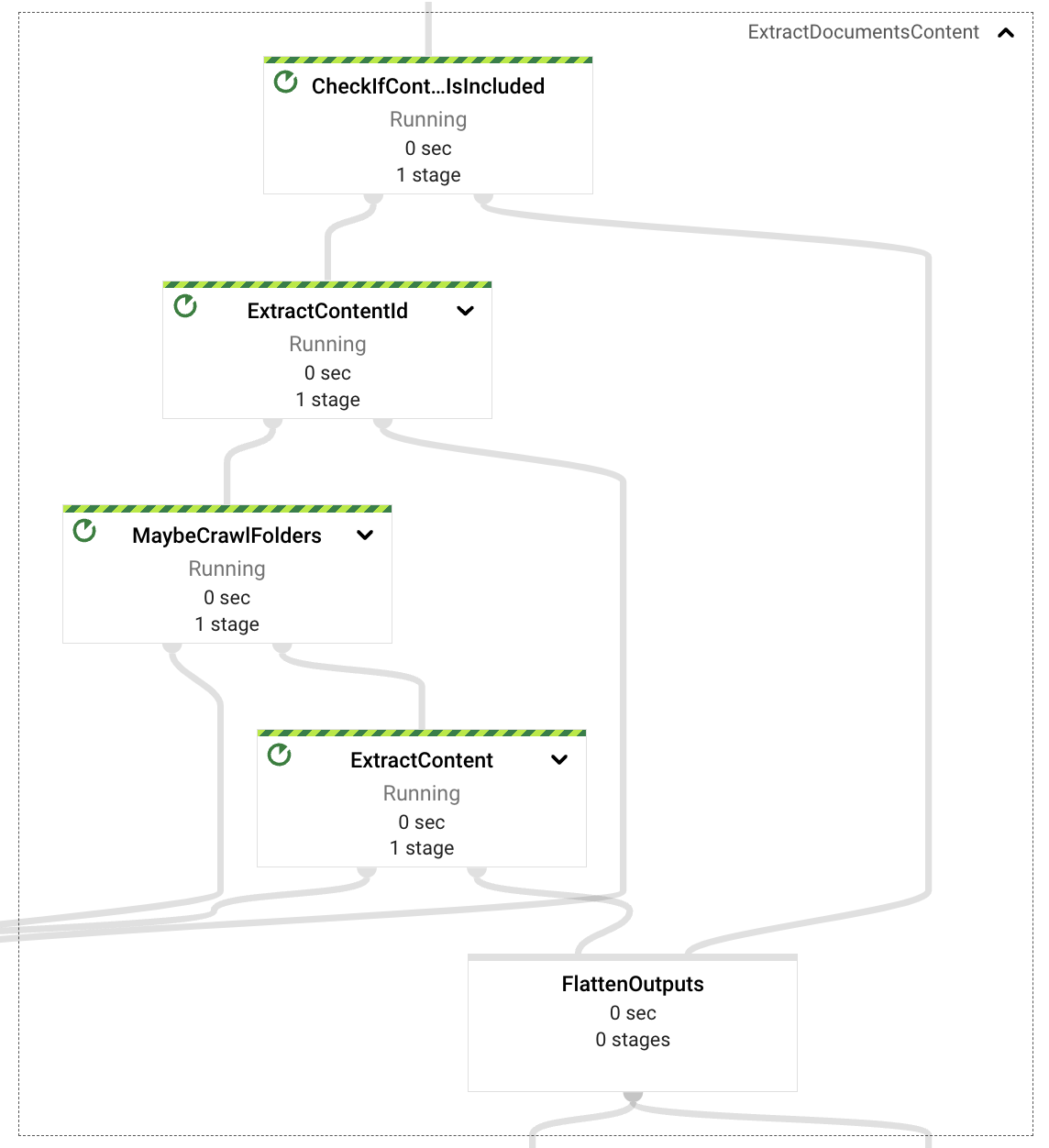
在自含文件的情況下,管道將提取文件 ID 並以段落格式化文件,以供稍後進行嵌入處理。
當需要從 Google 雲端硬碟擷取時,管道將檢查事件中提供的 URL 是否指向 Google 雲端硬碟資料夾或單一檔案格式(支援的格式為文件、試算表和簡報)。如果是資料夾,管道將以遞迴方式爬取資料夾的內容,擷取所有支援格式的檔案,如果是單一文件,則只會傳回該文件。
最後,從擷取請求擷取所有檔案參考後,會從檔案中擷取文字內容(此 PoC 未實作影像支援)。該內容也將傳遞至嵌入處理階段,包括文件識別碼和段落形式的內容。
錯誤處理
在內容提取過程的每個階段,可能會遇到多個錯誤,例如格式錯誤的擷取請求、不符合規範的 URL、缺少雲端硬碟資源的權限、缺少檔案資料擷取的權限。
在所有這些情況下,專用元件將捕獲這些潛在錯誤,並根據錯誤的性質來定義是否應重試事件,或將事件傳送至「死信」GCS 值區以供稍後檢查。
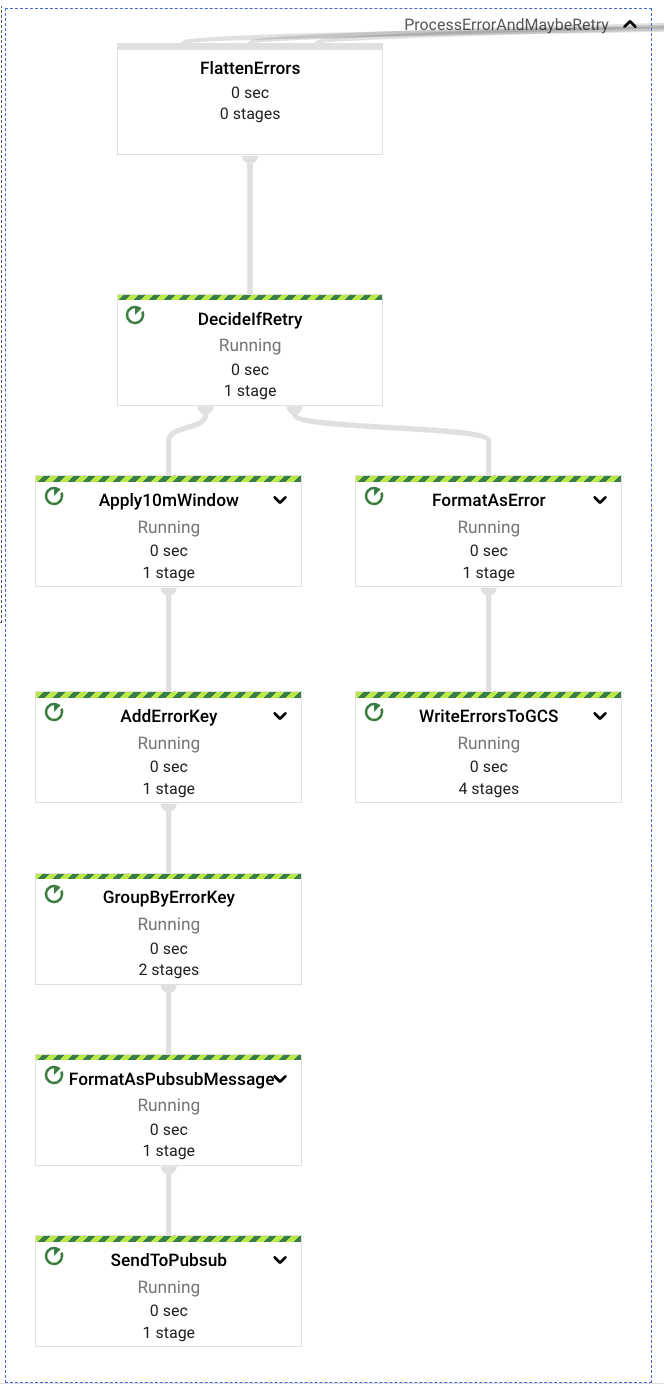
最終錯誤,或那些不會重試的錯誤,是那些與不良請求格式相關的錯誤(事件本身或屬性內容,例如格式錯誤或錯誤的 URL 等)。
可重試的錯誤是那些與內容存取和缺少權限相關的錯誤。請求的解決速度可能快於手動為執行管道的服務帳戶提供正確權限,以存取擷取請求中包含的資源(Google 雲端硬碟資料夾或檔案)的過程。在偵測到可重試的錯誤時,管道將暫停重試 10 分鐘,然後再將訊息重新傳送至上游 PubSub 主題;每個錯誤最多重試 5 次,然後再傳送至「死信」GCS 值區。
在所有以「死信」目的地結束的事件中,檢查和重新處理都必須以手動流程完成。
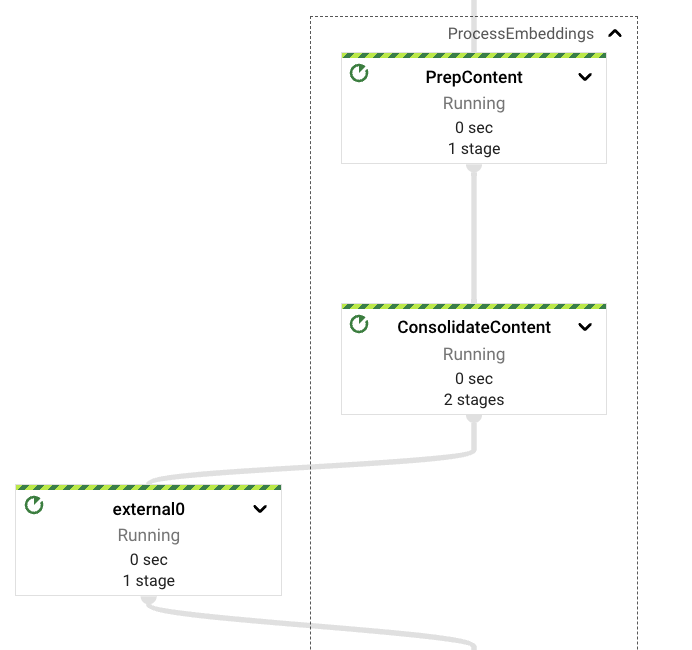
處理嵌入
一旦從請求中提取了內容,或從 Google 雲端硬碟檔案中擷取了內容,管道將觸發嵌入計算過程。如前所述,與 Vertex AI 基礎模型 API 的互動是以 Python 語言實作。因此,我們需要以 Java 類型格式化提取的內容,這些類型可以直接轉換為 Python 世界中存在的類型。這些類型是鍵值對(在 Python 中為 2 個元素的元組)、字串(兩種語言中都可用)和可迭代物件(兩種語言中也可用)。我們本可以在兩種語言中實作編碼器來支援自訂傳輸類型,但為了清楚和簡潔起見,我們選擇不這麼做。
在計算內容的嵌入之前,我們決定引入「重新混洗」步驟,使輸出與下游階段保持一致,目的是避免在發生錯誤時重複內容提取步驟。這應避免對 Google 雲端硬碟相關 API 上現有的存取配額造成壓力。
然後,管道會將內容分割成可設定的大小,並具有可設定的重疊,對於一般的有效資料提取來說,很難獲得好的參數,因此我們選擇使用較小的區塊,並採用較小的重疊係數作為預設設定,以提高文件結果的多樣性(至少這是我們從取得的經驗結果中看到的)。
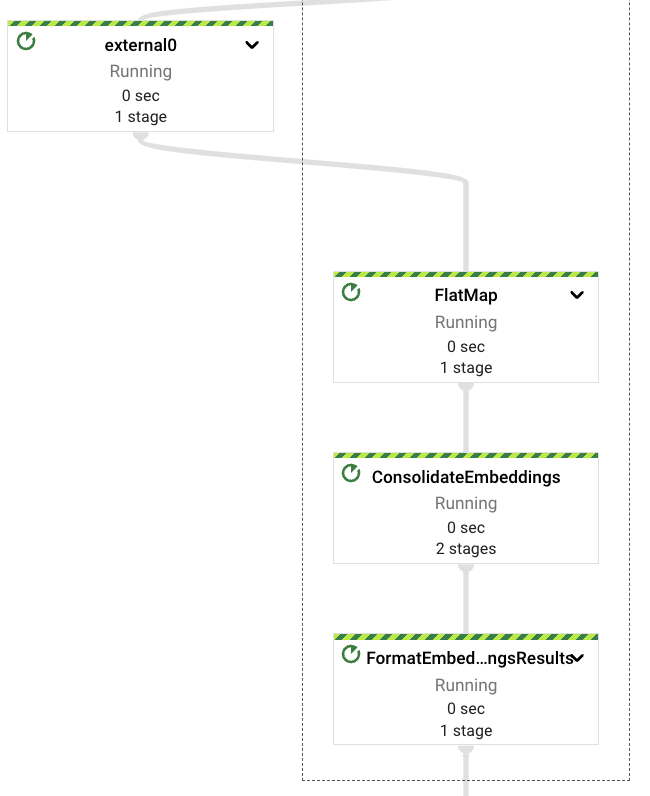
一旦從嵌入 Vertex AI LLM 擷取嵌入向量,我們將再次合併它們,避免在發生下游錯誤時重複此步驟。
值得注意的是,此管道是使用用戶端 SDK 直接與 Vertex AI 模型互動,Apache Beam 已經透過 RunInference PTransform 提供對此互動的支援(請參閱此處的範例)。
內容儲存
一旦計算出從擷取的文件中提取的內容區塊的嵌入,我們需要將向量儲存在可搜尋的儲存空間中,並儲存與這些嵌入相關聯的文字內容。稍後,我們將在查詢服務中使用嵌入向量作為語意匹配,並使用與這些嵌入對應的文字內容作為 LLM 上下文,以改善和引導回應預期。
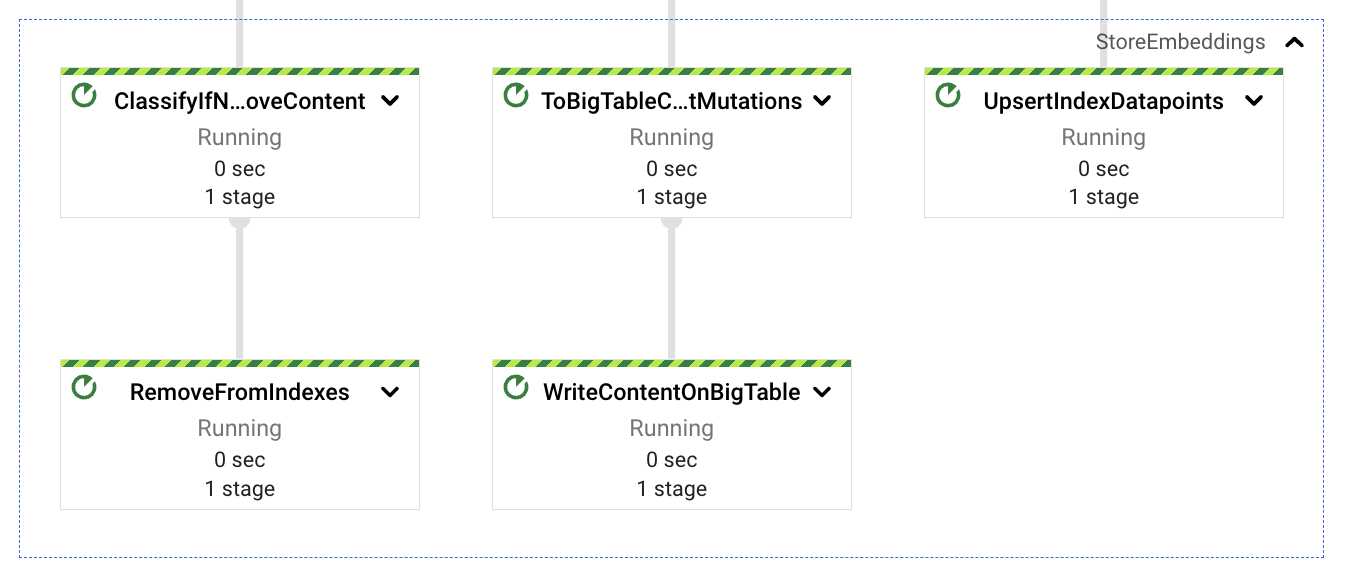
考慮到這一點,我們將合併的嵌入分成 3 個路徑,一個路徑將向量儲存在 Vertex AI 向量搜尋中(使用簡單的 REST 呼叫),另一個路徑將文字內容儲存在 BigTable 中(用於語意匹配後的低延遲擷取),最後一個路徑則作為潛在的內容重新整理或重新擷取(稍後會詳細介紹)。這三個路徑都使用擷取的文件識別碼作為動作中的相關資料,此索引鍵是由文件名稱(如果有的話)、文件識別碼和區塊序號組成。使用區塊識別碼的原因是基於後續更新的想法。內容的增加將產生較大量的區塊,而更新所有區塊將能始終獲得最新的資料;相反地,內容的減少將會為文件的內容產生較少的區塊計數,這個數字差異可用來刪除剩餘的孤立索引區塊(來自最新版文件中不再存在的內容)。
內容重新整理
最後一個管道元件是最簡單的,至少在概念上是如此。從 Google 雲端硬碟擷取文件後,外部使用者可以在其中產生更新,導致索引的內容過時。我們在同一個串流管道中實作一個簡單的定期流程,該流程將負責檢閱已擷取的文件,並查看是否需要進行內容更新。我們使用 GenerateSequence 轉換來產生定期脈衝(預設為每 6 小時一次),這將觸發 BigTable 的掃描,以擷取所有已擷取的文件識別碼。有了這些識別碼,我們就可以查詢 Google 雲端硬碟中每個文件的最新更新時間戳記,並使用該標記來決定是否需要更新。
如果需要更新文件的內容,我們只需將擷取請求傳送至上游 PubSub 主題,並讓管道針對此新事件執行其流程即可。由於我們正在處理更新嵌入和清除那些不再存在的嵌入,我們應該能夠處理大部分的添加(只要這些是文字更新,目前不處理以影像為基礎的內容)。
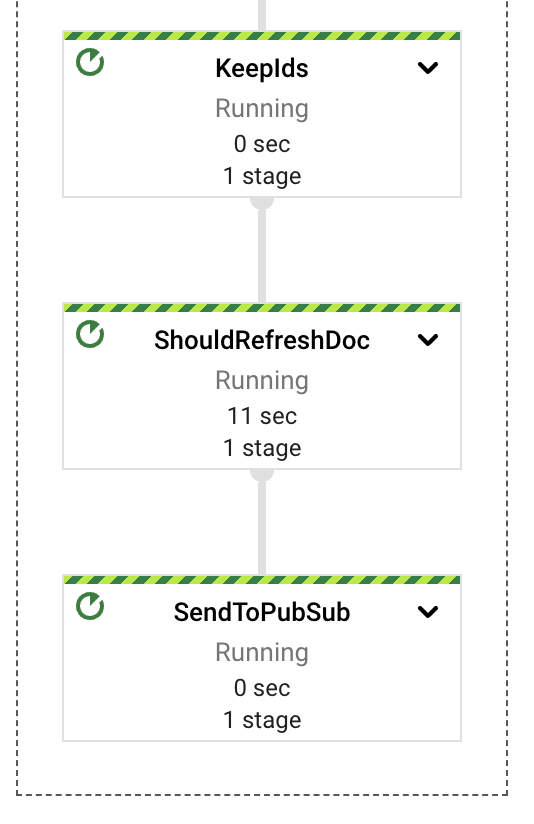
此任務可以作為個別的作業執行,可能是定期以批次形式排定的作業。這將降低成本、提供單獨的錯誤領域,並提供更可預測的自動調整規模行為。但是,為了示範起見,最好只使用單一作業。
接下來,我們將重點介紹解決方案如何與外部用戶端互動,以進行擷取和內容探索使用案例。
互動設計
該解決方案旨在盡可能簡化平台擷取和查詢的互動。此外,由於擷取部分可能涉及與多個服務互動,並暗示重試或內容重新整理,因此我們決定將兩者分開並設為非同步,讓外部使用者不必在等待請求解決時封鎖自己。
互動範例
在 GCP 專案中部署平台後,與服務互動的簡單方法是使用 Web 用戶端,curl 就是一個很好的範例。此外,由於端點已驗證,用戶端需要在請求標頭中包含其憑證才能獲得存取權限。
以下是內容擷取的互動範例
$ > curl -X POST -H "Content-Type: application/json" -H "Authorization: Bearer $(gcloud auth print-identity-token)" https://<service-address>/ingest/content/gdrive -d $'{"url":"https://drive.google.com/drive/folders/somefolderid"}' | jq .
# response from service
{
"status": "Ingestion trace id: <some identifier>"
}
在這個案例中,當擷取請求發送到 Pub/Sub 主題進行處理後,服務將返回追蹤識別碼,該識別碼會對應到 Pub/Sub 訊息識別碼。請注意,提供的 URL 可以是 Google 文件或 Google 雲端硬碟資料夾。如果是後者,擷取程序將會遞迴地爬取資料夾的內容,以取得所有包含的文件及其內容。
接下來,是一個內容查詢互動的範例,與先前的範例非常相似。
$ > curl -X POST \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $(gcloud auth print-identity-token)" \
https://<service-address>/query/content \
-d $'{"text":"summarize the benefits of using VertexAI foundational models for Generative AI applications", "sessionId": ""}' \
| jq .
# response from service
{
"content": "VertexAI Foundation Models are a set of pre-trained models that can be used to accelerate the development of machine learning applications. They are available for a variety of tasks, including natural language processing, computer vision, and recommendation systems.\n\nVertexAI Foundation Models can be used to improve the performance of Generative AI applications by providing a starting point for model development. They can also be used to reduce the amount of time and effort required to train a model.\n\nIn addition, VertexAI Foundation Models can be used to improve the accuracy and robustness of Generative AI applications. This is because they are trained on large datasets and are subject to rigorous quality control.\n\nOverall, VertexAI Foundation Models can be a valuable resource for developers who are building Generative AI applications. They can help to accelerate the development process, reduce the cost of development, and improve the performance and accuracy of applications.",
"previousConversationSummary": "",
"sourceLinks": [
{
"link": "<possibly some ingested doc url/id>",
"distance": 0.7233397960662842
}
],
"citationMetadata": [
{
"citations": []
}
],
"safetyAttributes": [
{
"categories": [],
"scores": [],
"blocked": false
}
]
}
平台將會回應用 LLM 產生的文字回應,並且會包含內容的分類、引述的元數據以及用於產生回應的內容來源連結(如果有的話)(例如,先前平台擷取的 Google 文件連結)。
在與服務互動時,一個好的查詢通常會返回好的結果。查詢越清楚,就越容易理解其含義,並且會將更準確的資訊發送到 LLM 以檢索答案。但是,在每次與服務互動時都必須在短語中包含查詢上下文的所有細節,可能會非常麻煩且困難。針對這種情況,平台可以使用提供的會話識別碼,該識別碼將用於儲存使用者與平台之間的所有先前互動。這應該有助於實作更好地理解初始查詢嵌入的匹配,甚至在模型請求中提供更簡潔的上下文資訊。以下是一個上下文互動的範例。
$ > curl -X POST \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $(gcloud auth print-identity-token)" \
https://<service-address>/query/content \
-d $'{"text":"summarize the benefits of using VertexAI foundational models for Generative AI applications?", "sessionId": "some-session-id"}' \
| jq .
# response from service
{
"content": "VertexAI Foundational Models are a suite of pre-trained models that can be used to accelerate the development of Generative AI applications. These models are available in a variety of languages and domains, and they can be used to generate text, images, audio, and other types of content.\n\nUsing VertexAI Foundational Models can help you to:\n\n* Reduce the time and effort required to develop Generative AI applications\n* Improve the accuracy and quality of your models\n* Access the latest research and development in Generative AI\n\nVertexAI Foundational Models are a powerful tool for developers who want to create innovative and engaging Generative AI applications.",
…
}
$ > curl -X POST \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $(gcloud auth print-identity-token)" \
https://<service-address>/query/content \
-d $'{"text":"describe the available LLM models?", "sessionId": "some-session-id"}' \
| jq .
# response from service
{
"content": "The VertexAI Foundational Models suite includes a variety of LLM models, including:\n\n* Text-to-text LLMs: These models can generate text based on a given prompt. They can be used for tasks such as summarization, translation, and question answering.\n* Image-to-text LLMs: These models can generate text based on an image. They can be used for tasks such as image captioning and description generation.\n* Audio-to-text LLMs: These models can generate text based on an audio clip. They can be used for tasks such as speech recognition and transcription.\n\nThese models are available in a variety of languages, including English, Spanish, French, German, and Japanese. They can be used to create a wide range of Generative AI applications, such as chatbots, customer service applications, and creative writing tools.",
…
}
$ > curl -X POST \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $(gcloud auth print-identity-token)" \
https://<service-address>/query/content \
-d $'{"text":"do rate limit apply for those LLMs?", "sessionId": "some-session-id"}' \
| jq .
# response from service
{
"content": "Yes, there are rate limits for the VertexAI Foundational Models. The rate limits are based on the number of requests per second and the total number of requests per day. For more information, please see the [VertexAI Foundational Models documentation](https://cloud.google.com/vertex-ai/docs/foundational-models#rate-limits).",
…
}
$ > curl -X POST \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $(gcloud auth print-identity-token)" \
https://<service-address>/query/content \
-d $'{"text":"care to share the price?", "sessionId": "some-session-id"}' \
| jq .
# response from service
{
"content": "The VertexAI Foundational Models are priced based on the number of requests per second and the total number of requests per day. For more information, please see the [VertexAI Foundational Models pricing page](https://cloud.google.com/vertex-ai/pricing#foundational-models).",
…
}
使用提示:如果突然更改主題,有時最好使用新的會話識別碼。
部署
作為平台解決方案的一部分,有一組腳本可協助部署所有不同的組件。透過執行 start.sh 並設定正確的參數(GCP 專案、Terraform 狀態儲存貯體和平台執行個體的名稱),腳本將負責建置程式碼、部署所需的容器(服務端點容器和 Dataflow Python 自訂容器)、使用 Terraform 部署所有 GCP 資源,最後部署管線。也可以透過將額外參數傳遞給啟動腳本來修改管線的執行,例如:start.sh <gcp 專案> <狀態儲存貯體名稱> <執行名稱> "--update" 將會就地更新內容擷取管線。
此外,如果只想專注於部署特定的組件,則已包含其他腳本來協助處理這些特定任務(建置解決方案、部署基礎架構、部署管線、部署服務等)。
解決方案注意事項
此解決方案旨在作為學習範例。擷取管線的許多組態值和安全性限制僅作為範例提供。該解決方案不會傳播已擷取內容的現有存取控制列表 (ACL)。因此,所有可以存取服務端點的使用者都可以存取來自原始文件的已擷取內容摘要。
關於原始程式碼的注意事項
內容探索平台的原始程式碼可在 Github 上取得。您可以在任何 Google Cloud 專案中執行它。該儲存庫包含整合服務、多語言擷取管線以及透過 Terraform 進行部署自動化的原始程式碼。如果您部署此範例,可能需要長達 90 分鐘才能建立和設定所有需要的資源。README 檔案包含有關部署先決條件和範例 REST 互動的其他文件。