



部落格
2022/04/28
在筆記本中執行 Beam SQL
簡介
Beam SQL 讓 Beam 使用者可以使用 SQL 語句查詢 PCollection。 Interactive Beam 提供 Apache Beam 和 Jupyter Notebooks (先前稱為 IPython Notebooks) 之間的整合,使管線原型設計和資料探索更加快速和容易。您可以按照其文件,在您自己的裝置上設定您自己的筆記本使用者介面(例如,JupyterLab 或經典的 Jupyter Notebooks)。或者,您可以選擇為您完成所有工作的託管解決方案。您可以自由選擇您喜歡的任何筆記本使用者介面。為簡單起見,這篇文章不介紹筆記本環境設定,而是使用 Apache Beam Notebooks,它提供雲端託管的 JupyterLab 環境,讓 Beam 使用者可以反覆開發管線、檢查管線圖表,並在讀取-評估-列印迴圈 (REPL) 工作流程中解析個別的 PCollection。
在這篇文章中,您將看到如何使用 beam_sql 這個筆記本 魔法指令,在筆記本中執行 Beam SQL 並檢查結果。
文章的最後,它還示範了如何在生產環境中使用 beam_sql 魔法指令,例如將其作為 Dataflow 上的一次性作業執行。這是可選的。要遵循這些步驟,您應該在 Google Cloud Platform 中擁有一個專案,並啟用 必要的 API,並且您應該擁有足夠的權限來建立 Google Cloud Storage 儲存貯體(或使用現有的儲存貯體)、查詢公開的 Google Cloud BigQuery 資料集,以及執行 Dataflow 作業。
如果您選擇使用雲端託管的筆記本解決方案,一旦您的 Google Cloud 專案準備就緒,您將需要建立一個 Apache Beam Notebooks 執行個體,並開啟 JupyterLab 網頁介面。請按照以下網址提供的說明操作:https://cloud.google.com/dataflow/docs/guides/interactive-pipeline-development#launching_an_notebooks_instance
熟悉環境
登陸頁面
在啟動您自己的筆記本使用者介面後:例如,如果使用 Apche Beam Notebooks,在按一下 OPEN JUPYTERLAB 連結後,您將登陸筆記本環境的預設啟動器頁面。
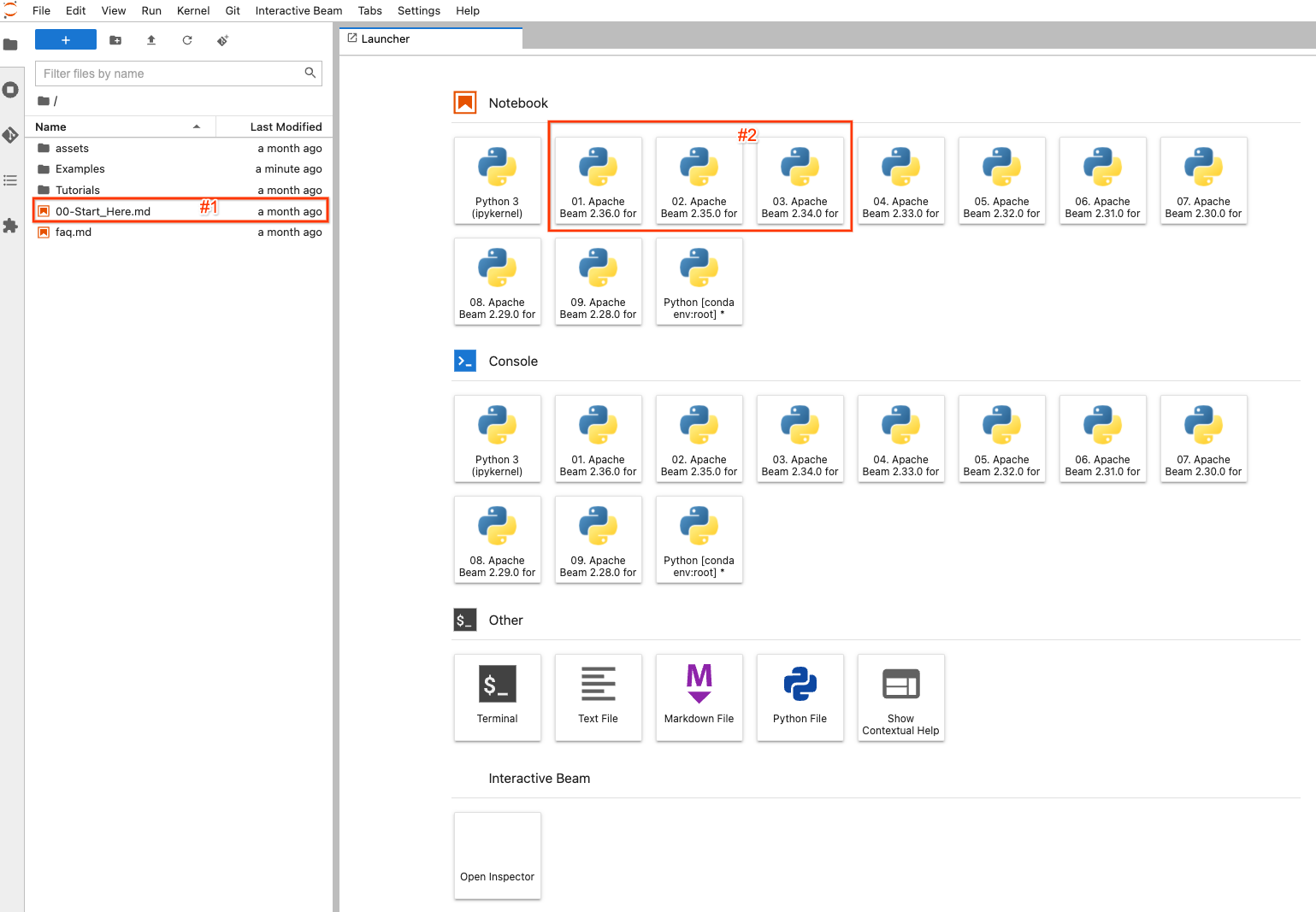
在左側,有一個檔案總管,用於檢視筆記本執行個體上的範例、教學和資產。為了輕鬆瀏覽檔案,您可以按兩下 00-Start_Here.md(螢幕截圖中的 #1)檔案,以檢視有關檔案的詳細資訊。
在右側,它會顯示 JupyterLab 的預設啟動器頁面。要建立並開啟一個全新的筆記本檔案,並使用選定的 Apache Beam 版本進行程式碼編寫,請按一下已安裝 Apache Beam >=2.34.0 的項目之一 (#2)(因為 beam_sql 是在 2.34.0 中引入的)。
建立/開啟筆記本
例如,如果您按一下具有 Apache Beam 2.36.0 的影像按鈕,您會看到一個已建立並開啟的 Untitled.ipynb 檔案。
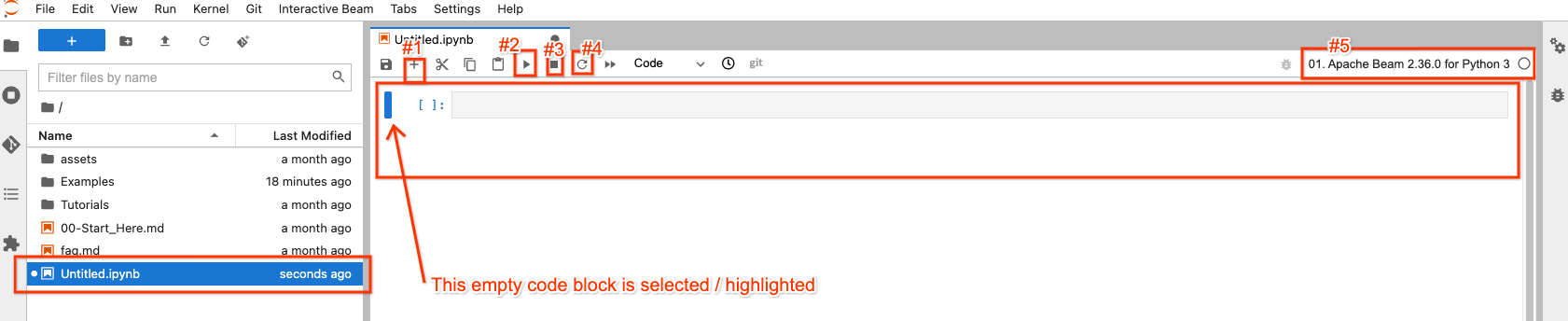
在檔案總管中,您的新筆記本檔案已建立為 Untitled.ipynb。
在右側,在開啟的筆記本中,頂部有 4 個按鈕,您可能會最常與它們互動
- #1:在選取/醒目標示的程式碼區塊之後插入一個空的程式碼區塊
- #2:執行選取/醒目標示的區塊中的程式碼
- #3:如果您的程式碼執行停滯,則中斷程式碼執行
- #4:「重新啟動核心」:清除程式碼執行的所有狀態,並從頭開始
右上角 (#5) 有一個按鈕,供您在需要時選擇不同的 Apache Beam 版本,因此它不是一成不變的。
您可以隨時按兩下檔案總管中的檔案來開啟它,而無需建立新的檔案。
Beam SQL
beam_sql 魔法指令
beam_sql 是 IPython 自訂魔法指令。如果您不熟悉魔法指令,這裡有一些 內建範例。在遠端叢集/服務上生產之前,當使用 SQL 建立 Beam 管線原型時,這是一種方便的方法,可以針對已知/測試資料來源在本機驗證您的查詢。
Apache Beam Notebooks 環境已預先載入 beam_sql 魔法指令和基本 apache-beam 模組,因此您可以直接使用它們而無需額外匯入。如果您在其他地方設定了自己的筆記本,也可以透過 %load_ext apache_beam.runners.interactive.sql.beam_sql_magics 和 apache-beam 模組顯式載入魔法指令。
您可以輸入
%beam_sql -h
然後執行程式碼以了解如何使用魔法指令
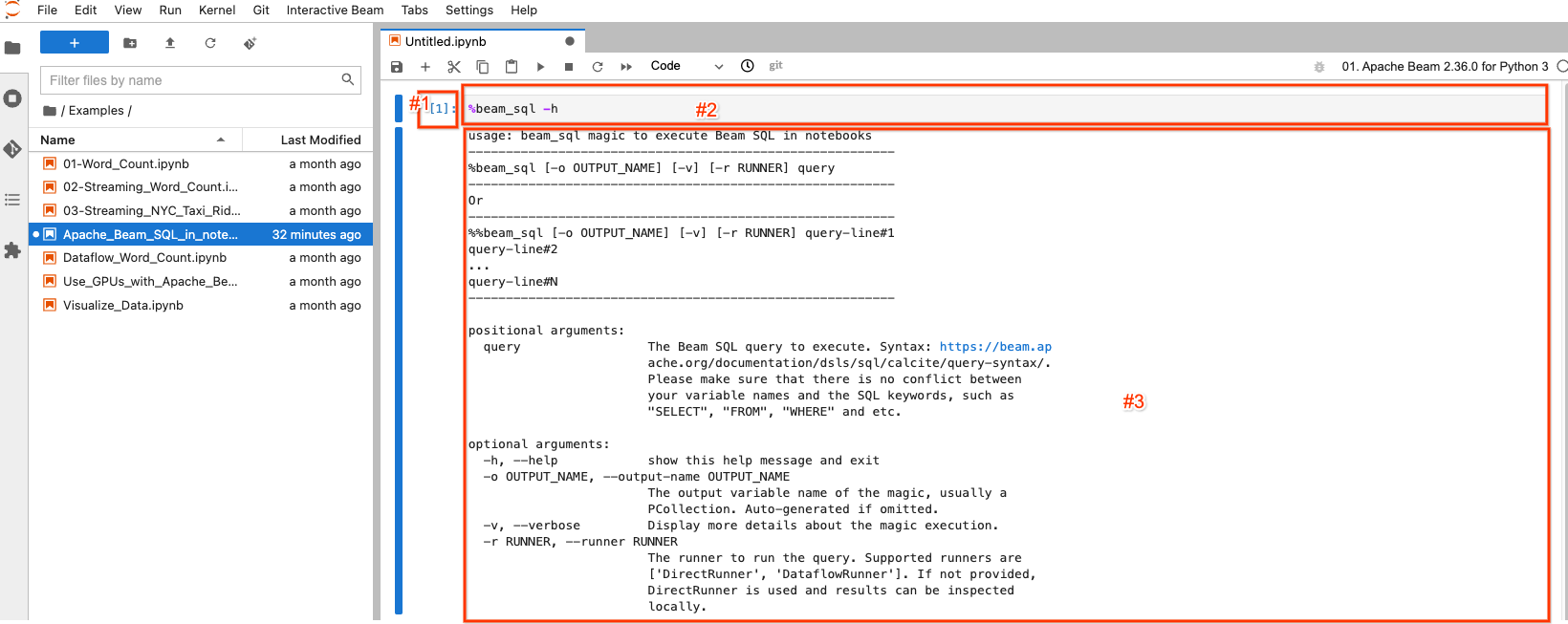
選取/醒目標示的區塊稱為筆記本儲存格。它主要有 3 個組件
- #1:執行計數。
[1]表示此區塊是第一個執行的程式碼。對於您執行的每一段程式碼,它都會增加 1,即使您重新執行相同的程式碼也是如此。[ ]表示此區塊未執行。 - #2:儲存格輸入:執行的程式碼。
- #3:儲存格輸出:程式碼執行的輸出。這裡包含
beam_sql魔法指令的說明文件。
建立 PCollection
在建立 PCollection 時,Beam SQL 有 3 種情況
- 使用 Beam SQL 從常數值建立 PCollection
%%beam_sql -o pcoll
SELECT CAST(1 AS INT) AS id, CAST('foo' AS VARCHAR) AS str, CAST(3.14 AS DOUBLE) AS flt

beam_sql 魔法指令會建立並輸出一個名為 pcoll 的 PCollection,其 element_type 類似於 BeamSchema_...(id: int32, str: str, flt: float64)。
請注意,您尚未明確建立 Beam 管線。您會得到一個 PCollection,因為 beam_sql 魔法指令總是會隱式建立一個管線來執行您的 SQL 查詢。為了使用每個欄位的類型資訊來保存元素,Beam 會自動建立一個 結構描述 作為所建立 PCollection 的 element_type。稍後您將學習更多關於結構描述感知 PCollection 的資訊。
- 使用 Beam SQL 查詢 PCollection
您可以使用先前 SQL 的輸出(或任何正常 Beam PTransforms 產生的任何結構描述感知 PCollection)作為輸入來鏈接另一個 SQL,以產生新的 PCollection。
請注意:如果您命名輸出 PCollection,請確保它在您的筆記本中是唯一的,以避免覆蓋不同的 PCollection。
%%beam_sql -o id_pcoll
SELECT id FROM pcoll

- 使用 Beam SQL 連接多個 PCollection
您可以從單個查詢中查詢多個 PCollection。
%%beam_sql -o str_with_same_id
SELECT id, str FROM pcoll JOIN id_pcoll USING (id)

現在您已經學習如何使用 beam_sql 魔法指令來建立 PCollection 並檢查其結果。
提示:如果您不小心刪除了一些筆記本儲存格輸出,您可以隨時透過呼叫 ib.show(pcoll_name) 或 ib.collect(pcoll_name) 來檢查 PCollection 的內容,其中 ib 代表「Interactive Beam」(了解更多)。
結構描述感知 PCollection
beam_sql 魔法指令提供了靈活性,可以無縫混合 SQL 和非 SQL Beam 語句來建立管線,甚至可以在 Dataflow 上執行它們。但是,Beam SQL 查詢的每個 PCollection 都需要有一個 結構描述。對於 beam_sql 魔法指令,建議在需要結構描述時使用 typing.NamedTuple。您可以瀏覽下面的範例,以了解更多關於結構描述感知 PCollection 的詳細資訊。
設定
在此範例的設定中,您將
- 使用內建的
%pip魔法指令安裝 PyPI 套件names:您將使用該模組來產生一些隨機英文名稱作為原始資料輸入。 - 使用
NamedTuple定義一個結構描述,該結構描述有 2 個屬性:id- 一個人的唯一數字識別碼;name- 一個人的字串名稱。 - 定義一個具有
InteractiveRunner的管線,以利用 Apache Beam 的筆記本相關功能。
%pip install names
import names
from typing import NamedTuple
class Person(NamedTuple):
id: int
name: str
p = beam.Pipeline(InteractiveRunner())
程式碼執行沒有可見的輸出。
建立不使用 SQL 的結構描述感知 PCollection
persons = (p
| beam.Create([Person(id=x, name=names.get_full_name()) for x in range(10)]))
ib.show(persons)

persons_2 = (p
| beam.Create([Person(id=x, name=names.get_full_name()) for x in range(5, 15)]))
ib.show(persons_2)

現在您有 2 個 PCollection,它們都具有由 Person 類別定義的相同結構描述
persons包含 10 個記錄,用於 10 個 ID 範圍從 0 到 9 的人,persons_2包含另外 10 個記錄,用於 10 個 ID 範圍從 5 到 14 的人。
結構描述感知 PCollection 的編碼和解碼
對於此範例,您仍然需要從您在這篇文章中透過說明建立的第一個 pcoll 中取得另一筆資料。
您可以使用原始的 pcoll。或者,如果您想練習使用具有 schema 感知的 PCollection 來顯式使用編碼器,您可以加入 Text I/O:將 pcoll 的內容寫入文字檔,同時保留其 schema 資訊,然後將檔案讀回名為 pcoll_in_file 的新 schema 感知 PCollection,並使用新的 PCollection 連接 persons 和 persons_2,以找到在所有三個集合中都具有相同 id 的名稱。
若要將 pcoll 編碼到檔案中,請執行
coder=beam.coders.registry.get_coder(pcoll.element_type)
pcoll | beam.io.textio.WriteToText('/tmp/pcoll', coder=coder)
pcoll.pipeline.run().wait_until_finish()
!cat /tmp/pcoll*

上面的程式碼執行會使用 Beam 指派的編碼器,將 PCollection pcoll (基本上是 {id: 1, str: foo, flt: 3.14}) 寫入文字檔。如您所見,檔案內容以二進位非人類可讀的格式記錄,這是正常的。
若要將檔案內容解碼為新的 PCollection,請執行
pcoll_in_file = p | beam.io.ReadFromText(
'/tmp/pcoll*', coder=coder).with_output_types(
pcoll.element_type)
ib.show(pcoll_in_file)

請注意,您在編碼和解碼期間必須使用相同的編碼器,而且您也可以透過 with_output_types() 將 schema 明確地指派給新的 PCollection。
從文字檔讀取編碼的二進位內容,並使用正確的編碼器進行解碼後,pcoll 的內容會還原到 pcoll_in_file 中。您可以使用此技術,透過任何 Beam I/O (不一定是文字檔) 與在自己的 pipeline 上工作的協作者分享和儲存您的資料 (不僅限於您的筆記本工作階段或 pipeline)。
beam_sql magic 中的 Schema
beam_sql magic 會自動為您的 NamedTuple schema 註冊 RowCoder,因此您只需專注於準備用於查詢的資料,而無需擔心編碼器。若要查看 beam_sql magic 在幕後執行的更詳細資訊,您可以使用 -v 選項。
例如,您可以使用以下查詢在 persons 中尋找所有 id < 5 的元素,並將輸出指派給 persons_id_lt_5。
%%beam_sql -o persons_id_lt_5 -v
SELECT * FROM persons WHERE id < 5
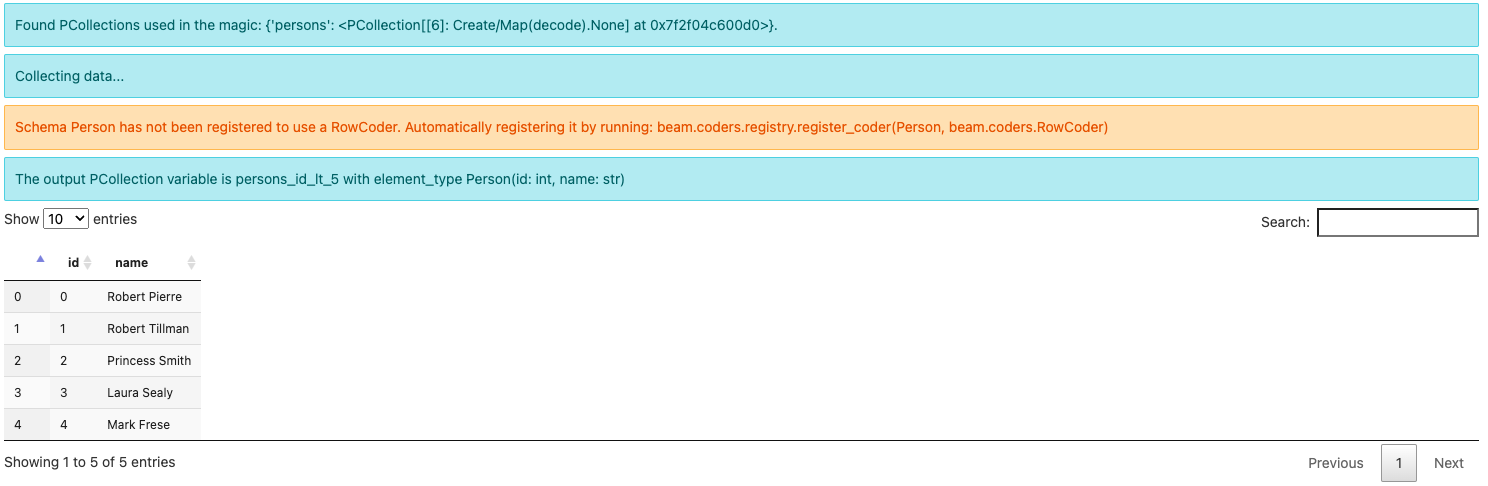
由於這是第一次執行此查詢,您可能會看到有關以下內容的警告訊息
Schema Person 尚未註冊以使用 RowCoder。透過執行以下程式碼自動註冊:beam.coders.registry.register_coder(Person, beam.coders.RowCoder)
beam_sql magic 會協助為您定義和使用的每個 schema 註冊 RowCoder (只要找到)。您也可以明確地執行相同的程式碼來執行此操作。
請注意,輸出元素類型是 Person(id: int, name: str),而不是 BeamSchema_…,因為您已從已知類型 Person(id: int, name: str) 的單個 PCollection 中選取了所有欄位。
另一個範例,您可以查詢 persons 和 persons_2 中具有相同 id 的所有名稱,並將輸出指派給 persons_with_common_id
%%beam_sql -o persons_with_common_id -v
SELECT * FROM persons JOIN persons_2 USING (id)
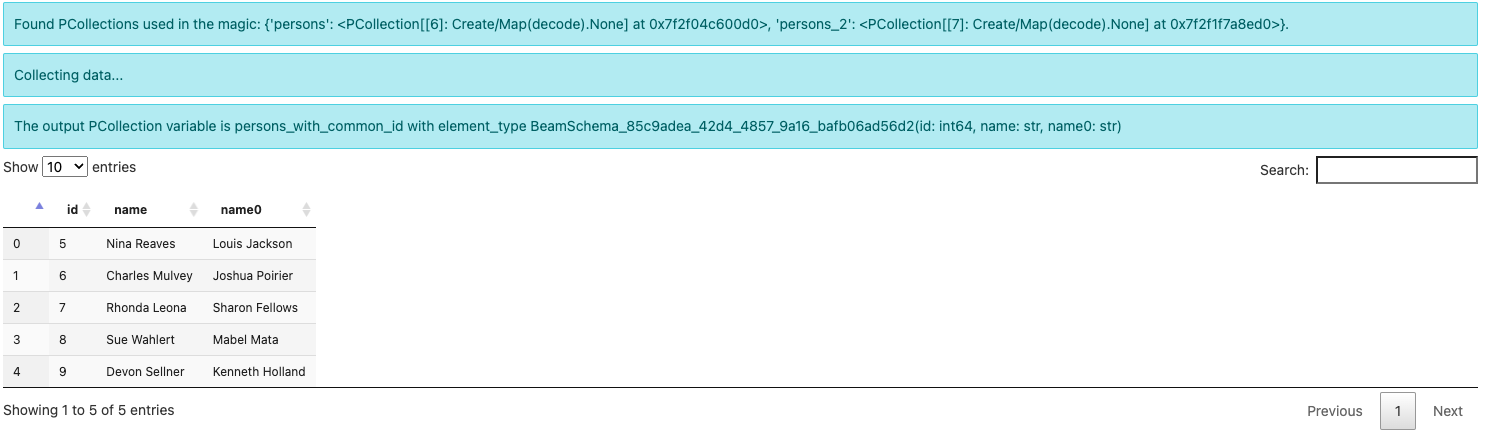
請注意,輸出元素類型現在是某個 BeamSchema_...(id: int64, name: str, name0: str)。因為您已從兩個 PCollection 中選取了欄位,所以沒有已知的 schema 可以容納結果。Beam 會自動建立 schema 並透過在其中一個欄位名稱後加上 0 來區分衝突的欄位 name。
而且由於 Person 先前已註冊了 RowCoder,即使使用 -v 選項,也不會再出現關於註冊的警告。
此外,您可以使用 pcoll_in_file、persons 和 persons_2 執行 join 操作
%%beam_sql -o entry_with_common_id
SELECT pcoll_in_file.id, persons.name AS name_1, persons_2.name AS name_2
FROM pcoll_in_file JOIN persons ON pcoll_in_file.id = persons.id
JOIN persons_2 ON pcoll_in_file.id = persons_2.id

產生的 schema 反映了您在 SQL 中完成的欄位重新命名。
範例
您將透過一個範例來找出在特定日期,美國哪個州的 COVID 確診病例最多,該資料由 covid tracking project 提供。
取得資料
import json
import requests
# The covidtracking project has stopped collecting new data, current data ends on 2021-03-07
json_current='https://api.covidtracking.com/v1/states/current.json'
def get_json_data(url):
with requests.Session() as session:
data = json.loads(session.get(url).text)
return data
current_data = get_json_data(json_current)
current_data[0]

資料的日期為 2021-03-07。其中包含有關美國不同州 COVID 病例的許多詳細資訊。current_data[0] 只是其中一個資料點。
您可以去除資料的大部分欄位。例如,只關注「date」、「state」、「positive」和「negative」,然後定義 schema UsCovidData
from typing import Optional
class UsCovidData(NamedTuple):
partition_date: str # Remember to str(e['date']).
state: str
positive: int
negative: Optional[int]
請注意:
date是 (Calcite)SQL 中的關鍵字,請使用不同的欄位名稱,例如partition_date;- 資料中的
date是int類型,而不是str。請確保使用str()轉換資料,或使用date: int。 negative有遺失的值,預設值為None。因此,它應該是negative: Optional[int],而不是negative: int。或者,您也可以在使用 schema 時將None轉換為 0。
然後將 json 資料剖析為具有 schema 的 PCollection
p_sql = beam.Pipeline(runner=InteractiveRunner())
covid_data = (p_sql
| 'Create PCollection from json' >> beam.Create(current_data)
| 'Parse' >> beam.Map(
lambda e: UsCovidData(
partition_date=str(e['date']),
state=e['state'],
positive=e['positive'],
negative=e['negative'])).with_output_types(UsCovidData))
ib.show(covid_data)

查詢
您現在可以找到「當天」(2021-03-07) 的最大確診數。
%%beam_sql -o max_positive
SELECT partition_date, MAX(positive) AS positive
FROM covid_data
GROUP BY partition_date

但是,這只是確診數字。您無法觀察到哪個州具有此最大數字,也無法觀察到該州的陰性病例數。
若要豐富您的結果,您必須將此資料連接回您已剖析的原始資料集。
%%beam_sql -o entry_with_max_positive
SELECT covid_data.partition_date, covid_data.state, covid_data.positive, {fn IFNULL(covid_data.negative, 0)} AS negative
FROM covid_data JOIN max_positive
USING (partition_date, positive)

現在,您可以看到 2021-03-07 具有最大確診病例的所有資料欄位。請注意:若要處理原始資料中 negative 欄位的遺失值,您可以使用 {fn IFNULL(covid_data.negative, 0)} 將 null 值設為 0。
當您準備好擴展時,您可以使用 SqlTransform 將 SQL 轉換為 pipeline,並在分散式執行器 (如 Flink 或 Spark) 上執行您的 pipeline。此文章透過在筆記本中藉助 beam_sql magic 在 Dataflow 上啟動一次性工作來示範它。
在 Dataflow 上執行
現在您有一個 pipeline,可剖析 json 中的美國 COVID 資料,以尋找每天確診病例最多的州的確診/陰性/州資訊,您可以嘗試將其套用至所有歷史每日資料,並在 Dataflow 上執行。
您將使用的新資料來源是來自 USAFacts 美國冠狀病毒資料庫的公開資料集,其中包含美國 COVID 病例的所有歷史每日摘要。
資料的 schema 與 covid tracking project 網站提供的資料非常相似。您將查詢的欄位是:date、state、confirmed_cases 和 deaths。
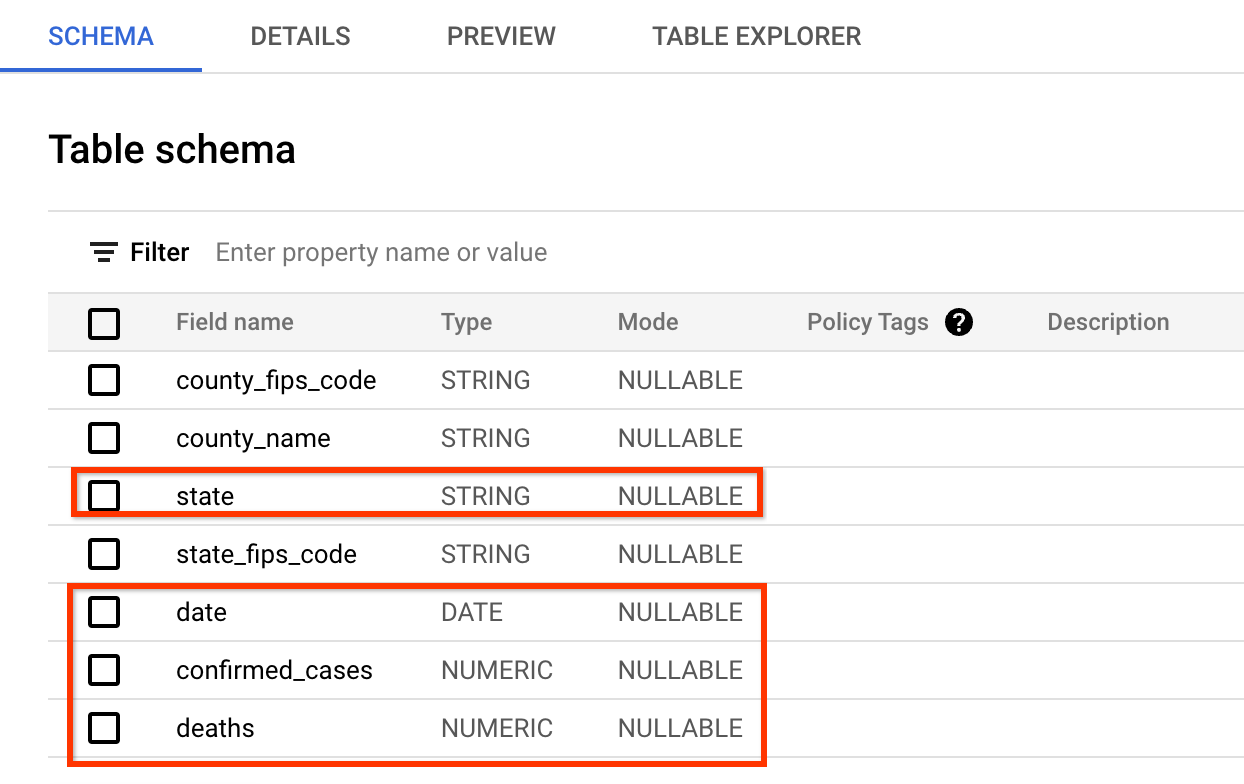
資料的預覽如下所示 (您可以跳過 BigQuery 中的檢查,直接查看螢幕擷取畫面)
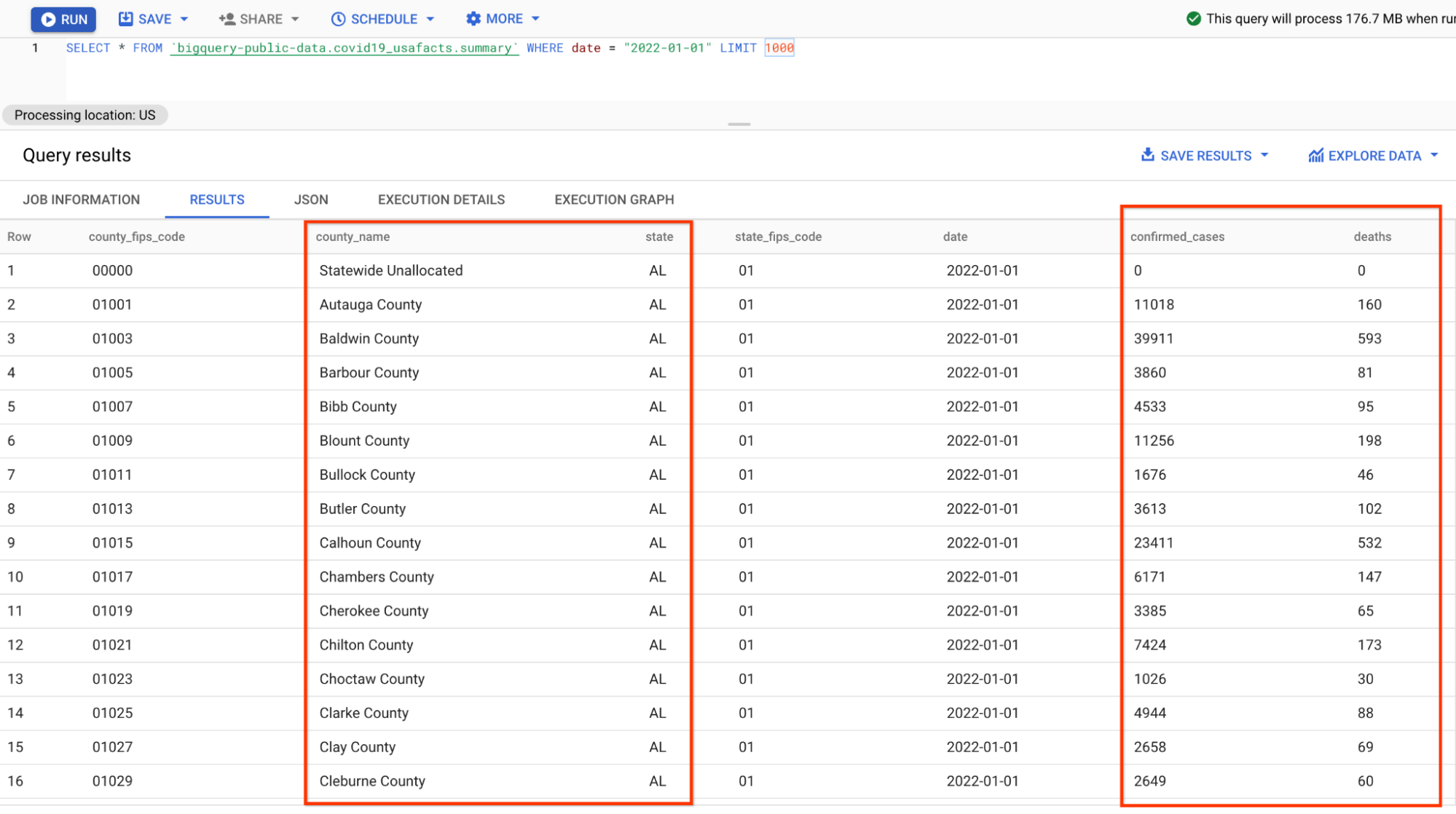
資料的格式與您在先前 pipeline 中剖析的 json 資料略有不同,因為數字是按縣而不是州分組,因此需要在 SQL 中完成一些額外的匯總。
如果您需要全新的執行,可以按一下頂部功能表上的「重新啟動核心」按鈕。
完整程式碼如下,在原始 pipeline 和查詢之上
- 它將來源從單日資料變更為更完整的歷史資料;
- 它會變更 I/O 和 schema 以適應新的資料集;
- 它會變更 SQL 以包含更多匯總,以適應資料集的新格式。
使用 schema 準備資料
from typing import NamedTuple
from typing import Optional
# Public BQ dataset.
table = 'bigquery-public-data:covid19_usafacts.summary'
# Replace with your project.
project = 'YOUR-PROJECT-NAME-HERE'
# Replace with your GCS bucket.
gcs_location = 'gs://YOUR_GCS_BUCKET_HERE'
class UsCovidData(NamedTuple):
partition_date: str
state: str
confirmed_cases: Optional[int]
deaths: Optional[int]
p_on_dataflow = beam.Pipeline(runner=InteractiveRunner())
covid_data = (p_on_dataflow
| 'Read dataset' >> beam.io.ReadFromBigQuery(
project=project, table=table, gcs_location=gcs_location)
| 'Parse' >> beam.Map(
lambda e: UsCovidData(
partition_date=str(e['date']),
state=e['state'],
confirmed_cases=int(e['confirmed_cases']),
deaths=int(e['deaths']))).with_output_types(UsCovidData))
在 Dataflow 上執行
在 Dataflow 上執行 SQL 非常簡單,您只需要新增選項 -r DataflowRunner。
%%beam_sql -o data_by_state -r DataflowRunner
SELECT partition_date, state, SUM(confirmed_cases) as confirmed_cases, SUM(deaths) as deaths
FROM covid_data
GROUP BY partition_date, state
與先前的 beam_sql magic 執行不同,您不會立即看到結果。相反地,像下面這樣的表單會列印在筆記本儲存格的輸出中

beam_sql magic 會盡力猜測您的專案 ID 和偏好的雲端區域。您仍然必須輸入提交 Dataflow 工作所需的其他資訊,例如用於暫存 Dataflow 工作的 GCS 儲存貯體,以及該工作需要的任何其他 Python 相依性。
目前,請忽略儲存格輸出中的表單,因為您仍然需要另外 2 個 SQL:1) 尋找每天的最大確診病例;2) 將最大病例資料與完整資料 data_by_state 連接。beam_sql magic 允許您連結 SQL,因此請透過執行以下程式碼再連結 2 個 SQL
%%beam_sql -o max_cases -r DataflowRunner
SELECT partition_date, MAX(confirmed_cases) as confirmed_cases
FROM data_by_state
GROUP BY partition_date
以及
%%beam_sql -o data_with_max_cases -r DataflowRunner
SELECT data_by_state.partition_date, data_by_state.state, data_by_state.confirmed_cases, data_by_state.deaths
FROM data_by_state JOIN max_cases
USING (partition_date, confirmed_cases)
預設情況下,在 Dataflow 上執行 beam_sql 時,輸出 PCollection 會寫入 GCS 上的文字檔。beam_sql 會自動提供「寫入」功能,主要用於您檢查此一次性 Dataflow 工作的輸出資料。它很輕量,不會為了進一步開發而編碼元素。若要儲存輸出並與他人分享,您可以在組合中新增更多 Beam I/O。
例如,您可以使用上述 schema 感知 PCollection 範例中描述的技術,將元素適當地編碼到文字檔中。
from apache_beam.options.pipeline_options import GoogleCloudOptions
coder = beam.coders.registry.get_coder(data_with_max_cases.element_type)
max_data_file = gcs_location + '/encoded_max_data'
data_with_max_cases | beam.io.textio.WriteToText(max_data_file, coder=coder)
此外,您可以在自己的專案中建立新的 BQ 資料集,以儲存處理過的資料。

您必須選取與您正在讀取的公開 BigQuery 資料相同之資料位置。在此範例中為「美國 (美國多個地區)」。
建立空的資料集後,您可以執行以下程式碼
output_table=f'{project}:covid_data.max_analysis'
bq_schema = {
'fields': [
{'name': 'partition_date', 'type': 'STRING'},
{'name': 'state', 'type': 'STRING'},
{'name': 'confirmed_cases', 'type': 'INTEGER'},
{'name': 'deaths', 'type': 'INTEGER'}]}
(data_with_max_cases
| 'To json-like' >> beam.Map(lambda x: {
'partition_date': x.partition_date,
'state': x.state,
'confirmed_cases': x.confirmed_cases,
'deaths': x.deaths})
| beam.io.WriteToBigQuery(
table=output_table,
schema=bq_schema,
method='STREAMING_INSERTS',
custom_gcs_temp_location=gcs_location))
現在回到最後一個 SQL 儲存格輸出的表單中,您可能會填寫在 Dataflow 上執行 pipeline 所需的資訊。範例輸入如下所示
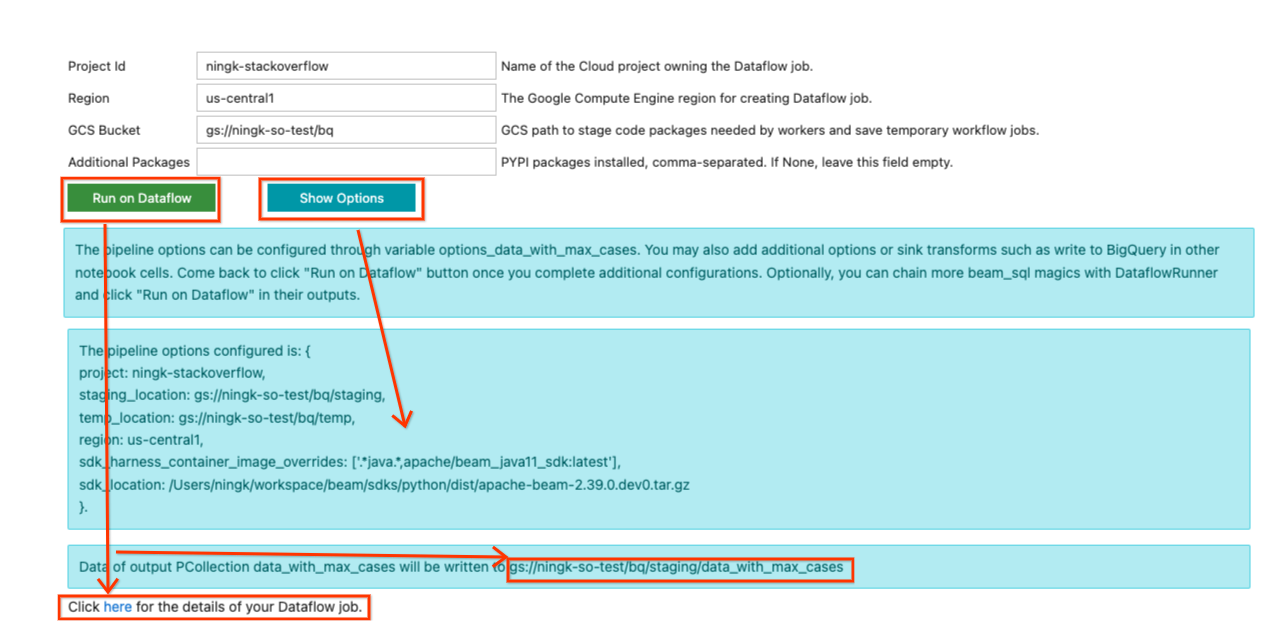
由於此 pipeline 未使用任何其他 Python 相依性,因此「其他套件」保持空白。在先前安裝名為 names 套件的範例中,若要在 Dataflow 上執行該 pipeline,您必須在此欄位中放入 names。
完成更新輸入後,您可以按一下「顯示選項」按鈕,以檢視已根據您的輸入設定的 pipeline 選項。會產生一個變數 options_[YOUR_OUTPUT_PCOLL_NAME],如果表單不足以供您執行,您可以向其提供更多 pipeline 選項。
當您準備好提交 Dataflow 工作時,請按一下「在 Dataflow 上執行」按鈕。它會告訴您預設輸出將寫入的位置,過一段時間後,會顯示一行
按一下此處以取得您的 Dataflow 工作詳細資料。
您可以按一下超連結前往您的 Dataflow 工作頁面。(或者,您可以忽略表單並繼續開發以擴展您的 pipeline。當您對您的 pipeline 狀態感到滿意時,可以回到表單並將工作提交至 Dataflow。)
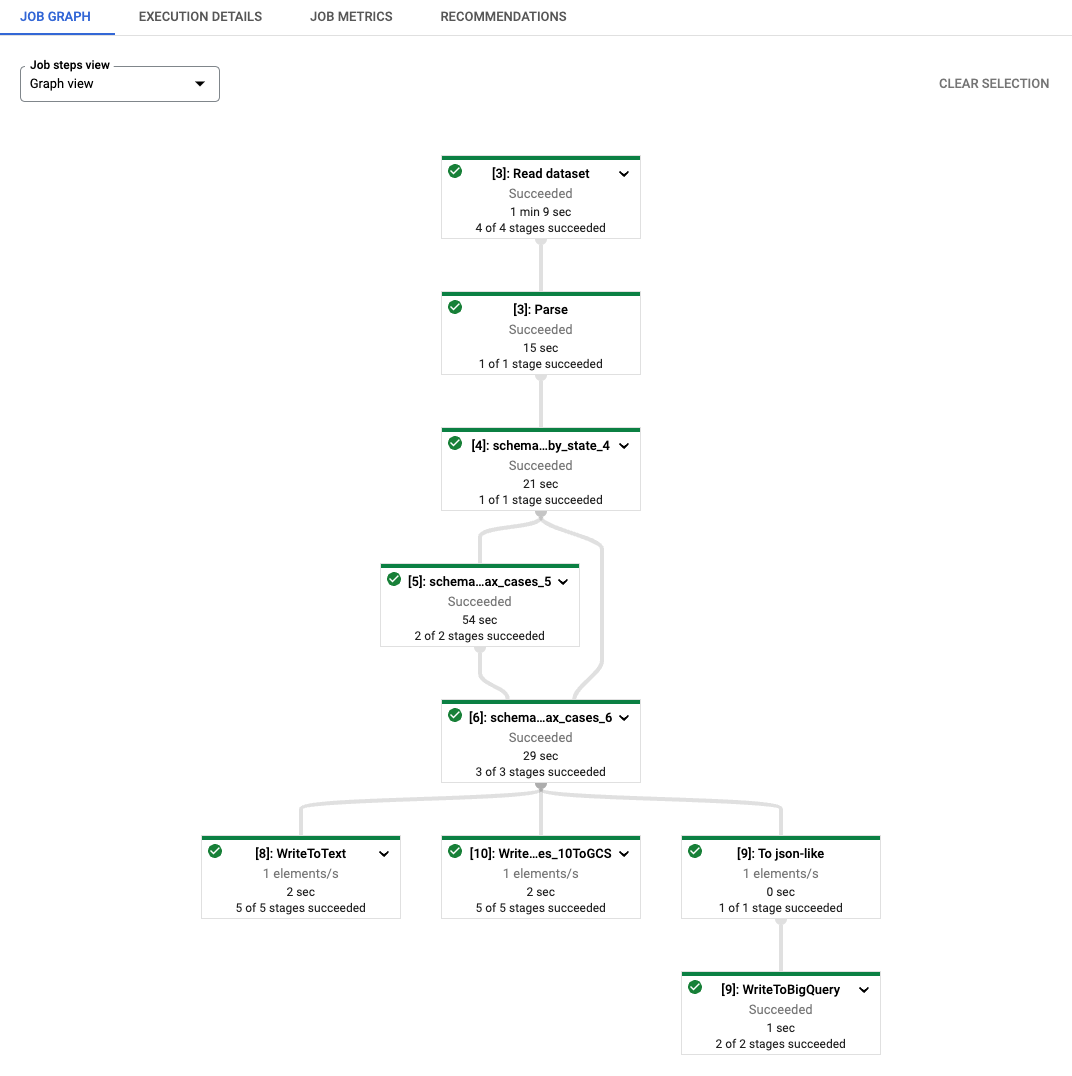
如您所見,產生的 Dataflow 工作的每個轉換名稱都會加上字串 [number]: 作為前置詞。這是為了區分筆記本中重新執行的程式碼,因為 Beam 要求每個轉換都有不同的名稱。在幕後,beam_sql magic 也會將您的 schema 資訊暫存至 Dataflow,因此您可能會看到名為 schema_loaded_beam_sql_… 的轉換。這是因為筆記本中定義的 NamedTuple 可能在 __main__ 範圍中,而 Dataflow 完全不知道它們。為了盡量減少使用者介入,並避免 pickle 整個主要工作階段 (而且當主要工作階段包含無法 pickle 的屬性時,pickle 主要工作階段是不可行的),beam_sql magic 會透過序列化您的 schema、將其暫存至 Dataflow,然後將其反序列化/載入以執行工作,來最佳化暫存程序。
工作成功完成後,輸出 PCollection 的結果會寫入您的 I/O 轉換指示的位置。請注意:在 Dataflow 上執行 beam_sql 會產生一次性工作,它不是互動式的。
從預設輸出位置簡單檢查資料
!gsutil cat 'gs://ningk-so-test/bq/staging/data_with_max_cases*'

由您的 WriteToText 寫入的具有編碼二進位資料的文字檔
!gsutil cat 'gs://ningk-so-test/bq/encoded_max_data*'

由您的 WriteToBigQuery 建立的表格 YOUR-PROJECT:covid_data.max_analysis

使用 beam_sql magic 直接在其他 OSS 執行器上執行
在發布此網誌文章的當天,beam_sql magic 僅支援 DirectRunner (互動式) 和 DataflowRunner (一次性)。它是 SqlTransform 之上的簡單包裝函式,具有由 ipywidgets 實作的互動式輸入小工具。您可以依照 說明實作您自己的執行器支援或公用程式。
此外,對其他 OSS 執行器的支援正在進行中,例如,支援搭配 beam_sql magic 使用 FlinkRunner。
結論
beam_sql magic 和 Apache Beam Notebooks 結合是一個方便的工具,可讓您學習 Beam SQL,並將 Beam SQL 與原型設計和生產化 (例如,到 Dataflow) 您的 Beam pipeline 結合,並以最少的設定。
有關 Beam SQL 語法的更多詳細資訊,請查看 Beam Calcite SQL 相容性和 Apache Calcite SQL 語法。