



部落格
2023/11/03
使用 Beam 和 Flink 建構可擴展的自我管理串流基礎架構
在本部落格系列中,Talat Uyarer (架構師/資深首席工程師)、Rishabh Kedia (首席工程師) 和 David He (工程總監) 描述了我們如何使用 Apache Beam 和 Flink 建構自我管理的串流平台。在本系列文章中,我們將說明為什麼以及如何透過從雲端託管串流服務遷移,建構基於 Flink 的大型自我管理串流基礎架構和服務。我們還概述了在操作擴展性、可觀察性、效能和成本效益方面的學習經驗。我們總結了我們在旅程中發現有用的技術。
使用 Flink 建構可擴展的自我管理串流基礎架構 - 第一部分
簡介
Palo Alto Networks (PANW) 是網路安全的領導者,為我們的客戶提供產品、服務和解決方案。資料是我們產品和服務的核心。我們在資料湖中串流和儲存數 EB 的資料,並進行近乎即時的擷取、資料轉換、資料插入資料儲存以及將資料轉發到我們內部基於 ML 的系統和外部 SIEM。我們在每個元件中支援多租戶,以便隔離租戶並提供最佳效能和 SLA。串流處理在管線中扮演關鍵角色。
在本系列的第二部分中,我們將更深入地描述串流基礎架構的核心建構區塊,例如自動調整器。我們還將更詳細地介紹我們的自訂項目,這使我們能夠建構高效能、大規模的串流系統。最後,我們將說明我們如何解決具有挑戰性的問題。
自我管理串流基礎架構的重要性
我們在 Google Cloud 上建構了一個大型資料平台。我們使用 Dataflow 作為託管串流服務。透過 Dataflow,我們使用串流引擎,透過 Apache Beam 和 Cloud Logging 和 Cloud Monitoring 等可觀察性工具來執行我們的應用程式。如需更多詳細資訊,請參閱 [1]。該系統每秒可處理 1500 萬個事件,每天可處理 1 兆個事件,每天的資料量為 4 PB。我們運行約 30,000 個 Dataflow 作業。每個作業可以有一到數百個工作者,具體取決於客戶的事件輸送量。
我們使用不同的端點支援各種應用程式:BigQuery 資料儲存、基於 HTTPS 的外部 SIEM 或內部端點、基於 Syslog 的 SIEM 以及 Google Cloud Storage 端點。我們的客戶和產品依賴這個資料平台來處理網路安全態勢和反應。我們的串流基礎架構非常靈活,可以透過串流作業訂閱新增、更新和刪除使用案例。例如,客戶想要將防火牆裝置的記錄事件擷取到 Kafka 主題中緩衝的資料湖中。串流作業會訂閱擷取和篩選資料、轉換資料格式,並即時執行串流插入到我們的 BigQuery 資料倉儲端點。客戶可以使用我們的視覺化和儀表板產品來檢視此防火牆擷取的流量或執行緒。下圖說明了事件產生者、使用案例訂閱工作流程以及串流平台的關鍵元件
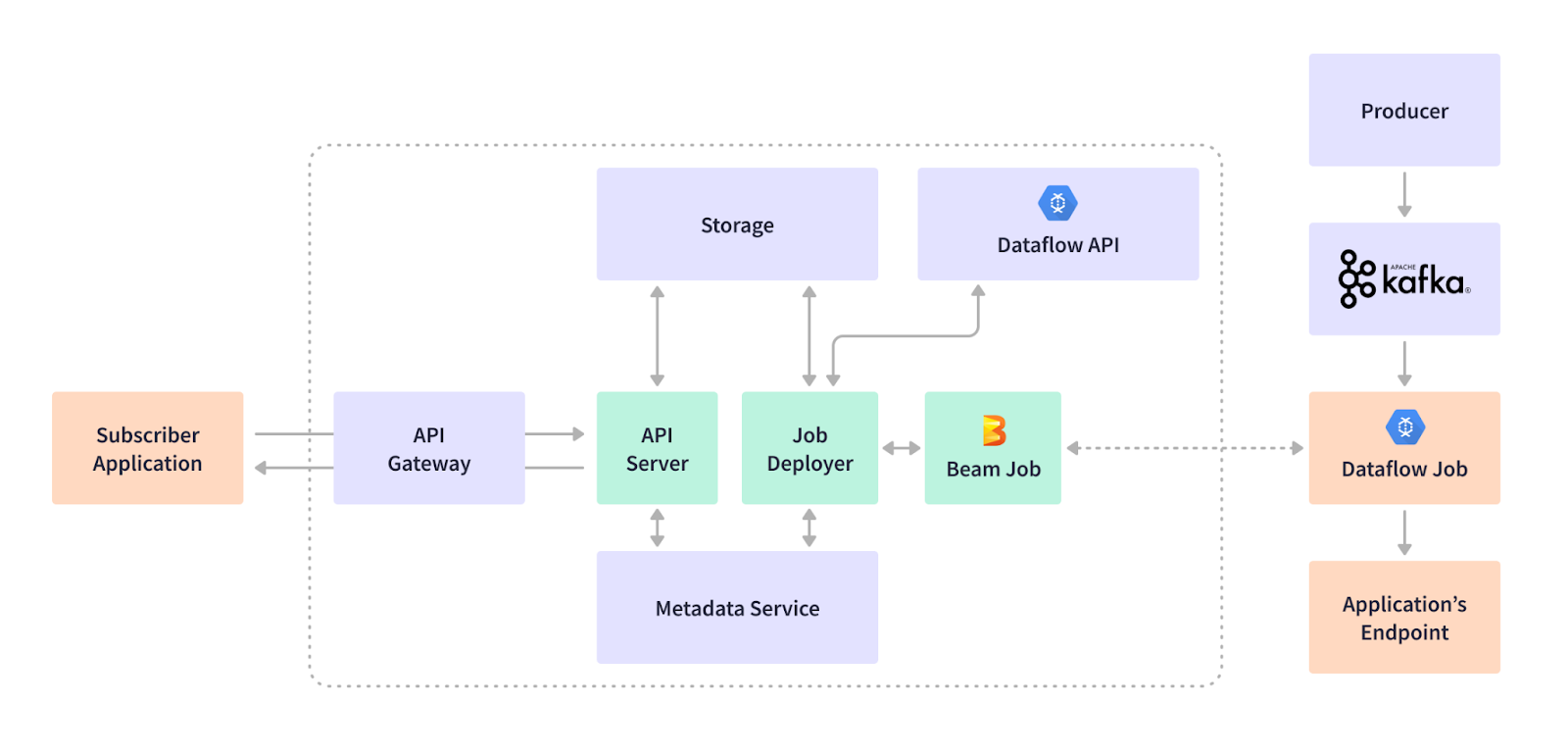
這種託管的基於 Dataflow 的串流基礎架構運行良好,但有一些注意事項
- 由於它是託管服務,因此成本很高。對於在 Dataflow 應用程式中使用的相同資源,例如 vCPU 和記憶體,成本比使用開放原始碼串流引擎(例如運行相同 Beam 應用程式碼的 Flink)要貴得多。
- 由於很難擴充功能,例如基於不同應用程式、端點或一個應用程式內的不同參數的自動調整,因此很難達成我們的延遲和 SLA 目標。
- 管線僅在 Google Cloud 上運行。
PANW 串流使用案例的獨特性是我們使用自我管理服務的另一個原因。我們支援多租戶。租戶(客戶)可以非常高的速率(>每秒 10 萬個請求)或非常低的速率(< 每秒 100 個請求)擷取資料。Dataflow 作業在 VM 而非 Kubernetes 上運行,需要至少一個 vCPU 核心。對於小型租戶,這會浪費資源。我們的串流基礎架構支援數千個作業,如果我們不必為一個作業使用一個核心,則 CPU 使用率會更高。我們自然會使用在 Kubernetes 上運行的串流引擎,以便我們可以為小型租戶分配最少的資源,例如,使用具有 ½ 或更少 vCPU 核心的 Google Kubernetes Engine (GKE) Pod。
選擇 Apache Flink 和 Kubernetes
為了處理已經陳述的問題並找到最有效率的解決方案,我們針對 Dataflow 評估了各種串流框架,包括 Apache Samza、Apache Flink 和 Apache Spark。
效能
- 一個值得注意的因素是 Apache Flink 的原生 Kubernetes 支援。與缺乏原生 Kubernetes 支援並需要 Apache Zookeeper 進行協調的 Samza 不同,Flink 與 Kubernetes 無縫整合。這種整合消除了不必要的複雜性。在效能方面,Samza 和 Flink 都是勢均力敵的競爭對手。
- Apache Spark 雖然很受歡迎,但在我們的測試中證明速度明顯較慢。在 Beam Summit 上的一場演講揭示,Apache Beam 的 Spark 執行器比原生 Apache Spark 慢約十倍 [3]。我們無法承受如此劇烈的效能下降。用原生 Spark 重寫我們整個 Beam 程式碼庫不是一個可行的選擇,特別是考慮到我們過去四年使用 Apache Beam 建構的廣泛程式碼庫。
社群
社群支援的健全性在我們的決策過程中扮演了關鍵角色。Dataflow 提供了出色的支援,但我們需要在選擇開放原始碼框架時獲得保證。Apache Flink 充滿活力的社群和多家公司的積極貢獻提供了無與倫比的信心。這種協作環境意味著錯誤識別和修復正在進行中。事實上,在我們的旅程中,我們使用了社群的許多 Flink 修復程式來修補我們的系統
- 我們透過合併 Flink 1.15 開放原始碼修復 FLINK-26063(我們正在使用 1.13)來修復 Google Cloud Storage 檔案讀取例外。
- 我們修復了 FLINK-31963 中狀態工作的工作者重新啟動的問題。
在我們的旅程中,我們還透過在開放原始碼中建立和修復錯誤來為社群做出貢獻。如需詳細資訊,請參閱 Flink Kubernetes Operator 的 FLINK-32700。我們還為 Kubernetes 用戶端建立了新的 GKE Auth 支援,並在 [4] 合併到 GitHub。
整合
Apache Flink 與 Kubernetes 的無縫整合為我們提供了一個靈活且可擴展的協調平台。Apache Flink 和 Kubernetes 之間的協同作用不僅優化了我們的資料處理工作流程,而且還使我們的系統具有面向未來的能力。
架構和部署工作流程
在即時資料處理和分析領域,Apache Flink 脫穎而出,成為一個強大且多功能的框架。當與業界標準的容器協調系統 Kubernetes 結合時,Flink 應用程式可以水平擴展並具有強大的管理能力。我們探索了一個尖端的設計,其中 Apache Flink 和 Kubernetes 在 Apache Flink Kubernetes Operator 的幫助下無縫協同工作。
Flink Kubernetes Operator 的核心是充當控制平面,反映了人工操作員管理 Flink 部署的知識和行動。與傳統方法不同,Operator 可以自動執行關鍵活動,從啟動和停止應用程式到處理升級和錯誤。其多功能功能集包括完全自動化的作業生命週期管理、對不同 Flink 版本的支援以及多種部署模式,例如應用程式叢集和工作階段作業。此外,Operator 的操作能力還擴展到度量、記錄,甚至使用 Job Autoscaler 進行動態調整。
建構無縫部署工作流程
想像一下一個健全的系統,其中 Flink 作業可以輕鬆部署、勤奮監控和主動管理。我們的團隊透過整合 Apache Flink、Apache Flink Kubernetes Operator 和 Kubernetes 來建立此工作流程。此設定的核心是我們自訂建構的 Apache Flink Kubernetes Operator 用戶端程式庫。此程式庫充當橋樑,可以執行啟動、停止、更新和取消 Flink 作業等原子操作。

部署流程
在我們的程式碼中,用戶端提供了 Apache Beam 管線選項,其中包括基本資訊,例如 Kubernetes 叢集的 API 端點、驗證詳細資訊、用於上傳 JAR 檔案的 Google Cloud/S3 暫存位置和工作者類型規格。Kubernetes Operator 程式庫使用此資訊來協調無縫部署流程。以下各節說明所採取的步驟。大多數核心步驟都在我們的程式碼庫中自動執行。
步驟 1
- 用戶端想要為客戶和特定應用程式啟動作業。
步驟 2
- 產生唯一作業 ID:程式庫會產生唯一的作業 ID,該 ID 會設定為 Kubernetes 標籤。此識別碼有助於追蹤和管理已部署的 Flink 作業。
- 組態和程式碼上傳:程式庫會將所有必要的組態和使用者程式碼上傳到 Google Cloud Storage 或 Amazon S3 上的指定位置。此步驟可確保 Flink 應用程式的資源可用於部署。
- YAML 承載產生:上傳過程完成後,程式庫會建構 YAML 承載。此承載包含重要的部署資訊,包括基於指定工作者類型的資源設定。
我們使用一個約定來命名我們的工作者 VM 執行個體類型。我們的約定與 Google Cloud 使用的命名約定相似。名稱 n1-standard-1 指的是特定的預先定義 VM 機類型。讓我們分解名稱的每個元件的含義
- n1 指示執行個體的 CPU 類型。在此例中,它指的是基於 N1 系列中執行個體的 Intel。Google Cloud 有多個世代的執行個體,具有不同的硬體和效能特性。
- standard 表示機器類型系列。標準機器類型為工作管理員提供 1 個虛擬 CPU (vCPU) 和 4 GB 記憶體的均衡比例,為工作管理員提供 0.5 個 vCPU 和 2 GB 記憶體。
- 1 表示執行個體中可用的 vCPU 數量。在 n1-standard-1 的情況下,這表示執行個體有 1 個 vCPU。
步驟 3
- 使用 Fabric8 呼叫 Kubernetes API:為了啟動部署,程式庫使用 Fabric8 與 Kubernetes API 互動。Fabric8 最初缺乏對 Google Kubernetes Engine 或 Amazon Elastic Kubernetes Service (EKS) 中驗證的支援。為了解決此限制,我們的團隊實作了必要的驗證支援,可以在我們 GitHub PR [4] 上的合併請求中找到。
步驟 4
- Flink Operator 部署:當接收到 YAML 酬載時,Flink Operator 會負責部署 Flink 工作的各種組件。任務包括佈建資源,以及管理 Flink Job Manager、Task Manager 和 Job Service 的部署。
步驟 5
- 工作提交和執行:當 Flink Job Manager 執行時,它會從指定的 Google Cloud Storage 或 S3 位置提取 JAR 檔案和設定。在所有必要的資源到位後,它會將 Flink 工作提交到獨立的 Flink 叢集以供執行。
步驟 6
- 持續監控:部署後,我們的 Operator 會持續監控執行中的 Flink 工作狀態。這種即時回饋迴路使我們能夠迅速解決發生的任何問題,確保我們的 Flink 應用程式的整體健康狀況和最佳效能。
總之,我們的部署流程利用 Apache Beam 管線選項,與 Kubernetes 和 Flink Operator 無縫整合,並採用自訂邏輯來處理組態上傳和身份驗證。這種端對端的工作流程確保 Flink 應用程式在 Kubernetes 叢集中可靠且高效地部署,同時保持警惕監控,以確保平穩運行。以下序列圖顯示了這些步驟。
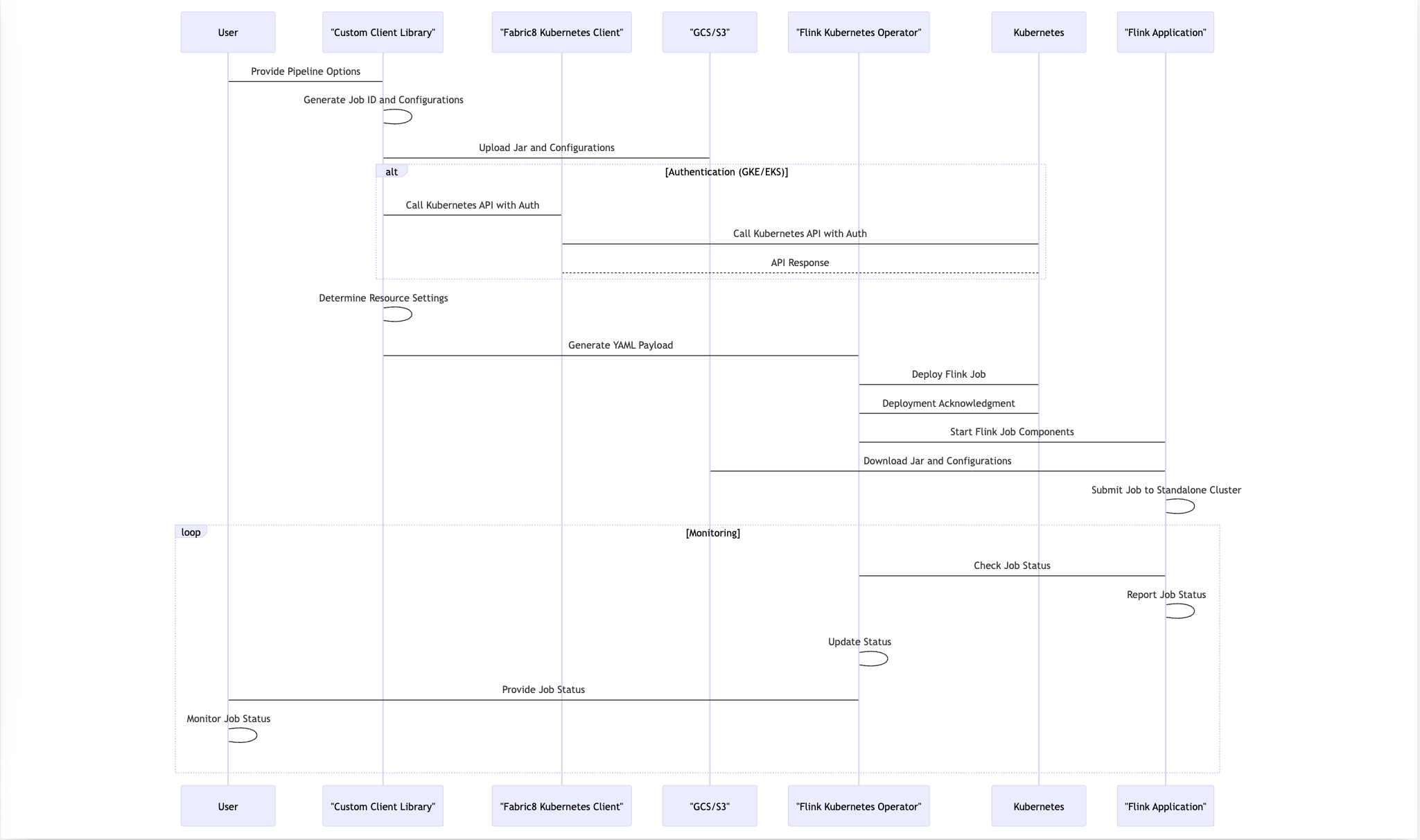
開發自動擴展器
擁有自動擴展器對於擁有自我管理的串流服務至關重要。網路上沒有足夠的資源供我們學習建立自己的自動擴展器,這使得工作流程的這部分變得困難。
自動擴展器會擴展任務管理器的數量,以減少延遲並跟上輸送量。它還會縮減處理傳入流量所需的最小資源數量,以降低成本。我們需要頻繁地執行此操作,同時將處理中斷降至最低。
我們廣泛地調整了自動擴展器,以滿足延遲的 SLA。這種調整涉及成本權衡。我們還使自動擴展器針對特定應用程式,以滿足某些應用程式的特定需求。每個決定都有隱藏的成本。本部落格的第二部分提供了有關自動擴展器的更多詳細資訊。
為串流工作開發建立用戶端程式庫
若要使用 Flink Kubernetes Operator 部署工作,您需要了解 Kubernetes 的運作方式。以下步驟說明如何建立單一 Flink 工作。
- 定義具有適當規格的 YAML 檔案。下圖提供了一個範例。
apiVersion: flink.apache.org/v1beta1
kind: FlinkDeployment
metadata:
name: basic-reactive-example
spec:
image: flink:1.13
flinkVersion: v1_13
flinkConfiguration:
scheduler-mode: REACTIVE
taskmanager.numberOfTaskSlots: "2"
state.savepoints.dir: file:///flink-data/savepoints
state.checkpoints.dir: file:///flink-data/checkpoints
high-availability: org.apache.flink.kubernetes.highavailability.KubernetesHaServicesFactory
high-availability.storageDir: file:///flink-data/ha
serviceAccount: flink
jobManager:
resource:
memory: "2048m"
cpu: 1
taskManager:
resource:
memory: "2048m"
cpu: 1
podTemplate:
spec:
containers:
- name: flink-main-container
volumeMounts:
- mountPath: /flink-data
name: flink-volume
volumes:
- name: flink-volume
hostPath:
# directory location on host
path: /tmp/flink
# this field is optional
type: Directory
job:
jarURI: local:///opt/flink/examples/streaming/StateMachineExample.jar
parallelism: 2
upgradeMode: savepoint
state: running
savepointTriggerNonce: 0
mode: standalone
- SSH 進入您的 Flink 叢集並執行下列命令
kubectl create -f job1.yaml
- 使用下列命令檢查工作的狀態
kubectl get flinkdeployment job1
此過程會影響我們的可擴展性。由於我們經常更新工作,因此我們無法針對每個執行中的工作手動執行這些步驟。這樣做會非常容易出錯且耗時。YAML 中一個錯誤的空格可能會導致部署失敗。此方法也成為創新的障礙,因為您需要了解 Kubernetes 才能與 Flink 工作互動。
我們建立了一個程式庫,為任何想要啟動、刪除、更新或取得其工作狀態的團隊和應用程式提供介面。
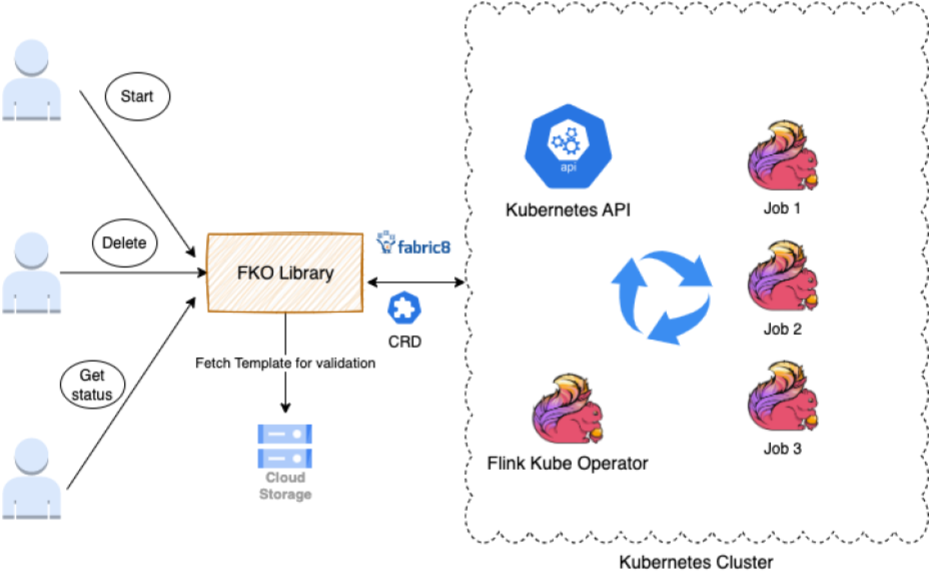
此程式庫擴充了 Fabric8 用戶端和 FlinkDeployment CRD。FlinkDeployment CRD 由 Flink Kubernetes Operator 公開。CRD 讓您可以儲存和擷取結構化資料。透過擴充 CRD,我們可以存取 POJO,從而更輕鬆地操作 YAML 檔案。
該程式庫支援下列任務
- 驗證身分,以確保您被允許在 Flink 叢集上執行操作。
- 驗證 (從 AWS/Google Cloud Storage 提取範本以進行驗證) 取得使用者變數輸入,並根據原則、規則、YAML 格式進行驗證。
- 動作執行會將 Java 呼叫轉換為調用 Kubernetes 操作。
在此過程中,我們學習到以下經驗教訓
- 應用程式特定 Operator 服務:在我們的大規模應用中,Operator 無法處理如此大量的工作。Kubernetes 呼叫開始逾時並失敗。為了解決此問題,我們在高流量區域建立了多個 Operator (約 4 個) 來處理每個應用程式。
- Kube 呼叫快取:為了防止超載,我們將 Kubernetes 呼叫的結果快取了 30 到 60 秒。
- 標籤支援:提供標籤支援以使用客戶端特定變數搜尋工作,減少了 Kube 的負載,並將工作搜尋速度提高了 5 倍。
以下是我們透過公開此程式庫所取得的一些最大勝利
- 標準化工作管理:使用者可以使用單一程式庫,在 Kubernetes 環境中啟動、刪除和取得其 Flink 工作狀態更新。
- 抽象化 Kubernetes 的複雜性:團隊不再需要擔心 Kubernetes 的內部運作方式或格式化工作部署 YAML 檔案。該程式庫會在內部處理這些詳細資訊。
- 簡化升級:透過底層 Kubernetes 基礎架構,該程式庫為 Flink 工作管理帶來穩健性和容錯能力,確保最短的停機時間和高效的復原。
可觀察性和警示
在大規模運行生產系統時,可觀察性非常重要。我們在 PANW 中有大約 30,000 個串流工作。每個工作都為特定應用程式的客戶提供服務。每個工作也會從 Kafka 中的多個主題讀取資料,執行轉換,然後將資料寫入各種接收器和端點。
約束可能會發生在管線或其端點的任何位置,例如客戶 API、BigQuery 等。我們希望確保串流的延遲符合 SLA。因此,了解工作是否正常、是否符合 SLA,並在需要時發出警示和介入,非常具有挑戰性。
為了實現我們的營運目標,我們建立了一個複雜的可觀察性和警示功能。我們提供三種可觀察性和偵錯工具,如下列各節所述。
來自 Prometheus 和 Grafana 的 Flink 工作清單和工作見解
每個 Flink 工作都會將各種指標傳送到我們的 Prometheus,其中包含基數詳細資訊,例如應用程式名稱、客戶 ID 和區域,以便我們可以查看每個工作。關鍵指標包括輸入流量速率、輸出輸送量、Kafka 中的回溯、基於時間戳記的延遲、任務 CPU 使用率、任務數量、OOM 計數等。
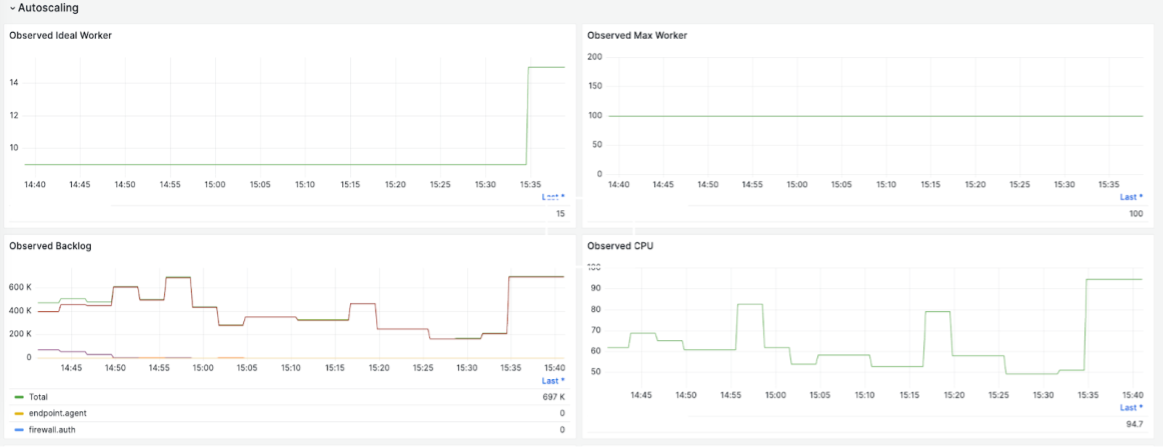
以下圖表提供了一些範例。這些圖表提供了有關特定客戶的 Kafka 攝取流量速率、串流工作的整體輸送量、每個 vCPU 的輸送量、Kafka 中的回溯以及根據觀察到的回溯進行的 Worker 自動擴展的詳細資訊。

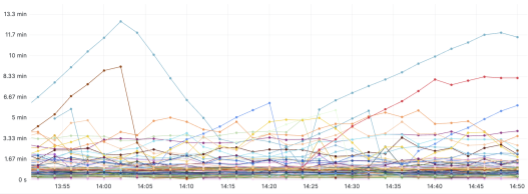
下圖顯示了基於時間戳記浮水印的串流延遲。除了 Kafka 中作為回溯的事件數量之外,了解端對端串流的時間延遲也很重要,以便我們可以定義和監控 SLA。延遲定義為從攝取時間戳記開始到將時間戳記傳送到串流端點的串流處理所花費的時間。浮水印是最後處理的事件時間。透過浮水印,我們正在追蹤 P100 延遲。我們追蹤每個事件的串流延遲,以便我們可以了解每個 Kafka 主題和分割區或 Flink 工作管線問題。以下範例顯示了每個事件串流及其延遲
Flink 開源 UI
我們使用並擴充 Apache Flink 儀表板 UI 來監控工作和任務,例如檢查點持續時間、大小和失敗。我們使用的一個重要擴充功能是工作歷史記錄頁面,該頁面可讓我們查看工作的啟動和更新時間軸以及詳細資訊,這有助於我們偵錯問題。

回溯和延遲的儀表板和警示
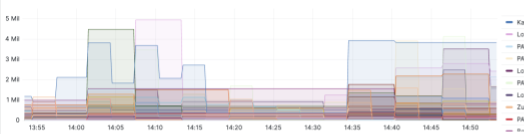
我們有大約 30,000 個工作,我們希望密切監控這些工作,並接收異常狀態工作的警示,以便我們可以介入。我們為每個應用程式建立了儀表板,以便我們可以顯示具有最高延遲的工作清單,並為警示建立閾值。以下範例顯示了一個應用程式的基於時間戳記的延遲儀表板。如果延遲大於閾值(例如 10 分鐘),並且持續一段時間,我們可以設定警示
以下範例顯示了更多基於回溯的儀表板
警示基於閾值,我們會頻繁檢查指標。如果達到閾值並持續一段時間,我們會發出警示到我們的內部 Slack 頻道或 PagerDuty,以便立即關注。我們調整了警示,以確保其準確性很高。
成本最佳化策略和調整
我們也轉向自我管理的串流服務,以提高成本效益。一些小的調整使我們能夠將成本降低一半,而且我們還有更多改進的機會。
以下清單包含一些對我們有幫助的提示
- 使用 Google Cloud Storage 作為檢查點儲存空間。
- 降低寫入 Google Cloud Storage 的頻率。
- 使用適當的機器類型。例如,在 Google Cloud 中,N2D 機器的價格比 N2 機器便宜 15%。
- 自動調整任務,以使用最佳資源,同時維持延遲 SLA。
以下各節提供有關前兩項提示的更多詳細資訊。
Google Cloud Storage 和檢查點
我們使用 Google Cloud Storage 作為我們的檢查點儲存,因為它具有成本效益、可擴展性和持久性。在使用 Google Cloud Storage 時,以下設計考量和最佳實務可以協助您最佳化擴展和效能
- 使用資料分割方法,例如範圍分割 (根據特定屬性分割資料) 和雜湊分割 (使用雜湊函式平均分配資料)。
- 避免循序鍵名稱,尤其是時間戳記,以避免熱點和不均勻的資料分配。相反地,為物件分配引入隨機字首。
- 使用階層式資料夾結構來改善資料管理,並減少單一目錄中的物件數量。
- 將小檔案合併為大檔案,以提高讀取輸送量。盡量減少小檔案的數量,可以減少低效率的儲存使用和中繼資料作業。
調整寫入 Google Cloud Storage 的頻率
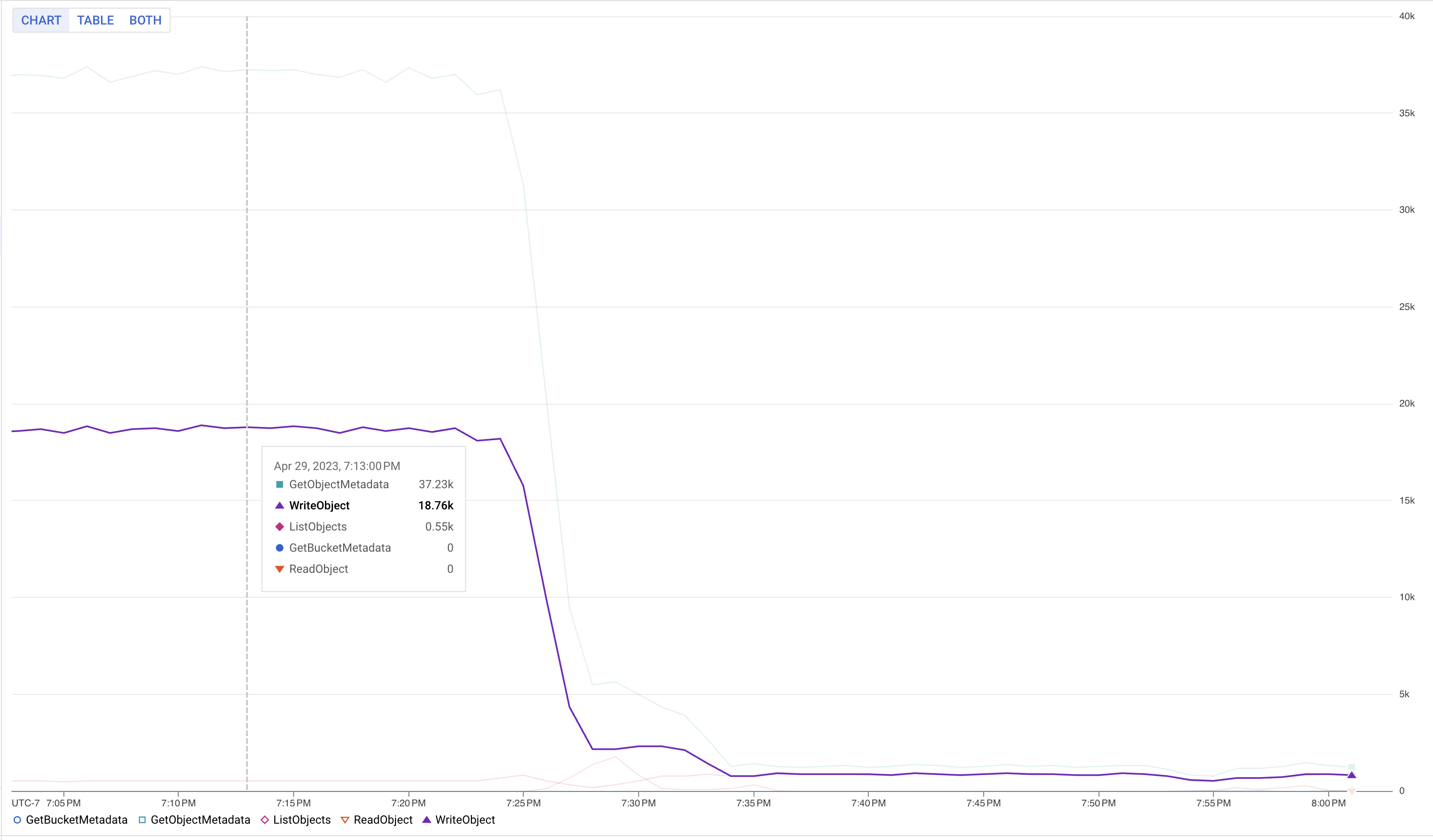
有效擴展工作是我們的主要挑戰之一。無狀態工作相對簡單,但仍存在障礙,尤其是在 Flink 需要處理大量 Worker 的情況下。為了解決這個挑戰,我們將 state.storage.fs.memory-threshold 設定從 20KB (??) 提高到 1 MB。此設定允許我們在 Job Manager 級別將小的檢查點檔案合併為大的檢查點檔案,並減少中繼資料呼叫。
優化 Google Cloud 運算效能是另一項挑戰。雖然 Google Cloud Storage 非常適合串流大量資料,但在處理高頻率 I/O 請求時仍有其限制。為了緩解這個問題,我們在金鑰名稱中加入了隨機前綴、避免使用連續的金鑰名稱,並優化了 Google Cloud Storage 的分片技術。這些方法顯著提升了 Google Cloud Storage 的效能,使我們的無狀態作業能順暢運行。
下圖顯示變更記憶體閾值後,Google Cloud Storage 寫入次數的減少情況
結論
Palo Alto Networks® Cortex Data Lake 已完全從 Dataflow 串流引擎遷移至 Flink 自我管理的串流引擎基礎架構。我們已達成目標,以更具成本效益的方式運行系統(成本降低超過一半),並在 GCP 和 AWS 等多個雲端上運行基礎架構。我們已學習如何基於開源技術建立大規模可靠的生產系統。由於我們擁有高度的自由來客製化開源程式碼和組態,我們看到根據我們特定需求客製化系統的巨大潛力。在接下來的第二部分文章中,我們將詳細介紹自動擴展和效能調校部分。我們希望我們的經驗對那些為自己的組織探索類似解決方案的讀者有所幫助。
額外資源
我們在此提供相關簡報的連結,供有興趣實作類似解決方案的讀者進一步閱讀。透過新增此章節,我們希望能幫助您找到更多關於建立完全託管的串流基礎架構的詳細資訊,讓讀者更容易了解我們的故事和學習歷程。
[1] PANW 在 Apache Beam 上發表的串流框架:https://beam.dev.org.tw/case-studies/paloalto/
[2] PANW 在 Beam Summit 2023 的簡報:https://youtu.be/IsGW8IU3NfA?feature=shared
[3] 在 Beam Summit 2021 上展示的基準測試:https://2021.beamsummit.org/sessions/tpc-ds-and-apache-beam/
[4] PANW 為 Flink 提供 GKE 驗證支援的開源貢獻:https://github.com/fabric8io/kubernetes-client/pull/4185
致謝
這是一個大規模的努力,旨在建立新的基礎架構,並將大量的客戶應用程式從雲端供應商管理的串流基礎架構遷移到大規模的自我管理 Flink 基礎架構。感謝 Palo Alto Networks CDL 串流團隊的協助,他們促成了這一切:Kishore Pola、Andrew Park、Hemant Kumar、Manan Mangal、Helen Jiang、Mandy Wang、Praveen Kumar Pasupuleti、JM Teo、Rishabh Kedia、Talat Uyarer、Naitk Dani 和 David He。