



部落格
2024/02/05
幕後花絮:在高流量串流環境中打造 Apache Beam 的自動調整器
我們為 Apache Beam 工作設計的自動調整器簡介
歡迎來到我們關於使用 Beam 和 Flink 建立可擴展、自我管理串流基礎架構的部落格系列的第三篇也是最後一篇。在我們之前的文章中,我們深入探討了我們串流平台的規模,強調了我們管理超過 40,000 個串流工作並每秒處理超過 1000 萬個事件的能力。這種令人印象深刻的規模為我們今天解決的挑戰奠定了基礎:動態串流環境中複雜的資源分配任務。
在這篇部落格文章中,Talat Uyarer (架構師 / 高級首席工程師) 和 Rishabh Kedia (首席工程師) 詳細描述了我們的自動調整器。想像一下,您的串流系統被不斷變動的工作負載淹沒。我們的情況提出了一個獨特的挑戰,因為我們的客戶配備了在全球分佈的防火牆,會在一天中的不同時間產生日誌。這導致工作負載不僅隨時間變化,而且還會隨著設定的更改或新增 PANW 的新型網路安全解決方案而隨著時間的推移而升級。此外,對我們程式碼庫的更新需要跨所有串流工作推出變更,從而在系統處理未處理的資料時導致臨時需求激增。
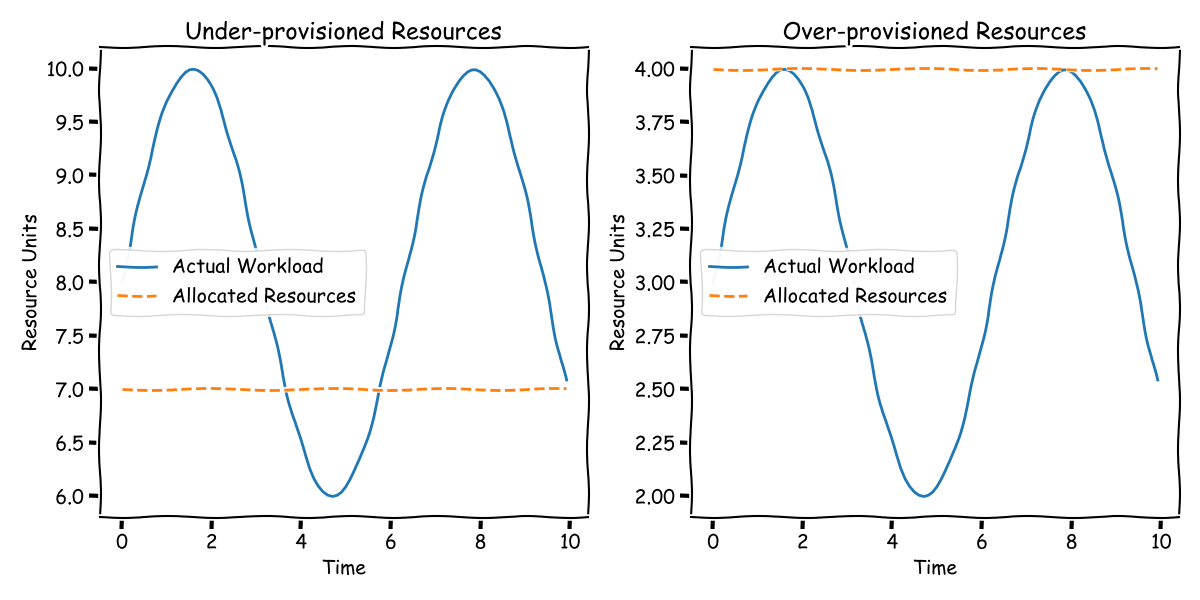
傳統上,管理這種需求的潮起潮落涉及手動且通常效率低下的方法。人們可能會過度配置資源來處理尖峰負載,這不可避免地導致在離峰時間浪費資源。相反,更注重成本的策略可能涉及接受尖峰時段的延遲,並預期稍後趕上。然而,這兩種方法都需要不斷的監控和手動調整 - 這絕非理想的情況。
在這個網路前端自動擴展已成定局的現代,我們渴望將相同程度的效率和自動化帶入串流基礎架構。我們的目標是開發一個可以動態追蹤並調整我們串流操作工作負載需求的系統。在這篇部落格文章中,我們將向您介紹我們的創新解決方案 - 專為 Apache Beam 工作設計的自動調整器。
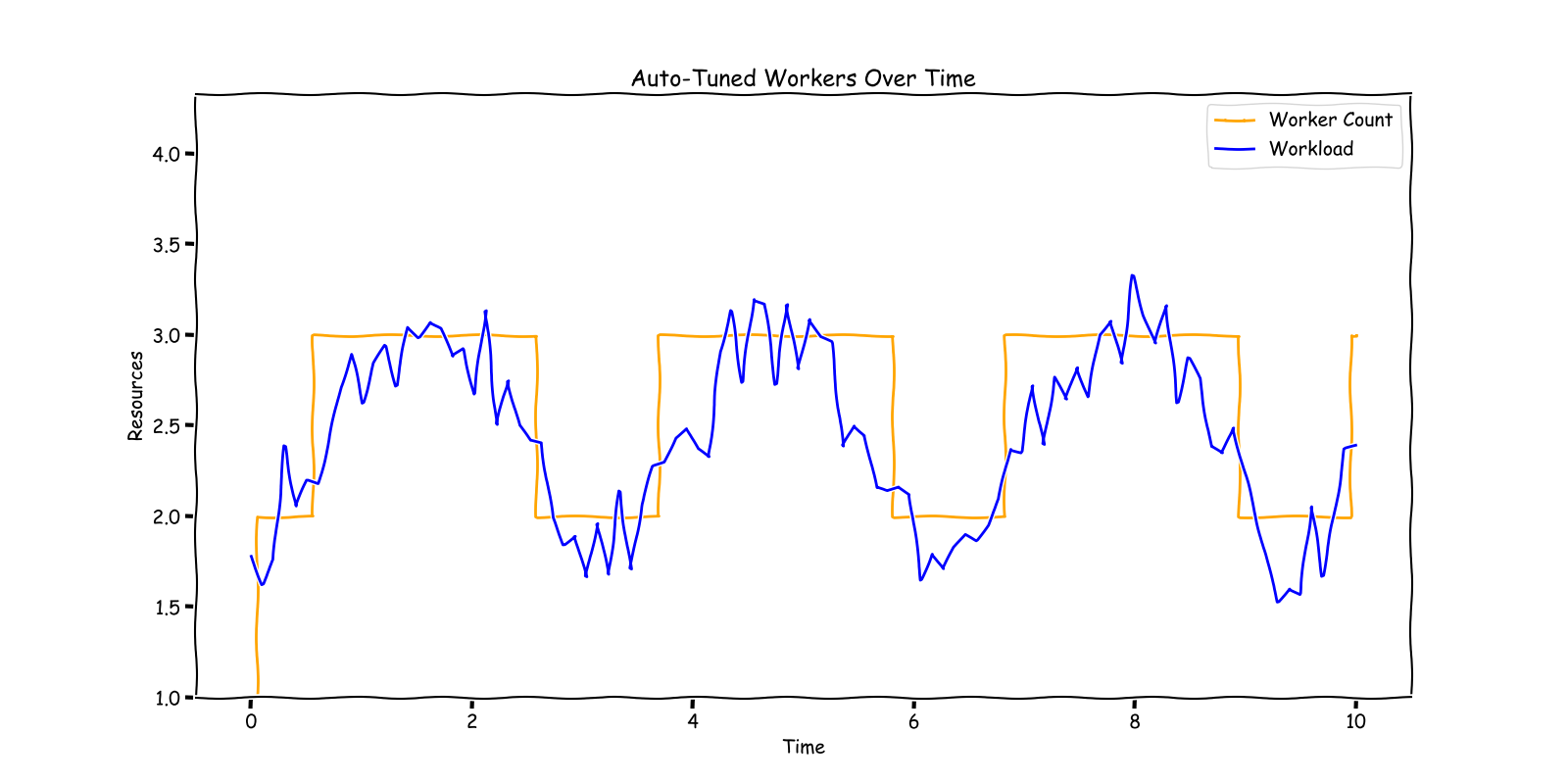
為了清楚起見,當我們在此處提及「資源」時,我們指的是處理您的串流管線的 Flink 任務管理員或 Kubernetes Pod 的數量。這些任務管理員不僅僅涉及 CPU;它們還涉及 RAM、網路、磁碟 I/O 和其他計算資源。
但是,我們的解決方案是以某些假設為前提的。首先,它適用於處理大量資料的操作。如果您的工作負載只需要幾個任務管理員,那麼此系統可能不是最適合的。在我們的情況下,我們有 10K+ 的工作負載,而且每個工作負載都有不同的負載。手動調整對我們來說不是一個選項。我們還假設資料是均勻分佈的,允許通過新增更多任務管理員來提高輸送量。這種假設對於有效的水平擴展至關重要。雖然存在可能挑戰這些假設的現實世界的複雜性,但在本次討論的範圍內,我們將重點關注這些條件成立的情況。
加入我們,深入研究我們的自動調整器的設計和功能,該解決方案旨在為串流基礎架構的世界帶來效率、適應性和一點智慧。
識別自動調整的正確訊號
當我們監管像 Flink 上的 Apache Beam 工作這樣系統時,至關重要的是要識別關鍵訊號,這些訊號有助於我們了解工作負載和資源之間的關係。這些訊號是我們的指路明燈,向我們展示我們何時落後或浪費資源。通過準確識別這些訊號,我們可以制定有效的擴展策略並即時實施變更。想像一下,需要從 100 個任務管理員擴展到 200 個任務管理員 — 我們如何順利地進行這種轉換?這就是這些訊號發揮作用的地方。
請記住,我們的目標是為任何工作負載和管線提供通用的解決方案。雖然特定問題可能受益於獨特的訊號,但我們這裡的重點是創建一個一刀切的方法。
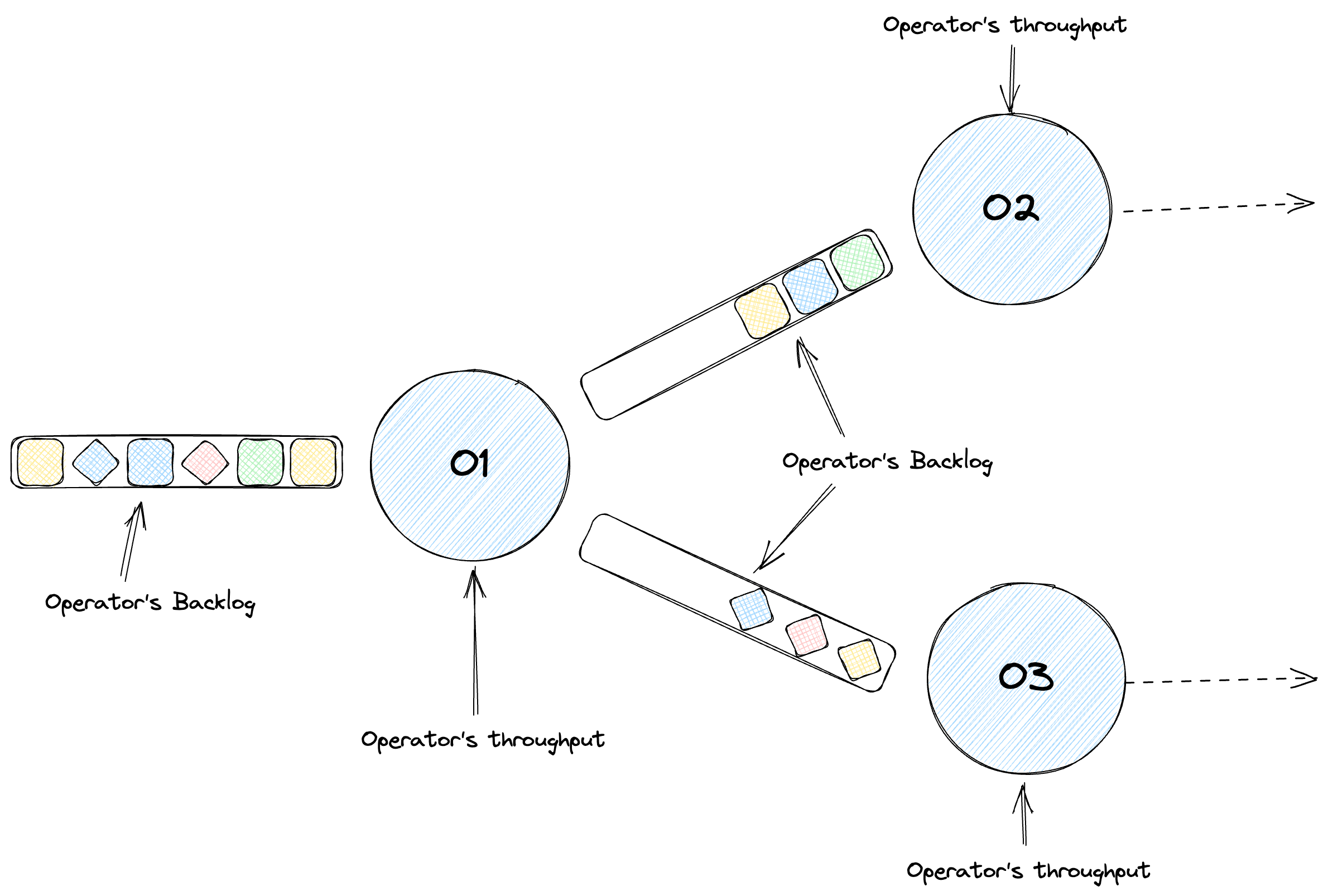
在 Flink 中,任務構成基本執行單元,並由一個或多個運算符組成,例如 map、filter 或 reduce。Flink 通過在可能的情況下將這些運算符連結到單個任務中來優化性能,從而最大限度地減少諸如線程上下文切換和網路 I/O 之類的開銷。當您的管線經過優化後,會變成一個階段的定向無環圖,每個階段都根據您的程式碼處理元素。不要將階段與實體機器混淆 — 它們是獨立的概念。在我們的工作中,我們使用 Apache Beam 的 backlog_bytes 和 backlog_elements 指標來衡量積壓資訊。
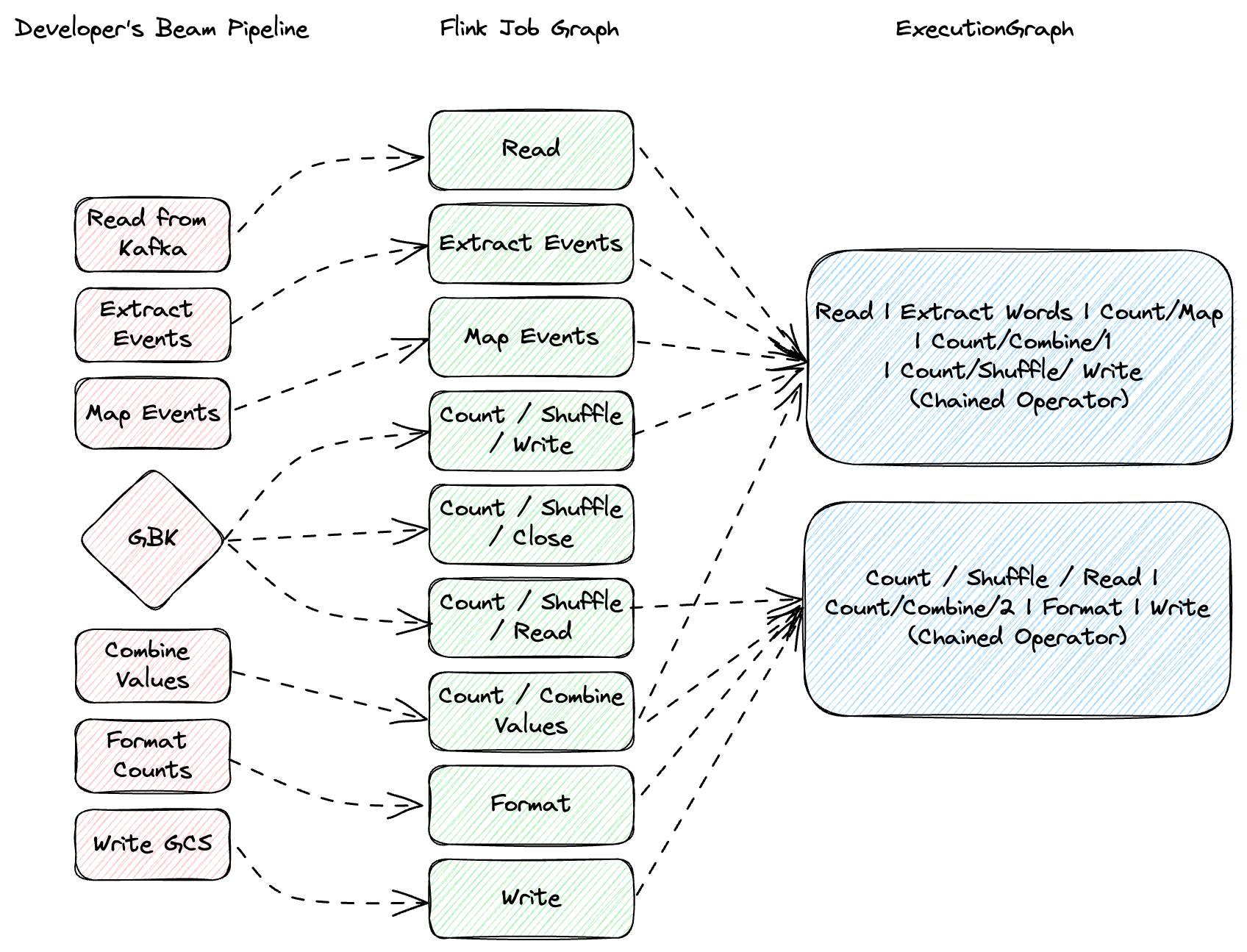
向上擴展訊號
積壓增長
讓我們舉一個實際的例子。考慮一個從 Kafka 讀取的管線,其中不同的運算符處理資料解析、格式化和累加。這裡的關鍵指標是輸送量 — 每個運算符隨時間推移處理多少資料。但是單獨的輸送量是不夠的。我們需要檢查每個運算符的佇列大小或積壓。不斷增長的積壓表示我們正在落後。我們將其衡量為積壓增長 — 隨時間推移的積壓大小的一階導數,突顯了我們的處理不足。
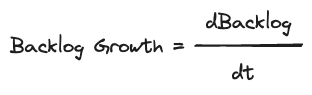
積壓時間
這將我們引向積壓時間,這是一個派生的指標,它將積壓大小與輸送量進行比較。它衡量了在假設沒有新資料到達的情況下,清除當前積壓所需的時間。這有助於我們根據我們的具體處理需求和閾值來確定特定大小的積壓是否可以接受或存在問題。
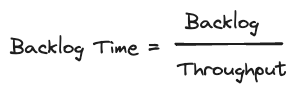
向下擴展:少即是多
CPU 使用率
向下擴展的一個關鍵訊號是 CPU 使用率。低 CPU 使用率表明我們使用的資源超出了必要範圍。通過監控這一點,我們可以有效地向下擴展而不會影響性能。
訊號摘要
總而言之,我們為有效自動調整識別的訊號是
- 輸送量:我們性能的基準。
- 積壓增長:表示我們是否跟上傳入的資料。
- 積壓時間:有助於了解積壓的嚴重程度。
- CPU 使用率:指導我們進行資源優化。
這些訊號看起來可能很簡單,但它們的簡單性是可擴展、與工作負載無關的自動調整解決方案的關鍵。
簡化 Flink 上 Apache Beam 工作的自動調整策略
在 Flink 上執行的 Apache Beam 工作中,決定何時向上或向下擴展有點像在繁忙的廚房裡當廚師。您需要留意幾種成分 — 您的工作負載、虛擬機器 (VM) 以及它們如何相互作用。這關乎維持完美的平衡。我們的主要目標是什麼?避免在處理中落後(沒有積壓增長)、確保任何現有的積壓都是可管理的(積壓時間短),並有效利用我們的資源(如 CPU)。
向上擴展:跟上進度並趕上進度
想像一下,您的系統就像一個協同工作的廚師團隊。以下是我們決定何時將更多廚師帶入廚房(又名向上擴展)的方法
跟上進度:首先,我們查看我們當前的團隊規模(VM 的數量)以及他們處理多少(輸送量)。然後,我們根據傳入訂單量(輸入速率)調整我們的團隊規模。這關乎確保我們的團隊規模足以應對當前的需求。
趕上進度:有時,我們可能會有一些訂單的積壓。在這種情況下,我們會決定我們需要多少額外的廚師才能在期望的時間內(如 60 秒)清除這些積壓。策略的這一部分有助於我們迅速回到正軌。
擴展範例:實際考察
讓我們用一個例子來描繪一幅圖。最初,我們有穩定的訂單流(輸入速率)與我們的處理能力(輸送量)相匹配,因此沒有積壓。但突然之間,訂單增加,我們的團隊開始落後,產生了積壓。我們通過增加我們的團隊規模來匹配新的訂單速率來回應。雖然積壓沒有進一步增長,但它仍然存在。最後,我們在團隊中新增了一些廚師,這使我們能夠快速清除積壓並恢復到新的平衡狀態。
向下擴展:何時減少資源
向下擴展就像知道何時可以在高峰時段後讓一些廚師休息一下。當出現以下情況時,我們會考慮這一點
- 我們的積壓很低 — 我們已經趕上了訂單。
- 積壓沒有增長 — 我們跟上了傳入的訂單。
- 我們的廚房 (CPU) 工作不太辛苦 — 我們正在有效地利用我們的資源。
向下擴展旨在減少資源而不影響服務品質。這關乎確保我們在高峯時段結束後不會人員過多。
摘要:有效擴展的配方
總而言之,我們的擴展策略是為了向上擴展,我們首先確保消耗積壓的時間超出閾值 (120 秒) 或 cpu 高於閾值 (90%)
積壓增加,又名積壓增長 > 0

持續積壓,又名積壓增長 = 0

總結

要向下擴展,我們需要確保機器利用率較低 (< 70%),並且沒有積壓增長,而且當前排空積壓的時間低於限制 (10 秒)
因此,在向下擴展後計算所需資源的唯一驅動因素是 CPU

執行自動調整決策
在我們的設定中,我們使用反應模式,該模式使用自適應排程器和宣告式資源管理器。我們希望將資源與槽對齊。正如大多數 Flink 文件中建議的那樣,我們為每個 vCPU 槽設定一個。我們的大部分工作都為任務管理員使用了 1 個 vCPU 4GB 記憶體組合。
反應模式是自適應排程器的一項獨特功能,它在每個叢集一個工作的原則下運行,這是應用程式模式中強制執行的規則。在這種模式下,一個工作被配置為利用叢集中所有可用的資源。新增任務管理員將增加工作的規模,而刪除資源將減少它的規模。在這種設定中,Flink 會自主管理工作的並行度,始終將其最大化。
在重新擴展事件期間,反應模式會使用最近的檢查點重新啟動工作。這消除了創建儲存點的需要,而這通常是手動重新擴展工作所必需的。重新擴展後重新處理的資料量受到檢查點間隔(我們的間隔為 10 秒)的影響,並且還原所需的時間取決於狀態的大小。
排程器決定工作內每個運算符的並行度。此設定是使用者不可設定的,任何設定它的嘗試,無論是針對個別運算符還是整個工作,都會被忽略。

平行處理只能透過設定管道的最大值來影響,排程器將會遵守這個設定。我們的 maxParallelism 受限於管道將處理的分割區總數,以及作業本身。我們透過 maxWorker 數量限制 TaskManager 的最大數量,並透過設定 maxParallelism 來控制 shuffle 中作業的 key 數量。此外,我們為每個管道設定 maxParallelism 來管理管道的平行處理。在 worker 數量方面,作業不能超過作業本身的 maxParallelism。
在自動調整器分析後,我們會標記作業是否需要擴大、不採取動作或縮小。為了與作業互動,我們使用一個基於 Flink Kubernetes Operator 建構的函式庫。這個函式庫讓我們可以透過簡單的 Java 方法呼叫來與 Flink 作業互動。函式庫會將我們的方法呼叫轉換為 Kubernetes 指令。
在 Kubernetes 環境中,擴大的呼叫會如下所示:
kubectl scale flinkdeployment job-name --replicas=100
Apache Flink 將處理擴大所需的其餘工作。
使用自動調整來維護有狀態串流應用程式的狀態
調整 Apache Flink 的狀態復原機制以進行自動調整,需要利用其強大的功能,例如 max parallelism、檢查點和 Adaptive Scheduler,以確保高效且具彈性的串流處理,即使系統動態調整以適應不同的負載。以下說明這些元件如何在自動調整的環境中協同運作:
- Max Parallelism 設定了作業可以擴展的最大上限,確保狀態可以在較大或較小數量的節點之間重新分配,而不會超過預先定義的界限。這對於自動調整至關重要,因為它允許 Flink 有效管理狀態,即使任務槽的數量發生變化以適應不同的工作負載。
- 檢查點是 Flink 容錯機制的中心,它會定期將每個作業的狀態儲存到持久儲存空間(在我們的案例中是 GCS 儲存桶)。在自動調整情境中,檢查點使 Flink 能夠在擴展操作後恢復到一致的狀態。當系統擴大(添加更多資源)或縮小(刪除資源)時,Flink 可以從這些檢查點還原狀態,確保資料完整性和處理連續性,而不會遺失關鍵資訊。在縮小或擴大的情況下,可能會出現從最後一個檢查點重新處理資料的時刻。為了減少該數量,我們將檢查點間隔縮短至 10 秒。
- 反應模式是 Adaptive Scheduler 的特殊模式,它假設每個叢集只有一個作業(由 Application Mode 強制執行)。反應模式會配置作業,使其始終使用叢集中所有可用的資源。添加 TaskManager 將擴大您的作業,刪除資源將縮小它。Flink 將管理作業的平行處理,始終將其設定為可能的最大值。當作業進行大小調整時,反應模式會使用最近一次成功的檢查點觸發重新啟動。
結論
在本部落格系列中,我們深入探討了在高容量串流環境中為 Apache Beam 建立自動調整器的過程,重點介紹了從概念化到實施的過程。這項努力不僅解決了動態資源分配的複雜性,還為串流基礎架構的效率和適應性設定了新標準。透過將智慧型擴展策略與 Apache Beam 和 Flink 的強大功能相結合,我們展示了一個可擴展的解決方案,該解決方案可優化資源使用並在不同的負載下維持效能。這個專案證明了團隊合作、創新以及對串流資料處理的前瞻性方法的強大力量。在我們結束本系列時,我們向所有貢獻者表示感謝,並期待這項技術的持續發展,邀請社群加入我們進行進一步的討論和開發。
參考資料
[1] Google Cloud Dataflow 中的串流自動調整 https://www.infoq.com/presentations/google-cloud-dataflow/
[2] 管道生命週期 https://cloud.google.com/dataflow/docs/pipeline-lifecycle
[3] Flink 彈性擴展 https://nightlies.apache.org/flink/flink-docs-master/docs/deployment/elastic_scaling/
感謝
這是一項巨大的努力,旨在建立新的基礎架構,並將大型客戶基礎應用程式從雲端供應商管理的串流基礎架構遷移到大規模的自我管理 Flink 基礎架構。感謝 Palo Alto Networks CDL 串流團隊協助實現這一目標:Kishore Pola、Andrew Park、Hemant Kumar、Manan Mangal、Helen Jiang、Mandy Wang、Praveen Kumar Pasupuleti、JM Teo、Rishabh Kedia、Talat Uyarer、Naitik Dani 和 David He。
探索更多
加入對話並在我們的社群中分享您的經驗,或在我們的 GitHub 上為我們正在進行的專案做出貢獻。您的意見回饋非常寶貴。如果您對本系列有任何意見或問題,請隨時透過使用者郵件列表與我們聯繫
請與我們保持聯繫,以取得更多關於 Apache Beam、Flink 和 Kubernetes 的更新和見解。