



部落格
2022/04/22
使用 Google Cloud Dataflow 執行 Apache Hop 可視化管線
簡介
Apache Hop (https://hop.apache.org/) 是一個視覺化開發環境,用於使用 Apache Beam 建立資料管線。您可以在 Spark、Flink 或 Google Cloud Dataflow 中執行您的 Hop 管線。
在這篇文章中,我們將了解如何安裝 Hop,並在雲端使用 Dataflow 執行範例管線。要遵循這篇文章中給出的步驟,您應該在 Google Cloud Platform 中擁有一個專案,並且您應該擁有足夠的權限來建立 Google Cloud Storage 儲存貯體 (或使用現有的儲存貯體),以及執行 Dataflow 工作。
一旦您的 Google Cloud 專案準備就緒,您將需要安裝 Google Cloud SDK 來觸發 Dataflow 管線。
此外,別忘了設定 Google Cloud SDK 以使用您的帳戶和專案。
設定和本機執行
您可以將 Apache Hop 作為本機應用程式執行,或使用 Docker 容器中的 Hop 網頁版本。這篇文章中給出的說明適用於本機應用程式,因為如果 Hop 在容器中執行,Cloud Dataflow 的驗證方式會有所不同。其餘的說明仍然有效。Hop 的 UI 無論是作為本機應用程式還是網頁版本執行,都是完全相同的。
現在是時候下載並安裝 Apache Hop,請按照這些說明進行。
在這篇文章中,我使用了 2022 年 3 月 7 日發佈的 apache-hop-client 套件中的二進制檔,版本為 1.2.0。
安裝 Hop 後,我們就可以開始了。
Zip 檔案包含一個 config 目錄,您會在其中找到一些範例專案以及 Dataflow 和其他執行器的管線執行設定。
在這個範例中,我們將使用位於 config/projects/samples/beam/pipelines/input-process-output.hpl 中的管線。
讓我們從開啟 Apache Hop 開始。在您解壓縮用戶端的目錄中,執行
./hop/hop-gui.sh
(如果您的作業系統是 Windows,則執行 ./hop/hop-gui.bat)。
進入 Hop 後,讓我們開啟管線。
我們首先從專案 default 切換到專案 samples。在視窗左上角找到 projects 方塊,然後選取專案 samples
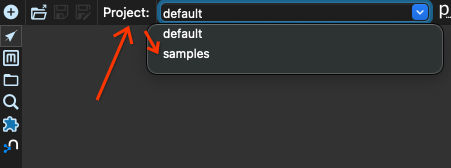
現在我們按一下開啟按鈕
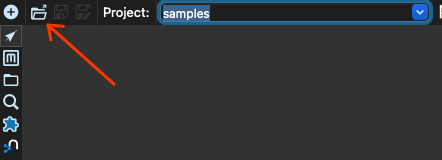
選取 beam/pipelines 子目錄中的管線 input-process-output.hpl
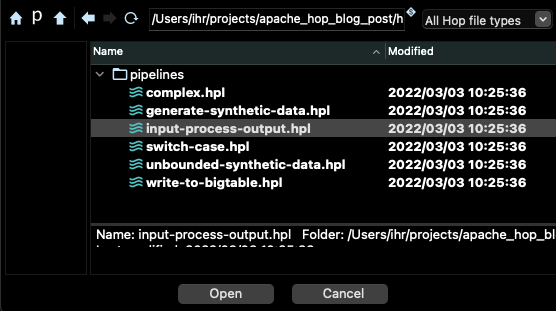
您應該會在 Hop 的主視窗中看到如下的圖形
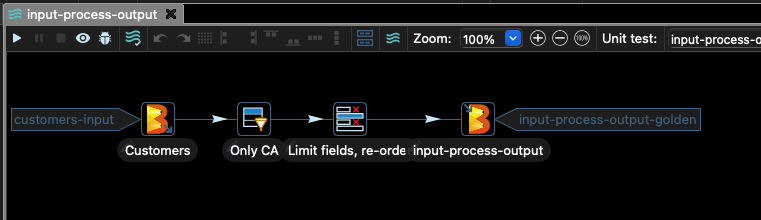
此管線從 CSV 檔案中取得一些客戶資料,並篩選掉除了 stateCode 欄位等於 CA 的記錄之外的所有內容。
然後我們僅選取檔案的某些欄位,並將結果寫入 Google Cloud Storage。
在將管線提交到 Dataflow 之前,最好先在本機測試管線。在 Apache Hop 中,您可以預覽每個轉換的輸出。讓我們看看輸入 Customers。
按一下 Customers 輸入轉換,然後按一下選取轉換後開啟的對話方塊中的「預覽輸出」
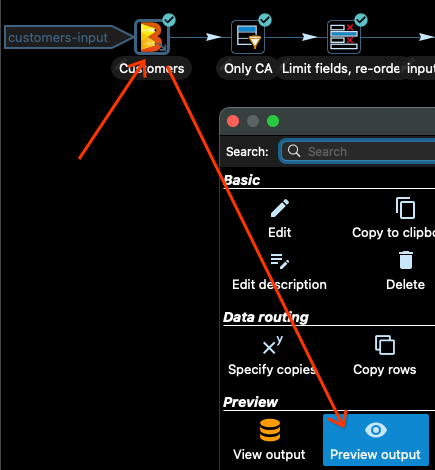
現在選取「快速啟動」選項,您將看到一些輸入資料

當您完成檢閱資料時,按一下「停止」。
如果我們在 Only CA 轉換後立即重複此程序,我們將看到所有列的 stateCode 欄位都等於 CA。
下一個轉換僅選取輸入資料的某些欄位並重新排列欄位的順序。讓我們看一下。按一下轉換,然後按一下「預覽輸出」
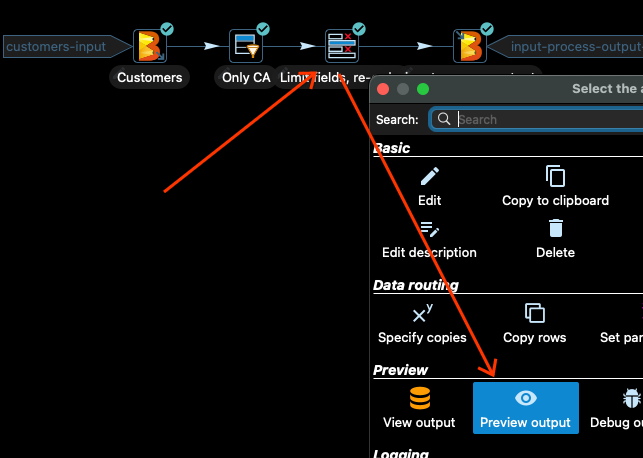
然後再次按一下「快速啟動」,您應該會看到如下的輸出
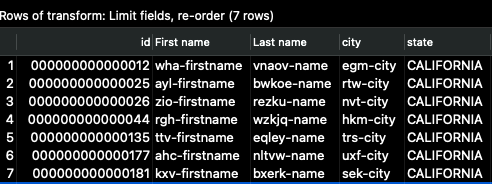
現在 id 欄位是第一個,而且我們只看到輸入欄位的子集。這是在管線完成寫入完整輸出後,資料的外觀。
使用 Beam Direct Runner
讓我們執行管線。要執行管線,我們需要指定執行器設定。這可以透過 Apache Hop 的 Metadata 工具完成
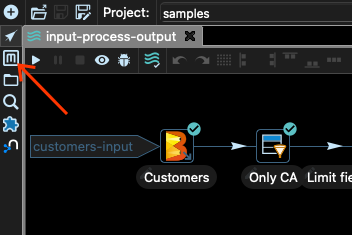
在 samples 專案中,已經建立了一些設定

local 設定是用於使用 Hop 執行管線的設定。例如,這是我們在檢查不同步驟輸出的預覽時所使用的設定。
Direct 設定使用 Apache Beam 的直接執行器。讓我們檢查一下它的外觀。管線執行設定中有兩個標籤:主要和變數。
對於直接執行器,主要標籤具有以下選項

我們可以變更工作者設定的數量以符合我們的 CPU 數量,甚至將其限制為 1,以便管線不會消耗大量資源。
在「變數」標籤中,我們找到管線本身的設定參數 (而非執行器的設定參數):\
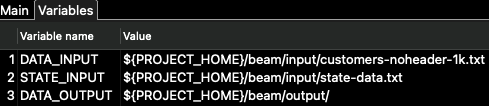
對於此管線,僅使用 DATA_INPUT 和 DATA_OUTPUT 變數。STATE_INPUT 用於不同的範例。
如果您查看管線輸入和輸出節點中的 Beam 轉換,您將看到這些變數在此處的使用方式

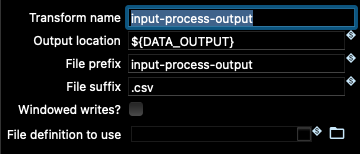
由於這些變數已正確設定為指向 samples 專案資料夾中資料的位置,讓我們嘗試使用 Beam Direct Runner 執行管線。
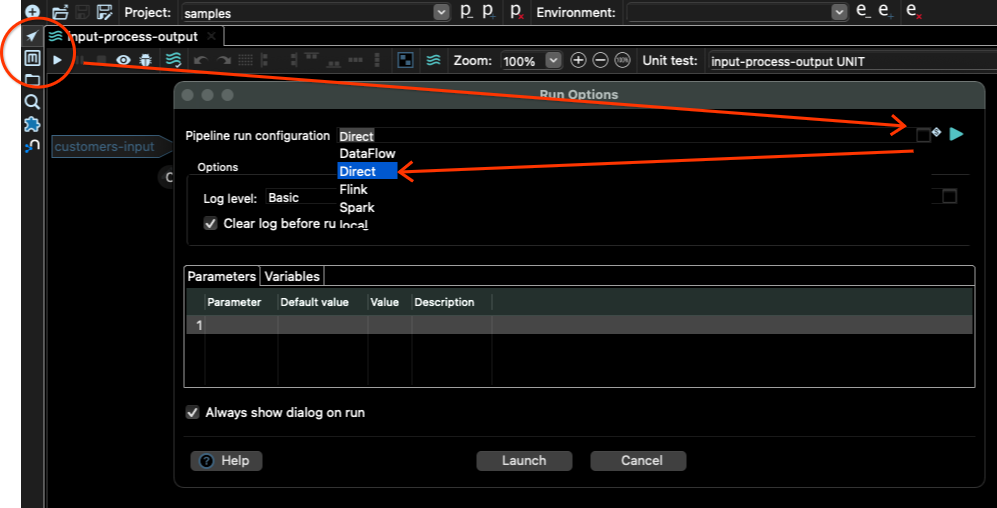
為此,我們需要回到管線檢視 (Metadata 工具正上方的箭頭按鈕),然後按一下執行按鈕 (工具列中的小型「播放」按鈕)。然後選擇 Direct 管線執行設定,並按一下「啟動」按鈕
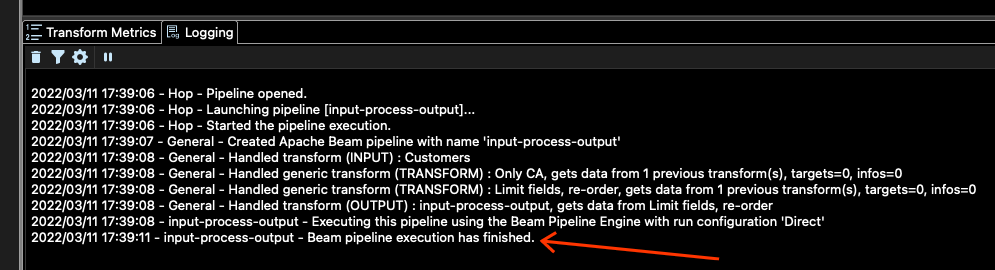
您如何知道工作是否已完成?您可以檢查主視窗底部的記錄。您應該會看到類似這樣的內容
如果我們移至 DATA_OUTPUT 設定的位置,在我們的案例中是 config/projects/samples/beam/output,我們應該會在其中看到一些輸出檔案。在我的案例中,我會看到這些檔案

檔案數量取決於您在執行設定中設定的工作者數量。
太棒了,因此管線在本機上運作。現在是在雲端中執行它的時候了!
使用 Dataflow 在雲端規模執行
讓我們看一下 Dataflow 管線執行設定。移至 Metadata 工具,然後移至「管線執行設定」,並選取 Dataflow
我們再次有「主要」和「變數」標籤。我們需要在兩者中變更一些值。我們先從「變數」開始。按一下「變數」標籤,您應該會看到以下的值

這些是屬於該範例專案作者的 Google Cloud Storage (GCS) 位置。我們需要變更它們以指向我們自己的 GCS 儲存貯體。
Google Cloud 中的專案設定
但是為此,我們必須建立儲存貯體。對於下一步,您需要確定您已設定 gcloud (Google Cloud SDK),並且您已成功驗證。
要再次確認,請執行命令 gcloud config list 並檢查帳戶和專案是否正確。如果正確,讓我們再三重檢查並執行 gcloud auth login。這應該會在您的網頁瀏覽器中開啟一個標籤,以執行驗證程序。完成此操作後,您可以使用 SDK 與您的專案互動。
在此範例中,我將使用 GCP 的歐洲西部 1 區域。讓我們在那裡建立一個區域儲存貯體。在我的案例中,我將儲存貯體名稱設為 ihr-apache-hop-blog。為您的儲存貯體選擇不同的名稱!
gsutil mb -c regional -l europe-west1 gs://ihr-apache-hop-blog
現在讓我們將範例資料上傳至 GCS 儲存貯體,以測試管線在 Dataflow 中的執行方式。移至包含所有 Hop 檔案的相同目錄 (與 hop-gui.sh 相同的目錄),然後讓我們將資料複製到 GCS
gsutil cp config/projects/samples/beam/input/customers-noheader-1k.txt gs://ihr-apache-hop-blog/data/
請注意路徑中的最後一個斜線 /,表示您想要建立一個名為 data 的目錄,其中包含所有內容。
若要確定您已正確上傳資料,請檢查該位置的內容
gsutil ls gs://ihr-apache-hop-blog/data/
您應該會在該位置看到檔案 customer-noheader-1k.txt。
在繼續之前,請確定您的專案中已啟用 Dataflow,並且您已準備好可與 Hop 搭配使用的服務帳戶。請查看 Dataflow 文件中「開始之前」一節中提供的說明,以了解如何啟用 Dataflow 的 API。
現在我們需要確定 Hop 可以使用存取 Dataflow 所需的認證。在 Hop 文件中,您會發現它建議建立服務帳戶,匯出該服務帳戶的金鑰,並設定 GOOGLE_APPLICATION_CREDENTIALS 環境變數。這也是以上連結中提供的方法。
匯出服務帳戶的金鑰具有潛在危險,因此我們將使用不同的方法,利用 Google Cloud SDK。執行以下命令
gcloud auth application-default login
這將會在您的網頁瀏覽器中開啟一個標籤,要求確認驗證。確認之後,系統中任何需要存取 Google Cloud Platform 的應用程式都將使用這些認證進行存取。
我們還需要為 Dataflow 工作建立一個具有特定權限的服務帳戶。使用以下命令建立服務帳戶
gcloud iam service-accounts create dataflow-hop-sa
現在我們授予此服務帳戶 Dataflow 的權限
gcloud projects add-iam-policy-binding ihr-hop-playground \
--member="serviceAccount:dataflow-hop-sa@ihr-hop-playground.iam.gserviceaccount.com"\
--role="roles/dataflow.worker"
我們還需要為 Google Cloud Storage 提供額外的權限。
gcloud projects add-iam-policy-binding ihr-hop-playground \
--member="serviceAccount:dataflow-hop-sa@ihr-hop-playground.iam.gserviceaccount.com"\
--role="roles/storage.admin"
請務必將專案 ID ihr-hop-playground 更改為您自己的專案 ID。
現在,讓我們授權使用者模擬該服務帳戶。為此,請前往您專案中的 Google Cloud Console 上的服務帳戶,然後點擊我們剛才建立的服務帳戶。
點擊權限標籤,然後點擊授予存取權按鈕。
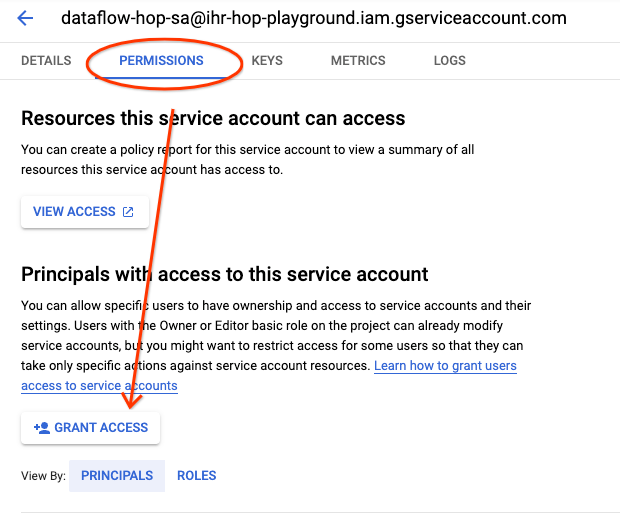
授予您的使用者服務帳戶使用者角色。
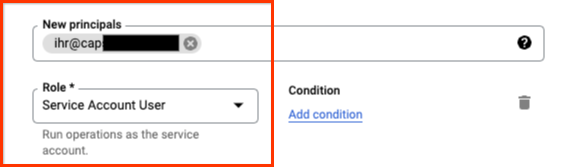
現在您已完成所有設定,可以使用該服務帳戶和您的使用者執行 Dataflow。
更新管線執行設定
在 Dataflow 中執行管線之前,我們需要為管線程式碼產生 JAR 套件。為此,您必須前往功能表列中的工具功能表,並選擇產生 Hop fat jar選項。在對話方塊中點擊「確定」,然後為 JAR 選擇位置和檔案名稱,並點擊儲存。
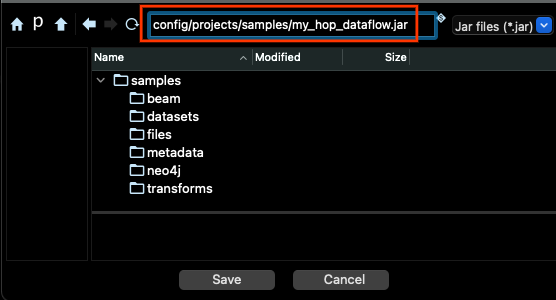
產生檔案需要幾分鐘時間。

我們準備好在 Dataflow 中執行管線了。或者說,幾乎準備好了 :)。
前往管線編輯器,點擊播放按鈕,然後選擇DataFlow作為管線執行設定,然後點擊右側的播放按鈕。
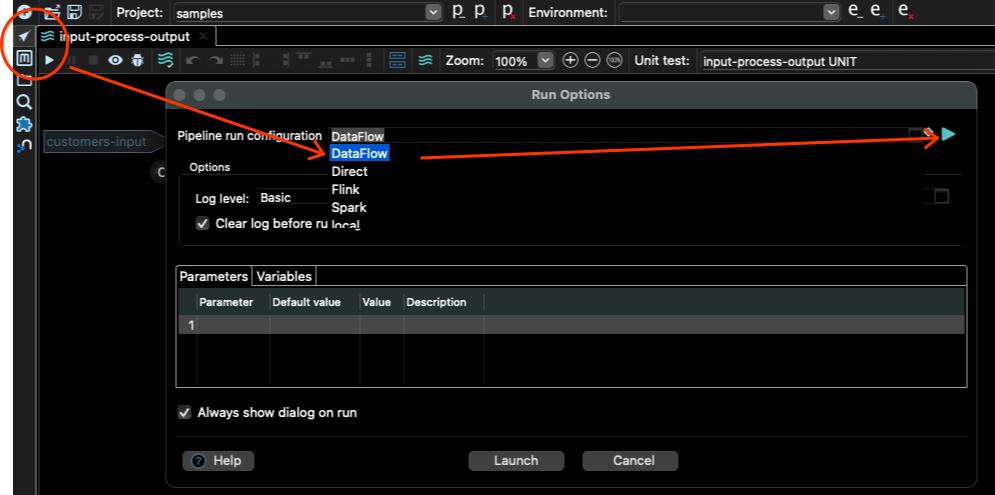
這將開啟 Dataflow 管線執行設定,您可以在其中變更輸入變數和其他 Dataflow 設定。
點擊變數標籤,並且只修改 DATA_INPUT 和 DATA_OUTPUT 變數。
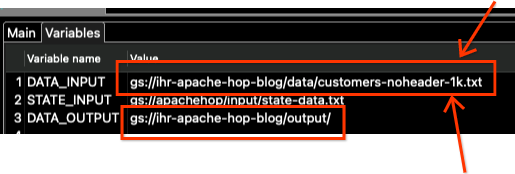
請注意,我們還需要更改檔案名稱。
現在讓我們前往主要標籤,因為我們需要在那裡變更其他一些選項。我們需要更新
- 專案 ID
- 服務帳戶
- 暫存位置
- 區域
- 臨時位置
- Fat jar 檔案位置
對於專案 ID,設定您的專案 ID(與您執行 gcloud config list 時看到的專案 ID 相同)。
對於服務帳戶,請使用我們建立的服務帳戶的位址。如果您不記得,可以在 Google Cloud Console 的服務帳戶中找到它。
對於暫存和臨時位置,請使用我們剛才建立的相同儲存空間。變更路徑中的儲存空間位址,並保留設定中已設定的相同「binaries」和「tmp」位置。
對於區域,在此範例中,我們使用 europe-west1。
此外,根據您的網路設定,您可能需要勾選「使用公用 IP?」的方塊,或者不勾選該方塊,但在您專案中 europe-west1 的區域子網路中啟用 Google 私人存取權(如需更多詳細資訊,請參閱設定私人 Google 存取權 | VPC)。在此範例中,為了簡單起見,我將勾選該方塊。
對於 fat jar 位置,請使用右側的瀏覽按鈕,然後找到我們上面產生的 JAR。總而言之,我的主要選項看起來像這樣(您的專案 ID 和位置將會不同)
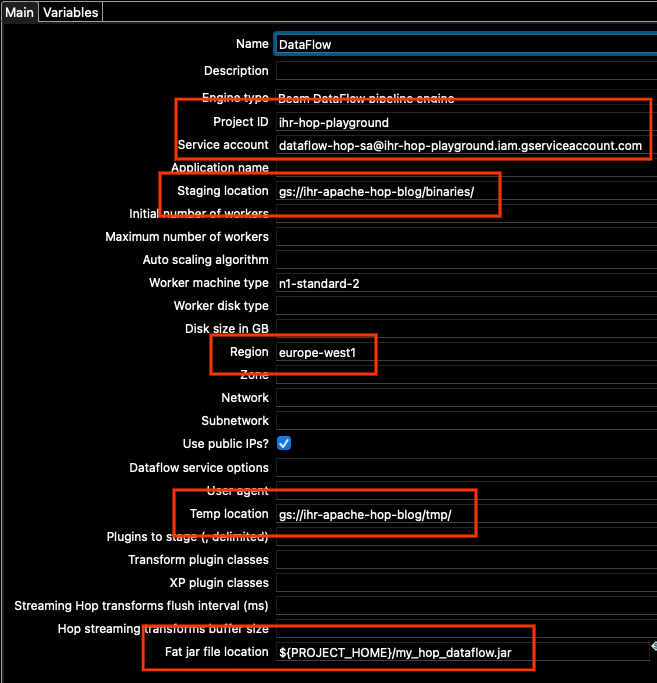
當然,您可以根據您的專案可能需要的特定設定來變更任何其他選項。
當您準備好時,請點擊確定按鈕,然後點擊啟動以觸發管線。
在記錄視窗中,您應該會看到如下所示的一行

在 Dataflow 中檢查工作
如果一切順利,您現在應該會在 https://console.cloud.google.com/dataflow/jobs 中看到正在執行的工作。
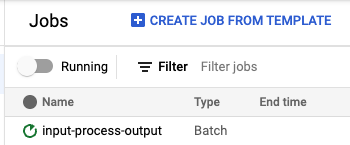
如果由於某種原因工作失敗,請開啟失敗的工作頁面,檢查底部的記錄,然後點擊錯誤圖示以找出管線失敗的原因。通常是因為我們在您的設定中設定了一些錯誤的選項。
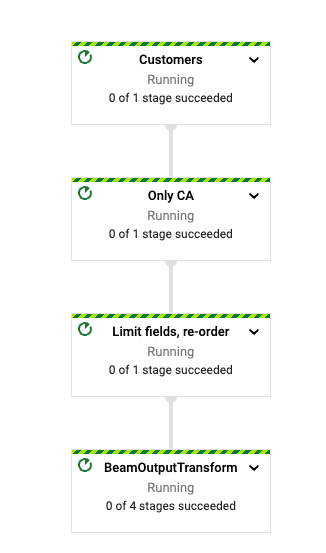
當管線開始執行時,您應該會在工作頁面中看到管線的圖表。
當工作完成時,輸出位置中應該會有一個檔案。您可以使用 gsutil 來檢查它
% gsutil ls gs://ihr-apache-hop-blog/output
gs://ihr-apache-hop-blog/output/input-process-output-00000-of-00003.csv
gs://ihr-apache-hop-blog/output/input-process-output-00001-of-00003.csv
gs://ihr-apache-hop-blog/output/input-process-output-00002-of-00003.csv
在我的情況下,工作產生了三個檔案,但實際數量會因執行而異。
讓我們探索這些檔案的前幾行
gsutil cat "gs://ihr-apache-hop-blog/output/*csv"| head
12,wha-firstname,vnaov-name,egm-city,CALIFORNIA
25,ayl-firstname,bwkoe-name,rtw-city,CALIFORNIA
26,zio-firstname,rezku-name,nvt-city,CALIFORNIA
44,rgh-firstname,wzkjq-name,hkm-city,CALIFORNIA
135,ttv-firstname,eqley-name,trs-city,CALIFORNIA
177,ahc-firstname,nltvw-name,uxf-city,CALIFORNIA
181,kxv-firstname,bxerk-name,sek-city,CALIFORNIA
272,wpy-firstname,qxjcn-name,rew-city,CALIFORNIA
304,skq-firstname,cqapx-name,akw-city,CALIFORNIA
308,sfu-firstname,ibfdt-name,kqf-city,CALIFORNIA
我們可以看到所有列的州都是加州,輸出只包含我們選擇的欄,而使用者 ID 是第一欄。您獲得的實際輸出可能會有所不同,因為資料處理的順序在每次執行中都不會相同。
我們已使用小型的資料樣本執行此工作,但我們可以使用任意大的輸入 CSV 執行相同的工作。Dataflow 會將資料平行化並以區塊處理。
結論
Apache Hop 是 Beam 管線的視覺開發環境,可讓我們在本機執行管線、檢查資料、偵錯、單元測試以及許多其他功能。一旦我們對在本機執行的管線感到滿意,我們只需設定使用 Dataflow 的必要參數,即可在雲端部署相同的視覺管線。
如果您想進一步了解 Apache Hop,請不要錯過 Hop 作者在 Beam Summit 上發表的演講,並且別忘了查看入門指南。