



部落格
2024/06/20
使用 Flink 執行器在 Kubernetes 上部署 Python 管線
使用 Flink 執行器在 Kubernetes 上部署 Python 管線
Apache Flink Kubernetes Operator 作為控制平面,管理 Apache Flink 應用程式的完整部署生命週期。使用 Operator,我們可以簡化 Apache Beam 管線的部署和管理。
在這篇文章中,我們使用 Apache Beam 和 Python SDK 開發管線,並透過 Apache Flink 執行器將其部署在 Apache Flink 集群上。首先,我們在 minikube 集群上部署 Apache Kafka 集群,因為管線使用 Kafka 主題作為其資料來源和接收器。然後,我們將管線開發為 Python 套件,並將該套件添加到自訂 Docker 映像檔,以便外部執行 Python 使用者程式碼。對於部署,我們使用 Flink Kubernetes Operator 建立 Flink 工作階段叢集,並使用 Kubernetes 工作部署管線。最後,我們透過使用 Python 生產者應用程式將訊息傳送到輸入 Kafka 主題,來檢查應用程式的輸出。
在 Flink 上執行 Python Beam 管線的資源
我們使用 Python SDK 開發 Apache Beam 管線,並使用 Apache Flink 執行器將其部署在 Apache Flink 集群上。雖然 Flink 集群是由 Flink Kubernetes Operator 建立的,但我們需要兩個元件才能在Flink 執行器上執行管線:job service 和 SDK harness。粗略地說,job service 將 Python 管線的詳細資訊轉換為 Flink 執行器可以理解的格式。SDK harness 執行 Python 使用者程式碼。Python SDK 提供了方便的包裝器來管理這些元件,您可以在管線選項中指定 FlinkRunner 來使用它,例如 --runner=FlinkRunner。job service 會自動管理。為了簡單起見,我們將自己的 SDK harness 作為 sidecar 容器。此外,我們還需要 Java IO Expansion Service,因為管線使用 Apache Kafka 主題作為其資料來源和接收器,而 Kafka Connector I/O 是以 Java 開發的。簡單來說,擴展服務用於序列化 Java SDK 的資料。
設定 Kafka 集群
Apache Kafka 集群是使用 minikube 集群上的 Strimzi Operator 部署的。我們安裝 Strimzi 0.39.0 版和 Kubernetes 1.25.3 版。安裝 minikube CLI 和 Docker 之後,您可以透過指定 Kubernetes 版本來建立 minikube 集群。您可以在 GitHub 儲存庫 中找到此部落格文章的原始程式碼。
minikube start --cpus='max' --memory=20480 \
--addons=metrics-server --kubernetes-version=v1.25.3部署 Strimzi operator
GitHub 儲存庫保留了可用於部署 Strimzi operator、Kafka 集群和 Kafka 管理應用程式的資訊清單檔案。若要下載不同版本的 operator,請透過指定版本下載相關的資訊清單檔案。預設情況下,資訊清單檔案假設資源部署在 myproject 名稱空間中。但是,由於我們將它們部署在 default 名稱空間中,因此我們需要變更資源名稱空間。我們使用 sed 變更資源名稱空間。
若要部署 operator,請使用 kubectl create 命令。
## Download and deploy the Strimzi operator.
STRIMZI_VERSION="0.39.0"
## Optional: If downloading a different version, include this step.
DOWNLOAD_URL=https://github.com/strimzi/strimzi-kafka-operator/releases/download/$STRIMZI_VERSION/strimzi-cluster-operator-$STRIMZI_VERSION.yaml
curl -L -o kafka/manifests/strimzi-cluster-operator-$STRIMZI_VERSION.yaml \
${DOWNLOAD_URL}
# Update the namespace from myproject to default.
sed -i 's/namespace: .*/namespace: default/' kafka/manifests/strimzi-cluster-operator-$STRIMZI_VERSION.yaml
## Deploy the Strimzi cluster operator.
kubectl create -f kafka/manifests/strimzi-cluster-operator-$STRIMZI_VERSION.yaml驗證 Strimzi Operator 是否作為 Kubernetes 部署執行。
kubectl get deploy,rs,po
# NAME READY UP-TO-DATE AVAILABLE AGE
# deployment.apps/strimzi-cluster-operator 1/1 1 1 2m50s
# NAME DESIRED CURRENT READY AGE
# replicaset.apps/strimzi-cluster-operator-8d6d4795c 1 1 1 2m50s
# NAME READY STATUS RESTARTS AGE
# pod/strimzi-cluster-operator-8d6d4795c-94t8c 1/1 Running 0 2m49s部署 Kafka 集群
我們部署了一個包含單一代理程式和 Zookeeper 節點的 Kafka 集群。它在連接埠 9092 和 29092 上分別具有內部和外部接聽器。外部接聽器用於從 minikube 集群外部存取 Kafka 集群。此外,該集群設定為允許自動建立主題(auto.create.topics.enable: "true"),並且預設分割區數量設定為 3(num.partitions: 3)。
# kafka/manifests/kafka-cluster.yaml
apiVersion: kafka.strimzi.io/v1beta2
kind: Kafka
metadata:
name: demo-cluster
spec:
kafka:
version: 3.5.2
replicas: 1
resources:
requests:
memory: 256Mi
cpu: 250m
limits:
memory: 512Mi
cpu: 500m
listeners:
- name: plain
port: 9092
type: internal
tls: false
- name: external
port: 29092
type: nodeport
tls: false
storage:
type: jbod
volumes:
- id: 0
type: persistent-claim
size: 20Gi
deleteClaim: true
config:
offsets.topic.replication.factor: 1
transaction.state.log.replication.factor: 1
transaction.state.log.min.isr: 1
default.replication.factor: 1
min.insync.replicas: 1
inter.broker.protocol.version: "3.5"
auto.create.topics.enable: "true"
num.partitions: 3
zookeeper:
replicas: 1
resources:
requests:
memory: 256Mi
cpu: 250m
limits:
memory: 512Mi
cpu: 500m
storage:
type: persistent-claim
size: 10Gi
deleteClaim: true
使用 kubectl create 命令部署 Kafka 集群。
kubectl create -f kafka/manifests/kafka-cluster.yamlKafka 和 Zookeeper 節點由 StrimziPodSet 自訂資源管理。它也會建立多個 Kubernetes 服務。在本系列中,我們使用以下服務
- Kubernetes 集群內的通訊
demo-cluster-kafka-bootstrap- 從用戶端和管理應用程式存取 Kafka 代理程式demo-cluster-zookeeper-client- 從管理應用程式存取 Zookeeper 節點
- 來自主機的通訊
demo-cluster-kafka-external-bootstrap- 從生產者應用程式存取 Kafka 代理程式
kubectl get po,strimzipodsets.core.strimzi.io,svc -l app.kubernetes.io/instance=demo-cluster
# NAME READY STATUS RESTARTS AGE
# pod/demo-cluster-kafka-0 1/1 Running 0 115s
# pod/demo-cluster-zookeeper-0 1/1 Running 0 2m20s
# NAME PODS READY PODS CURRENT PODS AGE
# strimzipodset.core.strimzi.io/demo-cluster-kafka 1 1 1 115s
# strimzipodset.core.strimzi.io/demo-cluster-zookeeper 1 1 1 2m20s
# NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
# service/demo-cluster-kafka-bootstrap ClusterIP 10.101.175.64 <none> 9091/TCP,9092/TCP 115s
# service/demo-cluster-kafka-brokers ClusterIP None <none> 9090/TCP,9091/TCP,8443/TCP,9092/TCP 115s
# service/demo-cluster-kafka-external-0 NodePort 10.106.155.20 <none> 29092:32475/TCP 115s
# service/demo-cluster-kafka-external-bootstrap NodePort 10.111.244.128 <none> 29092:32674/TCP 115s
# service/demo-cluster-zookeeper-client ClusterIP 10.100.215.29 <none> 2181/TCP 2m20s
# service/demo-cluster-zookeeper-nodes ClusterIP None <none> 2181/TCP,2888/TCP,3888/TCP 2m20s部署 Kafka UI
UI for Apache Kafka (kafka-ui) 是一個免費且開放原始碼的 Kafka 管理應用程式。它部署為 Kubernetes 部署。部署配置為具有單一執行個體,並且 Kafka 集群存取詳細資訊指定為環境變數。
# kafka/manifests/kafka-ui.yaml
apiVersion: v1
kind: Service
metadata:
labels:
app: kafka-ui
name: kafka-ui
spec:
type: ClusterIP
ports:
- port: 8080
targetPort: 8080
selector:
app: kafka-ui
---
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: kafka-ui
name: kafka-ui
spec:
replicas: 1
selector:
matchLabels:
app: kafka-ui
template:
metadata:
labels:
app: kafka-ui
spec:
containers:
- image: provectuslabs/kafka-ui:v0.7.1
name: kafka-ui-container
ports:
- containerPort: 8080
env:
- name: KAFKA_CLUSTERS_0_NAME
value: demo-cluster
- name: KAFKA_CLUSTERS_0_BOOTSTRAPSERVERS
value: demo-cluster-kafka-bootstrap:9092
- name: KAFKA_CLUSTERS_0_ZOOKEEPER
value: demo-cluster-zookeeper-client:2181
resources:
requests:
memory: 256Mi
cpu: 250m
limits:
memory: 512Mi
cpu: 500m
使用 kubectl create 命令部署 Kafka 管理應用程式 (kafka-ui)。
kubectl create -f kafka/manifests/kafka-ui.yaml
kubectl get all -l app=kafka-ui
# NAME READY STATUS RESTARTS AGE
# pod/kafka-ui-65dbbc98dc-zl5gv 1/1 Running 0 35s
# NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
# service/kafka-ui ClusterIP 10.109.14.33 <none> 8080/TCP 36s
# NAME READY UP-TO-DATE AVAILABLE AGE
# deployment.apps/kafka-ui 1/1 1 1 35s
# NAME DESIRED CURRENT READY AGE
# replicaset.apps/kafka-ui-65dbbc98dc 1 1 1 35s我們使用 kubectl port-forward 連線到在連接埠 8080 上的 minikube 集群中執行的 kafka-ui 伺服器。
kubectl port-forward svc/kafka-ui 8080
開發串流處理應用程式
我們將 Apache Beam 管線開發為 Python 套件,並將其新增至自訂 Docker 映像檔,該映像檔用於執行 Python 使用者程式碼 (SDK harness)。我們還會建置另一個自訂 Docker 映像檔,將 Apache Beam 的 Java SDK 新增至官方 Flink 基本映像檔。此映像檔用於部署 Flink 集群並執行Kafka Connector I/O的 Java 使用者程式碼。
Beam 管線程式碼
應用程式首先從輸入 Kafka 主題讀取文字訊息。接著,它透過分割訊息 (ReadWordsFromKafka) 來擷取單字。然後,將元素(單字)新增至 5 秒的固定時間視窗,並計算其平均長度 (CalculateAvgWordLen)。最後,我們包含視窗開始和結束時間戳記,並將更新後的元素傳送到輸出 Kafka 主題 (WriteWordLenToKafka)。
我們建立一個自訂的 Java IO 擴充服務 (get_expansion_service),並將其新增至 Kafka Connector I/O 的 ReadFromKafka 和 WriteToKafka 轉換。雖然 Kafka I/O 提供了建立該服務的功能,但它對我不起作用(或者我還不了解如何使用它)。相反地,我建立了一個自訂服務,如 Jan Lukavský 的使用 Apache Beam 建置大數據管線 中所示。擴充服務 Jar 檔案 (beam-sdks-java-io-expansion-service.jar) 必須存在於執行管線的 Kubernetes 工作 中,而 Java SDK (/opt/apache/beam/boot) 必須存在於執行器工作站中。
# beam/word_len/word_len.py
import json
import argparse
import re
import logging
import typing
import apache_beam as beam
from apache_beam import pvalue
from apache_beam.io import kafka
from apache_beam.transforms.window import FixedWindows
from apache_beam.options.pipeline_options import PipelineOptions
from apache_beam.options.pipeline_options import SetupOptions
from apache_beam.transforms.external import JavaJarExpansionService
def get_expansion_service(
jar="/opt/apache/beam/jars/beam-sdks-java-io-expansion-service.jar", args=None
):
if args == None:
args = [
"--defaultEnvironmentType=PROCESS",
'--defaultEnvironmentConfig={"command": "/opt/apache/beam/boot"}',
"--experiments=use_deprecated_read",
]
return JavaJarExpansionService(jar, ["{{PORT}}"] + args)
class WordAccum(typing.NamedTuple):
length: int
count: int
beam.coders.registry.register_coder(WordAccum, beam.coders.RowCoder)
def decode_message(kafka_kv: tuple, verbose: bool = False):
if verbose:
print(kafka_kv)
return kafka_kv[1].decode("utf-8")
def tokenize(element: str):
return re.findall(r"[A-Za-z\']+", element)
def create_message(element: typing.Tuple[str, str, float]):
msg = json.dumps(dict(zip(["window_start", "window_end", "avg_len"], element)))
print(msg)
return "".encode("utf-8"), msg.encode("utf-8")
class AverageFn(beam.CombineFn):
def create_accumulator(self):
return WordAccum(length=0, count=0)
def add_input(self, mutable_accumulator: WordAccum, element: str):
length, count = tuple(mutable_accumulator)
return WordAccum(length=length + len(element), count=count + 1)
def merge_accumulators(self, accumulators: typing.List[WordAccum]):
lengths, counts = zip(*accumulators)
return WordAccum(length=sum(lengths), count=sum(counts))
def extract_output(self, accumulator: WordAccum):
length, count = tuple(accumulator)
return length / count if count else float("NaN")
def get_accumulator_coder(self):
return beam.coders.registry.get_coder(WordAccum)
class AddWindowTS(beam.DoFn):
def process(self, avg_len: float, win_param=beam.DoFn.WindowParam):
yield (
win_param.start.to_rfc3339(),
win_param.end.to_rfc3339(),
avg_len,
)
class ReadWordsFromKafka(beam.PTransform):
def __init__(
self,
bootstrap_servers: str,
topics: typing.List[str],
group_id: str,
verbose: bool = False,
expansion_service: typing.Any = None,
label: str | None = None,
) -> None:
super().__init__(label)
self.boostrap_servers = bootstrap_servers
self.topics = topics
self.group_id = group_id
self.verbose = verbose
self.expansion_service = expansion_service
def expand(self, input: pvalue.PBegin):
return (
input
| "ReadFromKafka"
>> kafka.ReadFromKafka(
consumer_config={
"bootstrap.servers": self.boostrap_servers,
"auto.offset.reset": "latest",
# "enable.auto.commit": "true",
"group.id": self.group_id,
},
topics=self.topics,
timestamp_policy=kafka.ReadFromKafka.create_time_policy,
commit_offset_in_finalize=True,
expansion_service=self.expansion_service,
)
| "DecodeMessage" >> beam.Map(decode_message)
| "Tokenize" >> beam.FlatMap(tokenize)
)
class CalculateAvgWordLen(beam.PTransform):
def expand(self, input: pvalue.PCollection):
return (
input
| "Windowing" >> beam.WindowInto(FixedWindows(size=5))
| "GetAvgWordLength" >> beam.CombineGlobally(AverageFn()).without_defaults()
)
class WriteWordLenToKafka(beam.PTransform):
def __init__(
self,
bootstrap_servers: str,
topic: str,
expansion_service: typing.Any = None,
label: str | None = None,
) -> None:
super().__init__(label)
self.boostrap_servers = bootstrap_servers
self.topic = topic
self.expansion_service = expansion_service
def expand(self, input: pvalue.PCollection):
return (
input
| "AddWindowTS" >> beam.ParDo(AddWindowTS())
| "CreateMessages"
>> beam.Map(create_message).with_output_types(typing.Tuple[bytes, bytes])
| "WriteToKafka"
>> kafka.WriteToKafka(
producer_config={"bootstrap.servers": self.boostrap_servers},
topic=self.topic,
expansion_service=self.expansion_service,
)
)
def run(argv=None, save_main_session=True):
parser = argparse.ArgumentParser(description="Beam pipeline arguments")
parser.add_argument(
"--deploy",
dest="deploy",
action="store_true",
default="Flag to indicate whether to deploy to a cluster",
)
parser.add_argument(
"--bootstrap_servers",
dest="bootstrap",
default="host.docker.internal:29092",
help="Kafka bootstrap server addresses",
)
parser.add_argument(
"--input_topic",
dest="input",
default="input-topic",
help="Kafka input topic name",
)
parser.add_argument(
"--output_topic",
dest="output",
default="output-topic-beam",
help="Kafka output topic name",
)
parser.add_argument(
"--group_id",
dest="group",
default="beam-word-len",
help="Kafka output group ID",
)
known_args, pipeline_args = parser.parse_known_args(argv)
print(known_args)
print(pipeline_args)
# We use the save_main_session option because one or more DoFn elements in this
# workflow rely on global context. That is, a module imported at the module level.
pipeline_options = PipelineOptions(pipeline_args)
pipeline_options.view_as(SetupOptions).save_main_session = save_main_session
expansion_service = None
if known_args.deploy is True:
expansion_service = get_expansion_service()
with beam.Pipeline(options=pipeline_options) as p:
(
p
| "ReadWordsFromKafka"
>> ReadWordsFromKafka(
bootstrap_servers=known_args.bootstrap,
topics=[known_args.input],
group_id=known_args.group,
expansion_service=expansion_service,
)
| "CalculateAvgWordLen" >> CalculateAvgWordLen()
| "WriteWordLenToKafka"
>> WriteWordLenToKafka(
bootstrap_servers=known_args.bootstrap,
topic=known_args.output,
expansion_service=expansion_service,
)
)
logging.getLogger().setLevel(logging.DEBUG)
logging.info("Building pipeline ...")
if __name__ == "__main__":
run()
管線指令碼會新增至名為 word_len 的資料夾下的 Python 套件。會建立一個名為 run 的簡單模組,因為它會以模組的形式執行,例如 python -m ...。當我以指令碼形式執行管線時,遇到了錯誤。此封裝方法僅供示範使用。如需建議的封裝管線方式,請參閱 管理 Python 管線相依性。
# beam/word_len/run.py
from . import *
run()
總之,管線套件使用下列結構。
tree beam/word_len
beam/word_len
├── __init__.py
├── run.py
└── word_len.py建置 Docker 映像檔
如先前討論的,我們建置一個自訂 Docker 映像檔 (beam-python-example:1.16),並使用它來部署 Flink 集群,並執行 Kafka Connector I/O 的 Java 使用者程式碼。
# beam/Dockerfile
FROM flink:1.16
COPY --from=apache/beam_java11_sdk:2.56.0 /opt/apache/beam/ /opt/apache/beam/
我們還會建置一個自訂 Docker 映像檔 (beam-python-harness:2.56.0) 來執行 Python 使用者程式碼 (SDK harness)。從 Python SDK Docker 映像檔中,它會先安裝 Java 開發套件 (JDK) 並下載 Java IO 擴充服務 Jar 檔案。然後,Beam 管線套件會複製到 /app 資料夾。app 資料夾會新增至 PYTHONPATH 環境變數,這會使套件可搜尋。
# beam/Dockerfile-python-harness
FROM apache/beam_python3.10_sdk:2.56.0
ARG BEAM_VERSION
ENV BEAM_VERSION=${BEAM_VERSION:-2.56.0}
ENV REPO_BASE_URL=https://repo1.maven.org/maven2/org/apache/beam
RUN apt-get update && apt-get install -y default-jdk
RUN mkdir -p /opt/apache/beam/jars \
&& wget ${REPO_BASE_URL}/beam-sdks-java-io-expansion-service/${BEAM_VERSION}/beam-sdks-java-io-expansion-service-${BEAM_VERSION}.jar \
--progress=bar:force:noscroll -O /opt/apache/beam/jars/beam-sdks-java-io-expansion-service.jar
COPY word_len /app/word_len
COPY word_count /app/word_count
ENV PYTHONPATH="$PYTHONPATH:/app"
由於自訂映像檔需要在 minikube 集群中存取,因此我們將終端機的 docker-cli 指向 minikube 的 Docker 引擎。然後,我們可以使用 docker build 命令建置映像檔。
eval $(minikube docker-env)
docker build -t beam-python-example:1.16 beam/
docker build -t beam-python-harness:2.56.0 -f beam/Dockerfile-python-harness beam/部署串流處理應用程式
Beam 管線在 Flink 工作階段叢集上執行,該叢集是由 Flink Kubernetes Operator 部署的。Beam 管線部署為 Flink 作業的應用程式部署模式似乎無法運作(或者我還不了解如何運作),原因是作業提交逾時錯誤或無法上傳作業成品。部署管線後,我們會透過將文字訊息傳送到輸入 Kafka 主題來檢查應用程式的輸出。
部署 Flink Kubernetes Operator
首先,若要新增 webhook 元件,請在 minikube 集群上安裝憑證管理員。然後,使用 Helm 圖表來安裝 operator。文章中安裝的是 1.8.0 版。
kubectl create -f https://github.com/jetstack/cert-manager/releases/download/v1.8.2/cert-manager.yaml
helm repo add flink-operator-repo https://downloads.apache.org/flink/flink-kubernetes-operator-1.8.0/
helm install flink-kubernetes-operator flink-operator-repo/flink-kubernetes-operator
# NAME: flink-kubernetes-operator
# LAST DEPLOYED: Mon Jun 03 21:37:45 2024
# NAMESPACE: default
# STATUS: deployed
# REVISION: 1
# TEST SUITE: None
helm list
# NAME NAMESPACE REVISION UPDATED STATUS CHART APP VERSION
# flink-kubernetes-operator default 1 2024-06-03 21:37:45.579302452 +1000 AEST deployed flink-kubernetes-operator-1.8.0 1.8.0部署 Beam 管線
首先,建立 Flink 工作階段叢集。在資訊清單檔案中,設定通用屬性,例如 Docker 映像檔、Flink 版本、叢集組態和 pod 範本。這些屬性會套用至 Flink 作業管理員和任務管理員。此外,指定複本和資源。我們將 sidecar 容器新增至任務管理員,而這個 SDK harness 容器設定為執行 Python 使用者程式碼 - 請參閱下列作業組態。
# beam/word_len_cluster.yml
apiVersion: flink.apache.org/v1beta1
kind: FlinkDeployment
metadata:
name: word-len-cluster
spec:
image: beam-python-example:1.16
imagePullPolicy: Never
flinkVersion: v1_16
flinkConfiguration:
taskmanager.numberOfTaskSlots: "10"
serviceAccount: flink
podTemplate:
spec:
containers:
- name: flink-main-container
volumeMounts:
- mountPath: /opt/flink/log
name: flink-logs
volumes:
- name: flink-logs
emptyDir: {}
jobManager:
resource:
memory: "2048Mi"
cpu: 2
taskManager:
replicas: 1
resource:
memory: "2048Mi"
cpu: 2
podTemplate:
spec:
containers:
- name: python-harness
image: beam-python-harness:2.56.0
args: ["-worker_pool"]
ports:
- containerPort: 50000
name: harness-port
此管線是使用 Kubernetes Job 部署,並使用自訂的 SDK harness 映像檔以模組方式執行管線。前兩個引數是應用程式特定的,其餘引數則用於管線選項。如需更多關於管線引數的資訊,請參閱管線選項原始碼以及Flink Runner 文件。若要在 sidecar 容器中執行 Python 使用者程式碼,我們會將環境類型設定為 EXTERNAL,並將環境組態設定為 localhost:50000。
# beam/word_len_job.yml
apiVersion: batch/v1
kind: Job
metadata:
name: word-len-job
spec:
template:
metadata:
labels:
app: word-len-job
spec:
containers:
- name: beam-word-len-job
image: beam-python-harness:2.56.0
command: ["python"]
args:
- "-m"
- "word_len.run"
- "--deploy"
- "--bootstrap_servers=demo-cluster-kafka-bootstrap:9092"
- "--runner=FlinkRunner"
- "--flink_master=word-len-cluster-rest:8081"
- "--job_name=beam-word-len"
- "--streaming"
- "--parallelism=3"
- "--flink_submit_uber_jar"
- "--environment_type=EXTERNAL"
- "--environment_config=localhost:50000"
- "--checkpointing_interval=10000"
restartPolicy: Never
使用 kubectl create 命令部署 session 叢集和 job。session 叢集由 FlinkDeployment 自訂資源建立,並管理 job manager 部署、task manager pod 以及相關服務。當我們檢查 job 的 pod 日誌時,可以看到它執行下列任務:
- 在下載 Jar 檔後,啟動 Job Service
- 上傳管線成品
- 將管線作為 Flink job 提交
- 持續監控 job 狀態
kubectl create -f beam/word_len_cluster.yml
# flinkdeployment.flink.apache.org/word-len-cluster created
kubectl create -f beam/word_len_job.yml
# job.batch/word-len-job created
kubectl logs word-len-job-p5rph -f
# WARNING:apache_beam.options.pipeline_options:Unknown pipeline options received: --checkpointing_interval=10000. Ignore if flags are used for internal purposes.
# WARNING:apache_beam.options.pipeline_options:Unknown pipeline options received: --checkpointing_interval=10000. Ignore if flags are used for internal purposes.
# INFO:root:Building pipeline ...
# INFO:apache_beam.runners.portability.flink_runner:Adding HTTP protocol scheme to flink_master parameter: http://word-len-cluster-rest:8081
# WARNING:apache_beam.options.pipeline_options:Unknown pipeline options received: --checkpointing_interval=10000. Ignore if flags are used for internal purposes.
# DEBUG:apache_beam.runners.portability.abstract_job_service:Got Prepare request.
# DEBUG:urllib3.connectionpool:Starting new HTTP connection (1): word-len-cluster-rest:8081
# DEBUG:urllib3.connectionpool:http://word-len-cluster-rest:8081 "GET /v1/config HTTP/1.1" 200 240
# INFO:apache_beam.utils.subprocess_server:Downloading job server jar from https://repo.maven.apache.org/maven2/org/apache/beam/beam-runners-flink-1.16-job-server/2.56.0/beam-runners-flink-1.16-job-server-2.56.0.jar
# INFO:apache_beam.runners.portability.abstract_job_service:Artifact server started on port 43287
# DEBUG:apache_beam.runners.portability.abstract_job_service:Prepared job 'job' as 'job-edc1c2f1-80ef-48b7-af14-7e6fc86f338a'
# INFO:apache_beam.runners.portability.abstract_job_service:Running job 'job-edc1c2f1-80ef-48b7-af14-7e6fc86f338a'
# DEBUG:urllib3.connectionpool:Starting new HTTP connection (1): word-len-cluster-rest:8081
# DEBUG:urllib3.connectionpool:http://word-len-cluster-rest:8081 "POST /v1/jars/upload HTTP/1.1" 200 148
# DEBUG:urllib3.connectionpool:Starting new HTTP connection (1): word-len-cluster-rest:8081
# DEBUG:urllib3.connectionpool:http://word-len-cluster-rest:8081 "POST /v1/jars/e1984c45-d8bc-4aa1-9b66-369a23826921_beam.jar/run HTTP/1.1" 200 44
# INFO:apache_beam.runners.portability.flink_uber_jar_job_server:Started Flink job as a403cb2f92fecee65b8fd7cc8ac6e68a
# INFO:apache_beam.runners.portability.portable_runner:Job state changed to STOPPED
# DEBUG:urllib3.connectionpool:Starting new HTTP connection (1): word-len-cluster-rest:8081
# DEBUG:urllib3.connectionpool:Starting new HTTP connection (1): word-len-cluster-rest:8081
# DEBUG:urllib3.connectionpool:http://word-len-cluster-rest:8081 "GET /v1/jobs/a403cb2f92fecee65b8fd7cc8ac6e68a/execution-result HTTP/1.1" 200 31
# DEBUG:urllib3.connectionpool:http://word-len-cluster-rest:8081 "GET /v1/jobs/a403cb2f92fecee65b8fd7cc8ac6e68a/execution-result HTTP/1.1" 200 31
# INFO:apache_beam.runners.portability.portable_runner:Job state changed to RUNNING
# DEBUG:urllib3.connectionpool:Starting new HTTP connection (1): word-len-cluster-rest:8081
# DEBUG:urllib3.connectionpool:Starting new HTTP connection (1): word-len-cluster-rest:8081
# DEBUG:urllib3.connectionpool:http://word-len-cluster-rest:8081 "GET /v1/jobs/a403cb2f92fecee65b8fd7cc8ac6e68a/execution-result HTTP/1.1" 200 31
# DEBUG:urllib3.connectionpool:http://word-len-cluster-rest:8081 "GET /v1/jobs/a403cb2f92fecee65b8fd7cc8ac6e68a/execution-result HTTP/1.1" 200 31
# ...部署完成後,我們可以看見下列與 Flink session 叢集和 job 相關的資源。
kubectl get all -l app=word-len-cluster
# NAME READY STATUS RESTARTS AGE
# pod/word-len-cluster-7c98f6f868-d4hbx 1/1 Running 0 5m32s
# pod/word-len-cluster-taskmanager-1-1 2/2 Running 0 4m3s
# NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
# service/word-len-cluster ClusterIP None <none> 6123/TCP,6124/TCP 5m32s
# service/word-len-cluster-rest ClusterIP 10.104.23.28 <none> 8081/TCP 5m32s
# NAME READY UP-TO-DATE AVAILABLE AGE
# deployment.apps/word-len-cluster 1/1 1 1 5m32s
# NAME DESIRED CURRENT READY AGE
# replicaset.apps/word-len-cluster-7c98f6f868 1 1 1 5m32s
kubectl get all -l app=word-len-job
# NAME READY STATUS RESTARTS AGE
# pod/word-len-job-24r6q 1/1 Running 0 5m24s
# NAME COMPLETIONS DURATION AGE
# job.batch/word-len-job 0/1 5m24s 5m24s您可以使用 port 8081 上的 kubectl port-forward 命令來存取 Flink Web UI。Job 圖表顯示兩個任務。第一個任務會將文字元素加入固定的時間視窗。第二個任務會將平均字詞長度記錄傳送到輸出主題。
kubectl port-forward svc/flink-word-len-rest 8081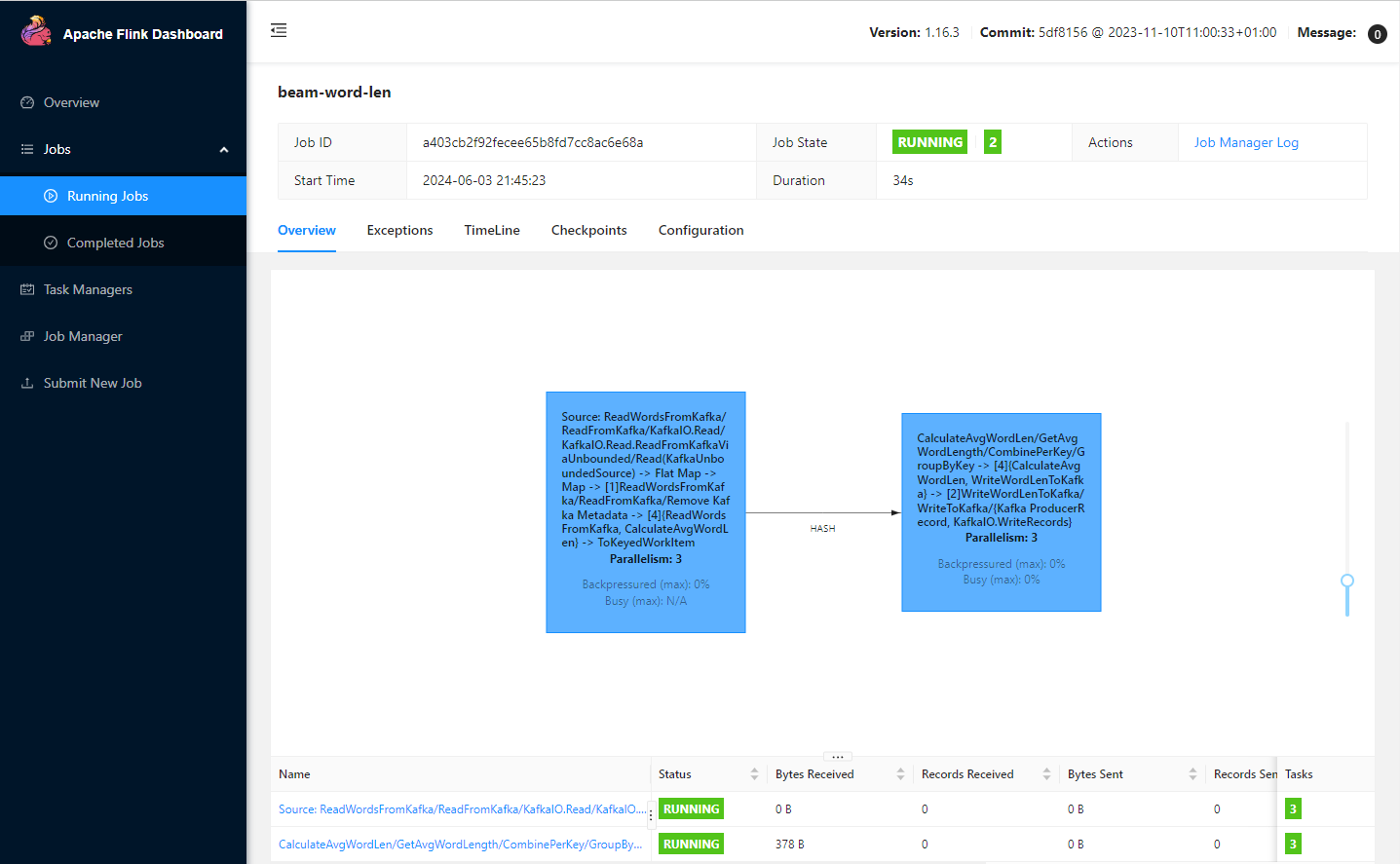
Kafka I/O 會自動建立主題(如果主題不存在),我們可以看到輸入主題已在 kafka-ui 上建立。
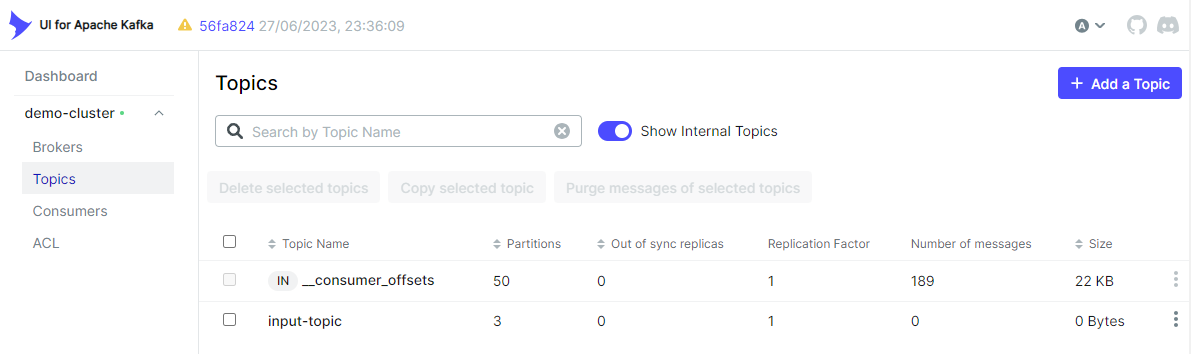
Kafka 生產者
建立一個簡單的 Python Kafka producer 以檢查應用程式的輸出。預設情況下,producer 應用程式會從 Faker 套件每秒傳送隨機文字到輸入 Kafka 主題。
# kafka/client/producer.py
import os
import time
from faker import Faker
from kafka import KafkaProducer
class TextProducer:
def __init__(self, bootstrap_servers: list, topic_name: str) -> None:
self.bootstrap_servers = bootstrap_servers
self.topic_name = topic_name
self.kafka_producer = self.create_producer()
def create_producer(self):
"""
Returns a KafkaProducer instance
"""
return KafkaProducer(
bootstrap_servers=self.bootstrap_servers,
value_serializer=lambda v: v.encode("utf-8"),
)
def send_to_kafka(self, text: str, timestamp_ms: int = None):
"""
Sends text to a Kafka topic.
"""
try:
args = {"topic": self.topic_name, "value": text}
if timestamp_ms is not None:
args = {**args, **{"timestamp_ms": timestamp_ms}}
self.kafka_producer.send(**args)
self.kafka_producer.flush()
except Exception as e:
raise RuntimeError("fails to send a message") from e
if __name__ == "__main__":
producer = TextProducer(
os.getenv("BOOTSTRAP_SERVERS", "localhost:29092"),
os.getenv("TOPIC_NAME", "input-topic"),
)
fake = Faker()
num_events = 0
while True:
num_events += 1
text = fake.text()
producer.send_to_kafka(text)
if num_events % 5 == 0:
print(f"<<<<<{num_events} text sent... current>>>>\n{text}")
time.sleep(int(os.getenv("DELAY_SECONDS", "1")))
使用 kubectl port-forward 命令將 Kafka bootstrap server 暴露於 port 29092。執行 Python 腳本以啟動 producer 應用程式。
kubectl port-forward svc/demo-cluster-kafka-external-bootstrap 29092
python kafka/client/producer.py我們可以看到輸出主題 (output-topic-beam) 已在 kafka-ui 上建立。
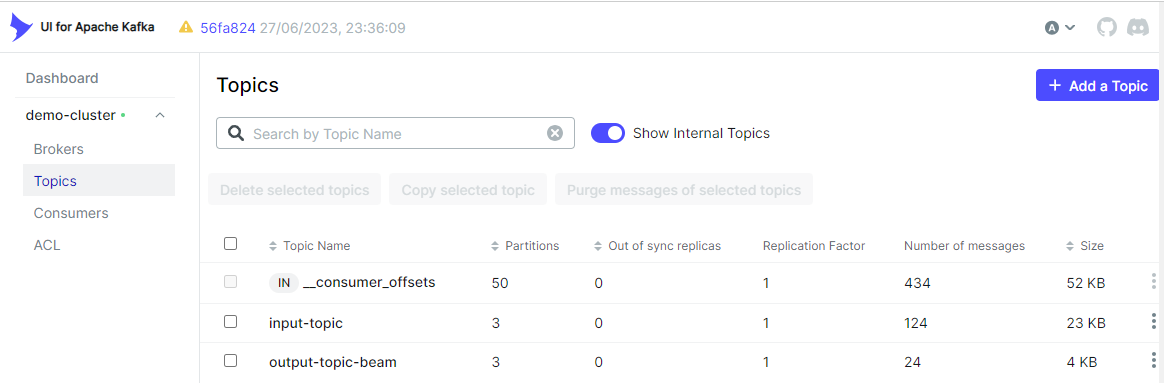
此外,我們也可以在 Topics 標籤中檢查輸出訊息是否如預期建立。
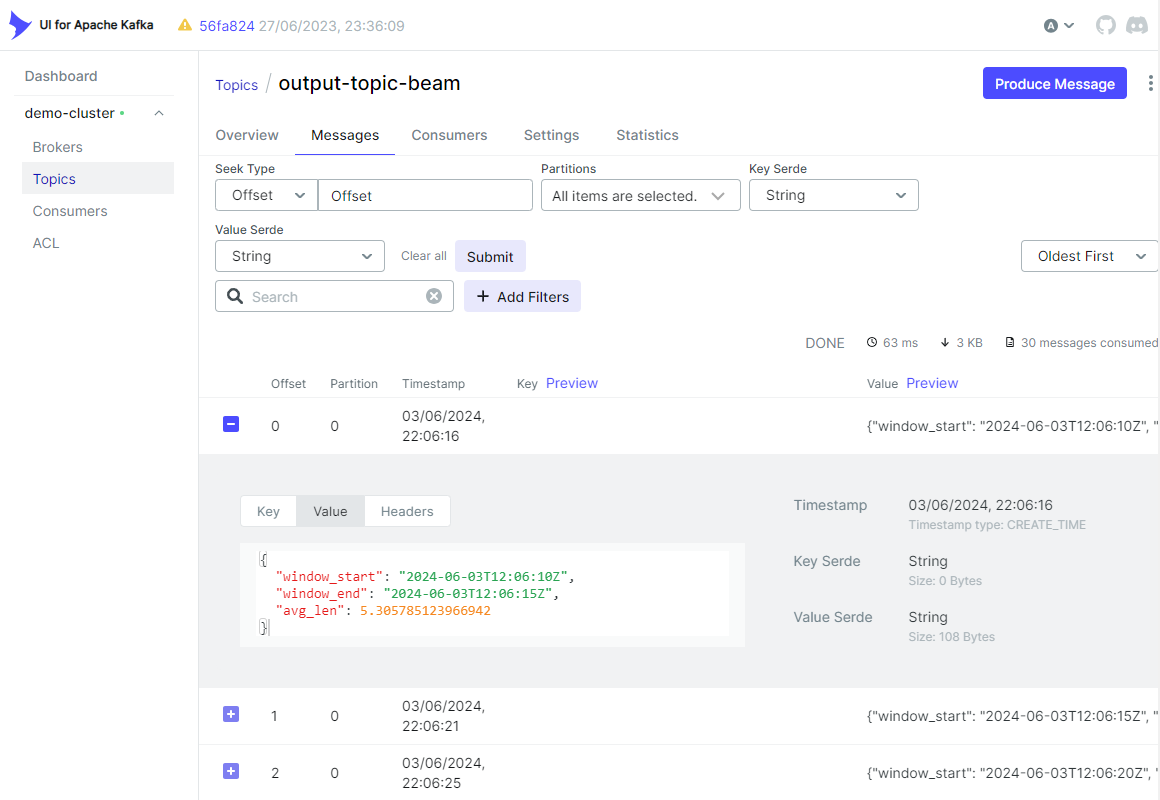
刪除資源
請依照以下步驟刪除 Kubernetes 資源和 minikube 叢集。
## Delete the Flink Operator and related resources.
kubectl delete -f beam/word_len_cluster.yml
kubectl delete -f beam/word_len_job.yml
helm uninstall flink-kubernetes-operator
helm repo remove flink-operator-repo
kubectl delete -f https://github.com/jetstack/cert-manager/releases/download/v1.8.2/cert-manager.yaml
## Delete the Kafka cluster and related resources.
STRIMZI_VERSION="0.39.0"
kubectl delete -f kafka/manifests/kafka-cluster.yaml
kubectl delete -f kafka/manifests/kafka-ui.yaml
kubectl delete -f kafka/manifests/strimzi-cluster-operator-$STRIMZI_VERSION.yaml
## Delete the minikube.
minikube delete